Author
Boxuan Lyu - Tokyo Institute of TechnologyAbstract
This research presents the development of a fast and natural Text-to-Speech (TTS) system for Mandarin Chinese using the Bert-VITS2 framework. The system is specifically tailored for meeting scenarios, generating clear, expressive, and context-appropriate speech. Key Results:- Achieved WER of 0.27 (lowest among compared models)
- Achieved MOS of 2.90 for speech naturalness
- Successfully synthesized speech up to 22 seconds
- Trained on AISHELL-3 dataset (85 hours, 218 speakers)
1. Introduction
What is Text-to-Speech?
Text-to-Speech (TTS) technology converts written text into natural-sounding speech. Modern TTS systems leverage deep learning to generate increasingly natural and expressive speech, with applications in:
- Intelligent assistants
- Accessible reading solutions
- Navigation systems
- Automated customer service
Why Mandarin?
Mandarin Chinese is the most widely spoken language with over a billion speakers. However, it presents unique challenges for TTS due to its tonal nature and complex linguistic structure.What is Bert-VITS2?
Bert-VITS2 combines pre-trained language models with advanced voice synthesis:- BERT integration: Deep understanding of semantic and contextual nuances
- GAN-style training: Produces highly realistic speech through adversarial learning
- Based on VITS2: State-of-the-art voice synthesis architecture
2. Methodology
2.1 Dataset Selection
AISHELL-3 was selected for this study:- 85 hours of audio
- 218 speakers
- ~30 minutes per speaker average
- High transcription quality
Initial experiments with Alimeeting (118.75 hours) resulted in blank audio generation due to poor transcription quality and low per-speaker duration.
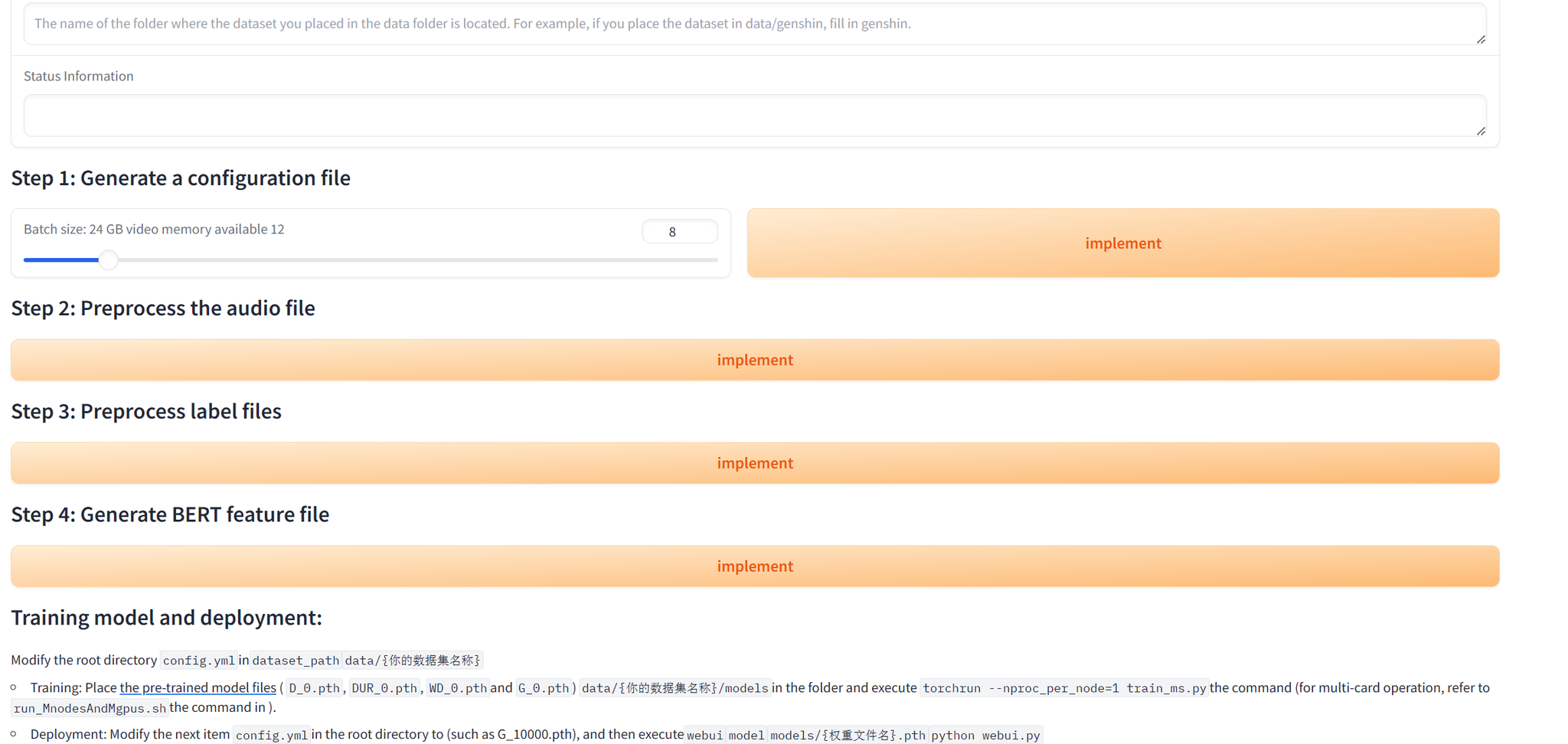
Data preprocessing webui interface
2.2 Model Architecture
The Bert-VITS2 framework consists of four main components:| Component | Function |
|---|---|
| TextEncoder | Processes input text with pre-trained BERT for semantic understanding |
| DurationPredictor | Estimates phoneme durations with stochastic variations |
| Flow | Models pitch and energy using normalizing flows |
| Decoder | Synthesizes final speech waveform |
2.3 Training Process
Loss Functions
- Reconstruction Loss: Matches generated speech to ground truth
- Duration Loss: Minimizes phoneme duration prediction error
- Adversarial Loss: Encourages realistic speech generation
