1. Introduction
Large language models (LLMs) have shown impressive proficiency in downstream tasks through conditioning on input-label pairs. This inference mode is called in-context learning (Brown et al. 2020). GPT-4 can improve its translation capabilities without fine-tuning by providing specific task examples.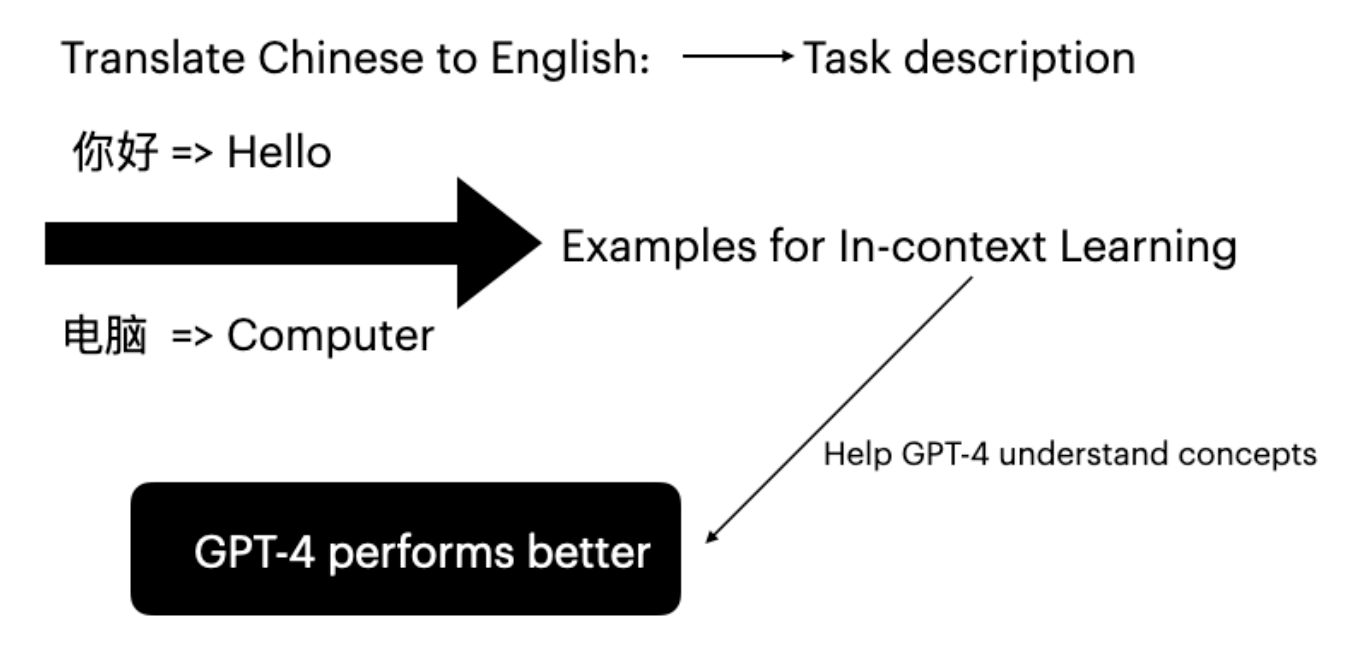
Figure 1: In-context learning for Chinese to English translation using few-shot examples
2. Proposed Method
This methodology assumes access to a dataset Ds containing translation pairs. A text retriever (Gao 2023) locates and selects the top K sentences with similar meaning to the user prompt. The retriever has two components:- TF-IDF Matrix - measures term frequency and inverse document frequency
- Cosine Similarity - measures similarity between TF-IDF vectors
TF-IDF Score
TF-IDF scores measure the significance of words within documents:- TF (Term Frequency): How often a word appears in a document
- IDF (Inverse Document Frequency): Significance of a word across the corpus
Cosine Similarity
Cosine similarity assesses similarity between two vectors by considering the angle between their representations. Higher scores indicate greater similarity between the user prompt and dataset documents.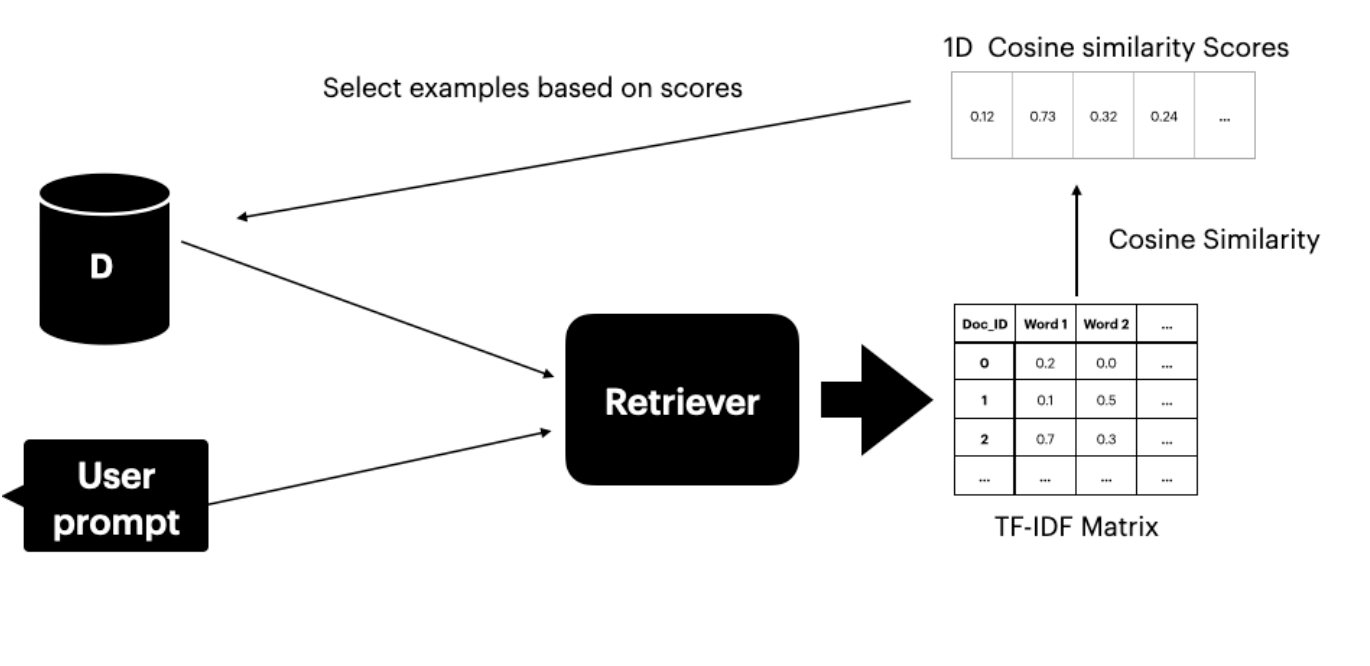
Figure 2: Using TF-IDF matrix and cosine similarity to select top-K examples from the dataset
3. Experimental Setup
3.1 Experimental Procedure
