Author
Chen Yufeng - Waseda UniversityAbstract
We are addressing the challenge of accurately assessing machine translation quality while also striving to enhance its accuracy to a level comparable to human translation. Our approach involves employing five distinct benchmark translation models and evaluating their performance using three diverse evaluation metrics. Concurrently, we are dedicated to refining the accuracy of these models through insights gained from prior research and studies.Table of Contents
- Introduction
- Dataset
- How To Evaluate Machine Translation Accuracy
- 3.1. BLEU Score
- 3.2. BLEURT Score
- 3.3. COMET Score
- Five Basic Machine Translation Models And Their Accuracies
- 4.1. Azure Baseline Model
- 4.2. Azure Custom Model
- 4.3. DeepL Model
- 4.4. Google Translator
- 4.5. GPT-4 Model
- 4.6. Comparison And Conclusion
- Improve Machine Translation Accuracy
- 5.1. In-Context Learning for GPT-4
- 5.2. Hybrid Model
- 5.3. GPT-4 as a Data Cleaning Tool
- Conclusion
- References
1. Introduction
With the advancement of AI technology, particularly following the inception of ChatGPT by OpenAI, people are increasingly placing greater trust in the AI industry. As a pivotal component within the realm of natural language processing, machine translation has garnered ever-growing significance. This paper focuses on the evaluation of five fundamental translation models using diverse evaluation metrics, while also delving into methods to enhance the precision of these models to the fullest extent possible.2. Dataset
The research is centered around the Opus100 (ZH-EN) dataset available on Hugging Face. This dataset comprises one million Chinese-to-English translation instances spanning various domains, rendering Opus100 a fitting choice for training translation models.
It is imperative to acknowledge the presence of translation inaccuracies within the dataset. While these inaccuracies may ostensibly reduce training accuracy, they concurrently serve as a deterrent against potential overfitting issues.
3. How To Evaluate Machine Translation Accuracy
When faced with a multitude of translation models, selecting the most suitable one for a specific purpose becomes challenging. There exist two fundamental approaches for assessing translation models:- Traditional method: BLEU score
- Neural metrics: BLEURT score and COMET score
3.1 BLEU Score
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another (Papineni et al., 2002).Seven Smoothing Functions
| Function | Description |
|---|---|
| Smoothing Function 1 | Additive (Laplace) Smoothing - adds constant value to prevent zero probabilities |
| Smoothing Function 2 | NIST Smoothing - introduces reference length penalty |
| Smoothing Function 3 | Chen and Cherry - adapts based on candidate translation length |
| Smoothing Function 4 | JenLin - balances additive and adjusted methods |
| Smoothing Function 5 | Gao and He - addresses bias towards shorter translations |
| Smoothing Function 6 | Bayesian - provides robust estimation for longer sentences |
| Smoothing Function 7 | Geometric Mean - calculates geometric mean of n-gram precisions |
3.2 BLEURT Score
BLEURT is an evaluation metric for Natural Language Generation. It takes a pair of sentences as input (reference and candidate) and returns a score indicating fluency and meaning preservation (Sellam, 2021).3.3 COMET Score
COMET is a neural framework for training multilingual machine translation evaluation models, designed to predict human judgments of translation quality.4. Five Basic Machine Translation Models And Their Accuracies
4.1 Azure Baseline Model
4.2 Azure Custom Model
The Azure custom model is an enhanced version achieved through utilizing additional datasets to further train the Azure baseline model. The custom model’s BLEU score on the Azure platform is 39.45.When working with the custom model, it must be published on the Azure platform to be invoked when the API is called.