- Feature Matching Loss: Aligns intermediate features
Mode Collapse Mitigation
- Gradient Penalty for discriminator stability
- Spectral Normalization in generator and discriminator
- Progressive Training with increasing complexity
Hyperparameters
3. Results and Discussion
Training Dynamics
Initial training showed mode collapse (generating blank speech). After refinement:- Discriminator loss stabilized
- Generator loss showed clear downward trend
- WER dropped from ~0.5 to ~0.2 during training
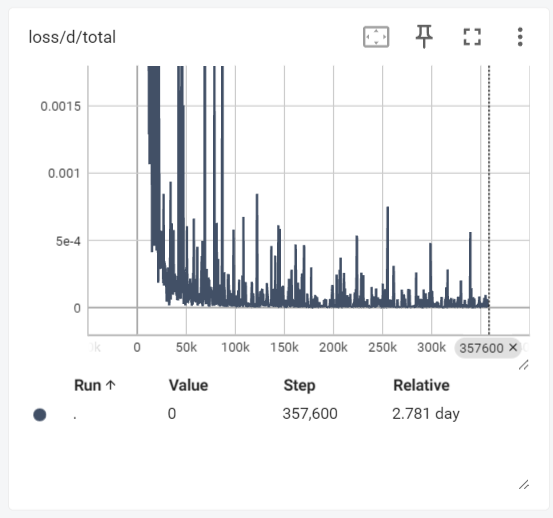
Training loss curves
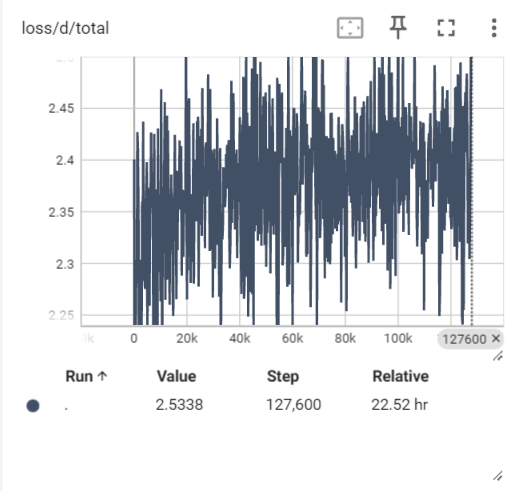
WER improvement during training
Comparison with Other Models
| Model | WER | MOS |
|---|---|---|
| Ours (Bert-VITS2) | 0.27 | 2.90 |
| myshell-ai/MeloTTS-Chinese | 5.62 | 3.04 |
| fish-speech (GPT) w/o ref | 0.49 | 3.57 |
Our model achieved the lowest WER, indicating accurate speech generation. However, MOS (naturalness) has room for improvement compared to fish-speech, which has significantly more parameters.
Generation Examples
Successfully synthesized examples including:- Short phrases (2-10 seconds)
- Long-form speech (22 seconds) - outside training data scope
Limitations
Code-switching: The model cannot handle text with mixed languages (e.g., Chinese with English terms like “Speech processing”).4. Conclusions and Future Work
Achievements
- Successfully fine-tuned Bert-VITS2 for Mandarin TTS
- Achieved lowest WER among compared models
- Mastered methodology to mitigate GAN training challenges
- Generated clear, recognizable speech across various durations
Future Directions
- Train more steps to improve MOS scores
- Address code-switching limitations
- Expand to additional speakers and domains
5. References
- Ren, Y., et al. (2019). “Fastspeech: Fast, robust and controllable text to speech.” NeurIPS.
- Wang, Y., et al. (2017). “Tacotron: Towards end-to-end speech synthesis.” Interspeech.
- Kim, J., et al. (2021). “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.” ICML.
- Kong, J., et al. (2023). “VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech.” INTERSPEECH.
- Shi, Y., et al. (2020). “AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines.” ArXiv.
- Saeki, T., et al. (2022). “UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022.” INTERSPEECH.
Resources
- Bert-VITS2 Repository: github.com/fishaudio/Bert-VITS2
- AISHELL-3 Dataset: openslr.org/93