The experiment covers three scenarios:- No ICL: GPT-4 translation without in-context learning examples
- Random ICL: Random selection of translation examples
- Proposed Method: TF-IDF retriever selects top 4 examples based on similarity scores
Evaluation Metrics
- BLEU Score: Compares translated segments with reference translations (Papineni et al. 2002)
- COMET Score: Neural framework for multilingual MT evaluation achieving state-of-the-art correlation with human judgments (Rei et al. 2020)
3.2 Datasets
OPUS-100 (Zhang et al. 2020) was chosen because it:- Contains diverse translation language pairs (ZH-EN, JA-EN, VI-EN)
- Covers diverse domains for effective example selection
- 10,000 training instances per language pair for Ds
- First 100 sentences from test set for evaluation
3.3 Implementation
Using scikit-learn’sTfidfVectorizer and cosine_similarity functions:
- Merge user prompt with Ds
- Calculate cosine similarity scores between prompt and all sentences
- Select top 4 examples based on similarity
- Embed examples into GPT-4 prompt

Figure 3: Final prompt with four examples identified by the retriever
4. Results and Discussion
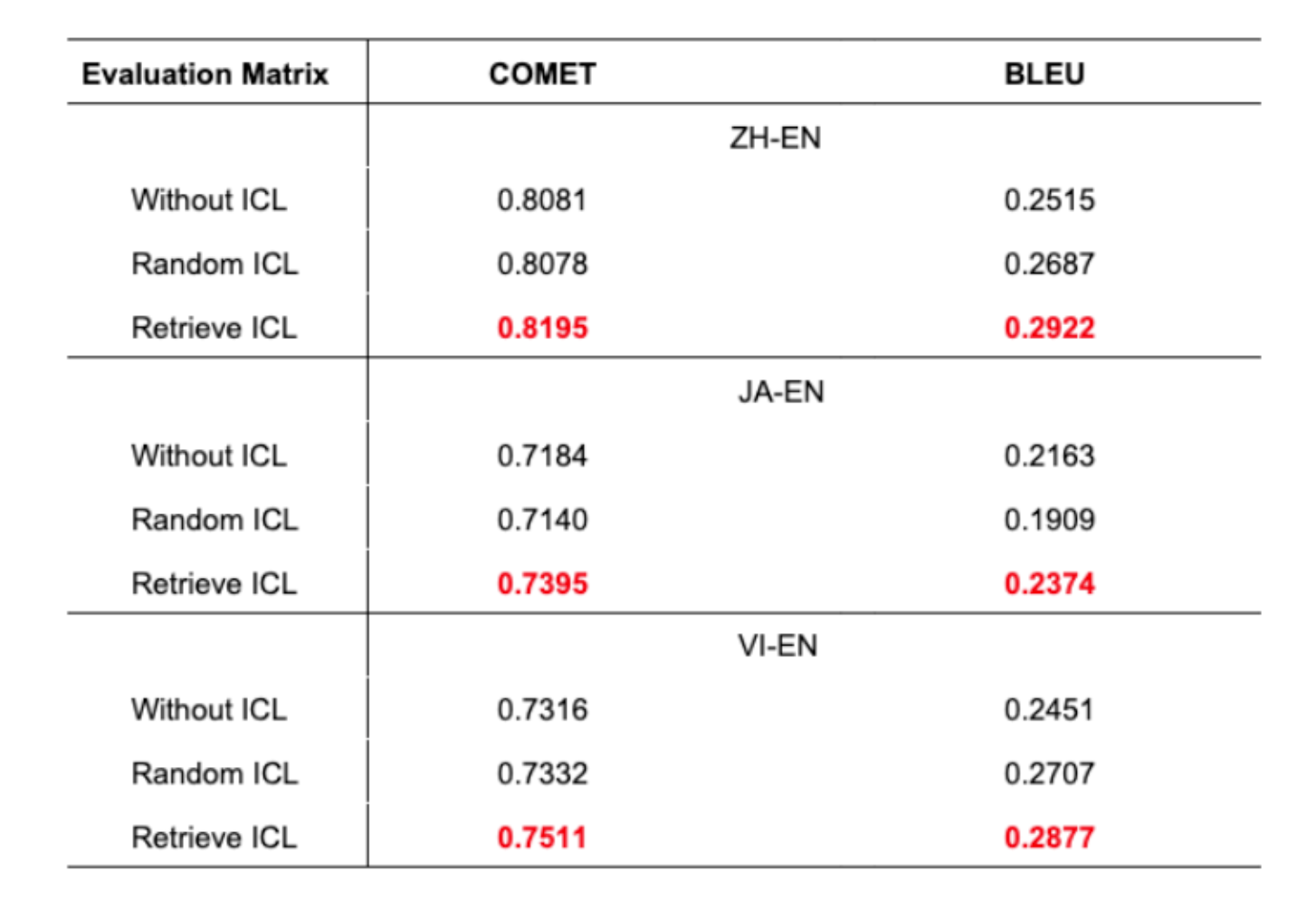
Table 1: Translation accuracy across three scenarios for all language pairs
- The proposed approach shows superior translation accuracy across all language pairs
- A 1% improvement in BLEU score is significant in machine translation
- Random ICL sometimes performs worse than no ICL at all
- This highlights the importance of judicious example selection