4.3 DeepL Model
DeepL Translator is a neural machine translation service using convolutional neural networks and an English pivot.4.4 Google Translator
4.5 GPT-4 Model
4.6 Comparison And Conclusion
Based on the evaluation results: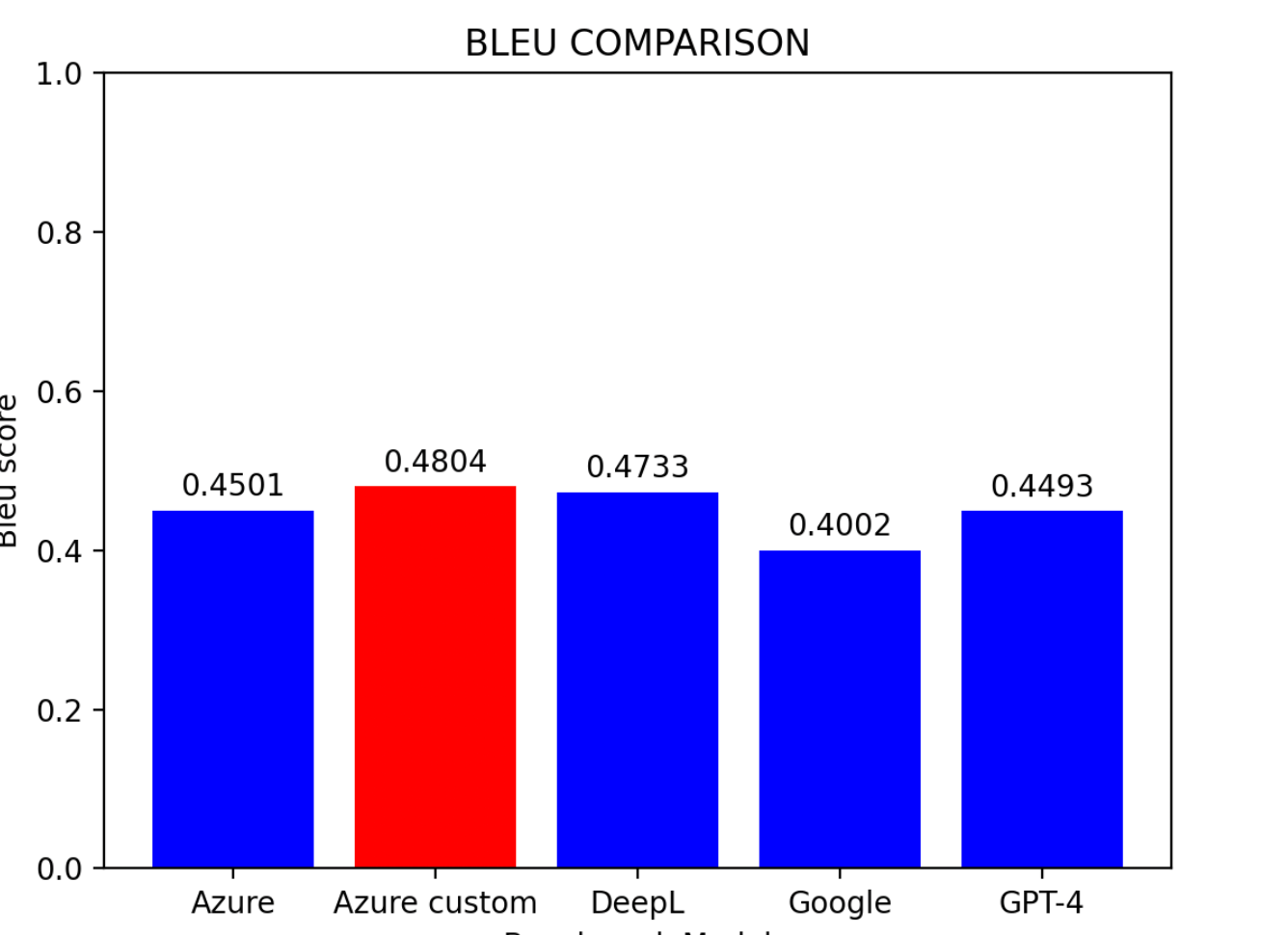
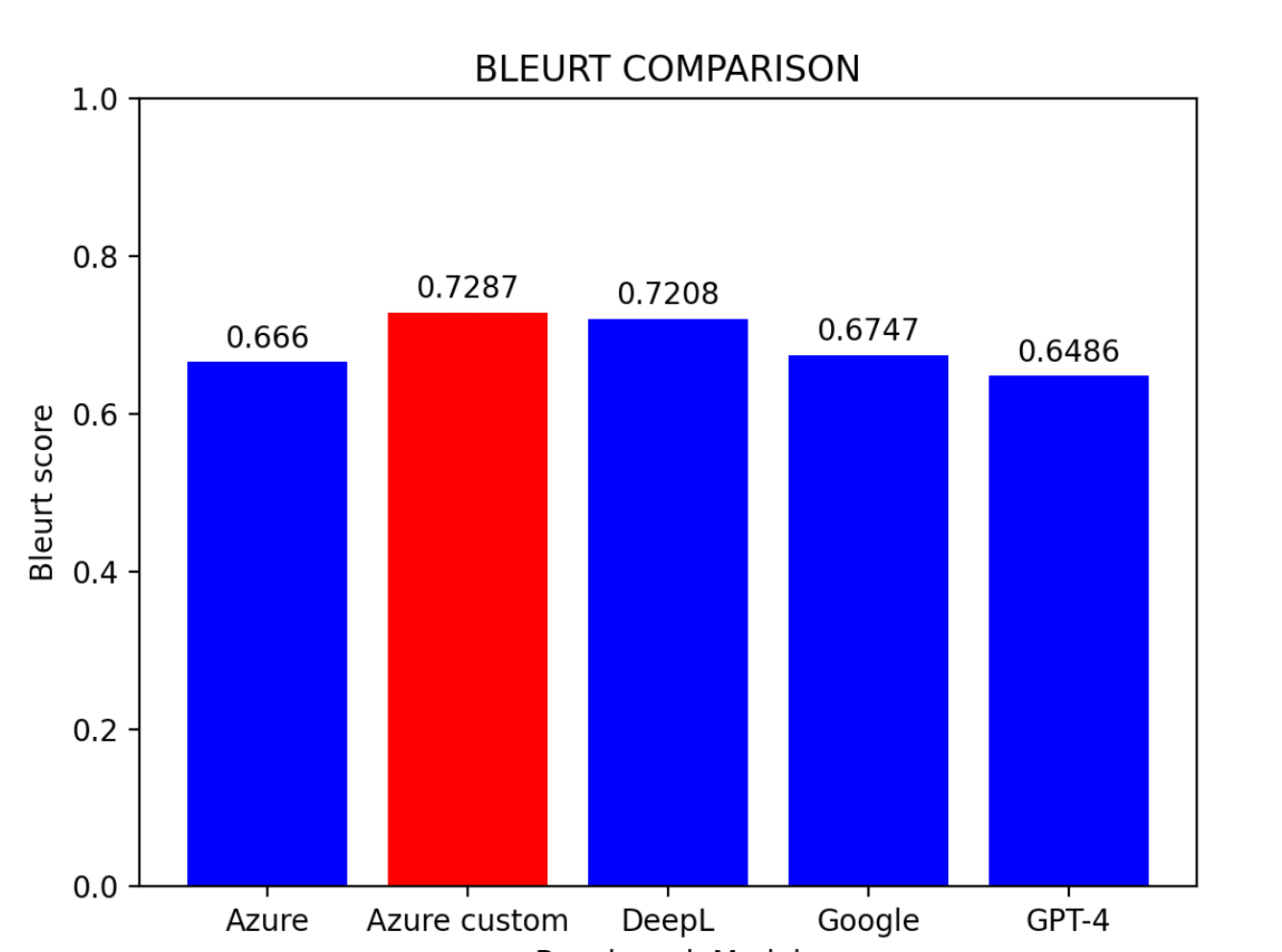
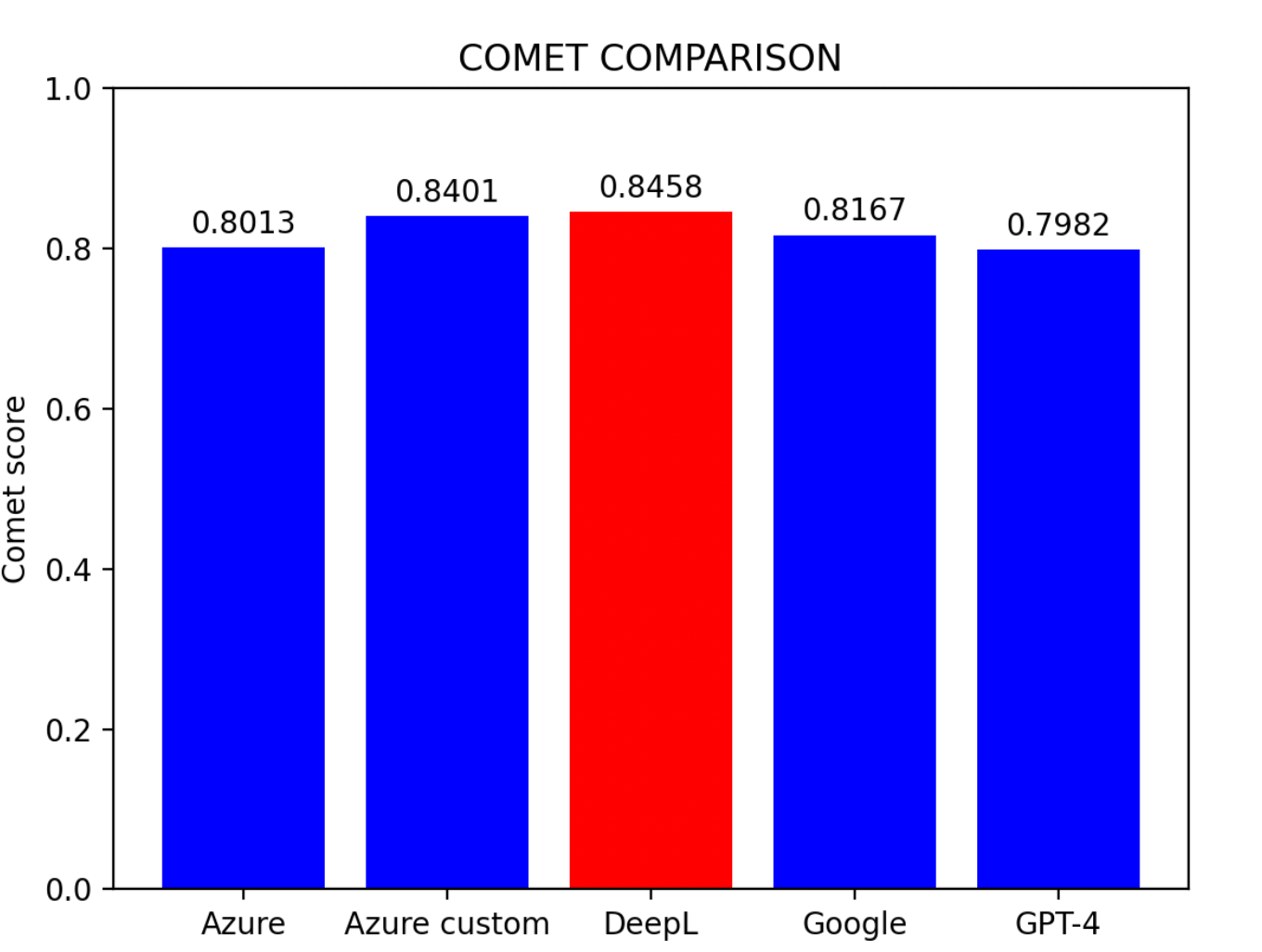
- Azure Custom Model emerges as the top performer
- DeepL follows closely in second place
- Azure Baseline Model claims the third spot
- Google Translator and GPT-4 share similar standings
5. Improve Machine Translation Accuracy
Three distinct approaches for improving translation accuracy:5.1 In-Context Learning for GPT-4
Large language models can improve performance through in-context learning by providing specific task examples in prompts (Brown