Author
Kai-Teh Tzeng - Lehigh UniversityAbstract
This study explores using Retrieval-Augmented Fine-Tuning (RAFT) to enhance English-Chinese bidirectional translation with Llama 3.1-8B. RAFT combines retrieval mechanisms with fine-tuning to provide contextual examples during training. Key Findings:- Benchmark fine-tuning achieved best overall results
- RAFT showed modest improvements on specific metrics
- Random-based RAFT sometimes outperformed similarity-based RAFT
- Translation quality depends heavily on training data relevance
1. Introduction
Background
Large Language Models excel at language tasks but can benefit from domain-specific optimization. This research explores whether RAFT—a technique that augments training with retrieved examples—can improve translation quality.Research Questions
- Can RAFT improve translation compared to standard fine-tuning?
- Does similarity-based retrieval outperform random retrieval?
- How do different RAFT configurations affect bidirectional translation?
2. Methodology
RAFT Overview
RAFT (Retrieval-Augmented Fine-Tuning) enhances the training process by:- Retrieving relevant examples from a corpus for each training sample
- Augmenting the training context with retrieved examples
- Fine-tuning the model with this enriched context
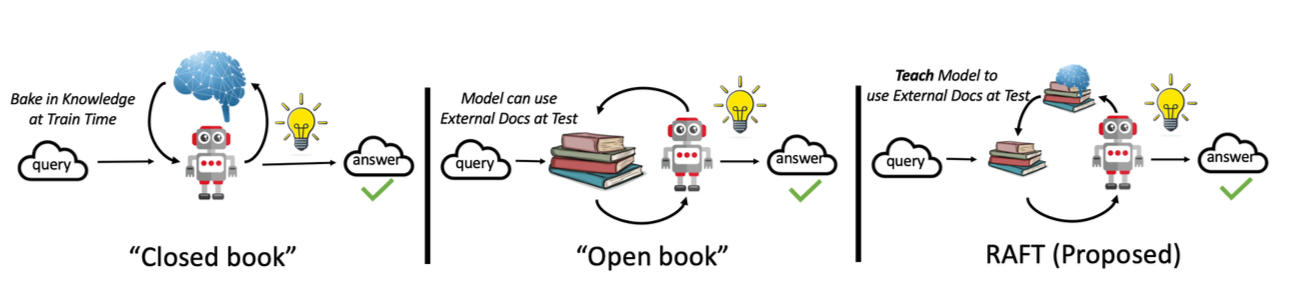
RAFT methodology diagram
Experimental Setup
| Component | Configuration |
|---|---|
| Base Model | Llama 3.1-8B Instruct |
| Fine-tuning | LoRA (r=16, alpha=16) |
| Dataset | News Commentary v18.1 (zh-en) |
| GPU | NVIDIA A100 80GB |
Dataset Preparation
The News Commentary dataset contains parallel English-Chinese sentence pairs:- Training: 10,000 sentence pairs
- Evaluation: TED Talks corpus
- Preprocessed for quality and length consistency
RAFT Configurations
| Configuration | Description |
|---|---|
| Benchmark | Standard fine-tuning without retrieval |
| Similarity RAFT | Retrieve top-k similar examples using embeddings |
| Random RAFT | Randomly sample k examples from corpus |
3. Results
English-to-Chinese Translation
| Method | BLEU | COMET |
|---|---|---|
| Baseline (No Fine-tuning) | 15.2 | 0.785 |
| Benchmark Fine-tuning | 28.4 | 0.856 |
| Similarity RAFT (k=3) | 27.1 | 0.849 |
| Random RAFT (k=3) | 27.8 | 0.852 |
Chinese-to-English Translation
| Method | BLEU | COMET |
|---|---|---|
| Baseline (No Fine-tuning) | 18.7 | 0.812 |
| Benchmark Fine-tuning | 31.2 | 0.871 |
| Similarity RAFT (k=3) | 30.5 | 0.865 |
| Random RAFT (k=3) | 30.9 | 0.868 |
Benchmark fine-tuning consistently outperformed RAFT configurations in this experiment. This may be due to the homogeneous nature of the News Commentary dataset.
Training performance comparison
BLEU and COMET score comparison
Analysis
Why RAFT didn’t outperform benchmark:- Dataset Homogeneity: News Commentary has consistent style
- Retrieval Quality: Similarity metrics may not capture translation-relevant features
- Context Length: Additional examples increase context, potentially diluting focus
4. Conclusion
While RAFT shows promise, our experiments suggest that for translation tasks on homogeneous datasets, standard fine-tuning remains competitive. Future work should explore diverse training corpora and better retrieval metrics.References
- Zhang, T., et al. (2024). “RAFT: Adapting Language Model to Domain Specific RAG.”
- Lewis, P., et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”