Dataset Size Impact

Table 2: Translation accuracy with different dataset sizes
5. Conclusion and Next Steps
This paper introduces a method to enhance GPT-4 translation through in-context learning with TF-IDF retrieval. The approach:- Constructs a retriever using TF-IDF matrix and cosine similarity
- Selects sentences that closely align with user prompts
- Shows improvements in both BLEU and COMET scores
- Dataset Construction: Creating comprehensive, high-quality translation datasets across domains
- Example Quantity: Investigating impact of using 5 or 10 examples instead of 4
6. References
- Brown, T., et al. (2020). “Language models are few-shot learners.”
- Xie, S. M., et al. (2022). “An Explanation of In-context Learning as Implicit Bayesian Inference.”
- Bashir, D. (2023). “In-Context Learning, in Context.” The Gradient.
- Das, R., et al. (2021). “Case-based reasoning for natural language queries over knowledge bases.”
- Liu, J., et al. (2022). “What makes good in-context examples for GPT-3?”
- Margatina, K., et al. (2023). “Active learning principles for in-context learning with large language models.”
- Gao, L., et al. (2023). “Ambiguity-Aware In-Context Learning with Large Language Models.”
- Papineni, K., et al. (2002). “BLEU: A method for automatic evaluation of machine translation.”
- Rei, R., et al. (2020). “COMET: A Neural Framework for MT Evaluation.”
- Zhang, B., et al. (2020). “Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation.”