et al., 2020). Result: The BLEURT score was increased from 0.6486 to 0.6755, demonstrating the effectiveness of in-context learning.5.2 Hybrid Model
The hybrid threshold model establishes a specific threshold, and different models are used to retranslate when certain sentences fail to meet the threshold.Conclusions of Hybrid Model
- The optimal threshold aligns with the COMET score
- Best performance comes from Azure Custom + DeepL or DeepL + GPT-4
- Nearly all hybrid models surpass individual models
- A higher threshold does not necessarily guarantee improved scores
5.3 GPT-4 as a Data Cleaning Tool
GPT-4 can be used to preprocess datasets and correct inaccurate translations:6. Conclusion
This paper investigated machine translation accuracy and methods for enhancement through three evaluation metrics and five benchmark models. Key Conclusions:- DeepL is the most proficient Chinese to English translator
- Azure Baseline Model can achieve higher performance with substantial data and adequate training
- Hybrid models combining different translation engines improve accuracy
- GPT-4 data cleaning improves dataset quality, leading to better model performance
7. References
- Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002). BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (ACL).
- Thibault Sellam (2021). BLEURT
- Tom Brown et al. (2020). Language models are few-shot learners.
- Daniel Bashir (2023). In-Context Learning, in Context. The Gradient.
- Amr Hendy et al. (2023). How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation. Microsoft.
- Ricardo Rei (2022). COMET