Penulis
Ashar Mirza - VoicePing Inc.Rekap: Masalah
Dalam Bahagian 1, kami mengenal pasti bottleneck: perkhidmatan FastAPI kami menggunakan pekerja multiprocessing dengan baris gilir IPC untuk mengagihkan tugas terjemahan. Ini mewujudkan:- Overhead serialisasi baris gilir
- Pertembungan pengiraan GPU antara proses pekerja
- Corak penggunaan GPU tersentak
Percubaan 2: Batching Statik
Kami melaksanakan batching statik dalam proses pekerja sedia ada.Pelaksanaan
- Saiz batch: 16 permintaan
- Timeout: 50ms (jangan tunggu tanpa had untuk batch penuh)
- vLLM memproses berbilang urutan bersama-sama
- Masih menggunakan pekerja multiprocessing
Keputusan
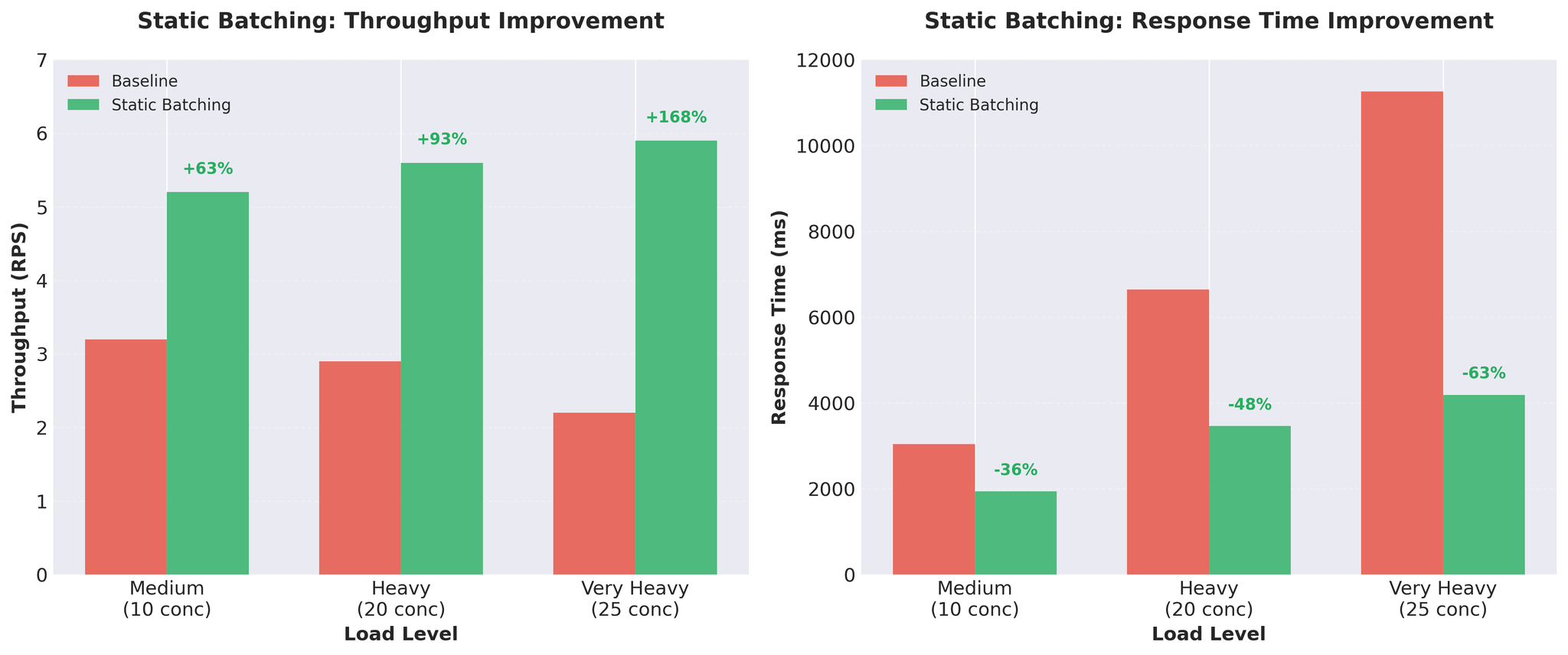
Rajah 1: Batching statik memberikan peningkatan throughput dan masa respons yang ketara
Pertukaran
Kelebihan:- Peningkatan throughput besar
- GPU digunakan dengan lebih baik
- Pelaksanaan mudah
- Penyekatan head-of-line: Semua permintaan menunggu yang paling perlahan
- Dengan input panjang berubah-ubah, terjemahan pendek menunggu yang panjang
- Contoh: [50 token, 50 token, 200 token] - dua pertama menunggu terjemahan 200-token
Percubaan 3: Continuous Batching
Penyelesaian: AsyncLLMEngine vLLM dengan continuous batching.Apakah Continuous Batching?
Tidak seperti batching statik, continuous batching menyusun batch secara dinamik:- Permintaan baharu menyertai pertengahan penjanaan
- Permintaan selesai keluar segera (tidak menunggu yang lain)
- Komposisi batch dikemas kini setiap token
- AsyncLLMEngine vLLM mengendalikan ini secara automatik
Pelaksanaan
- AsyncLLMEngine digunakan terus dalam FastAPI
- vLLM mengendalikan batching secara dalaman melalui enjin continuous batching
- Async/await tulen sepanjang masa
Semakan Realiti Ujian
Keputusan Awal (Input Seragam)
Kami menguji dengan input panjang standard seragam (panjang serupa):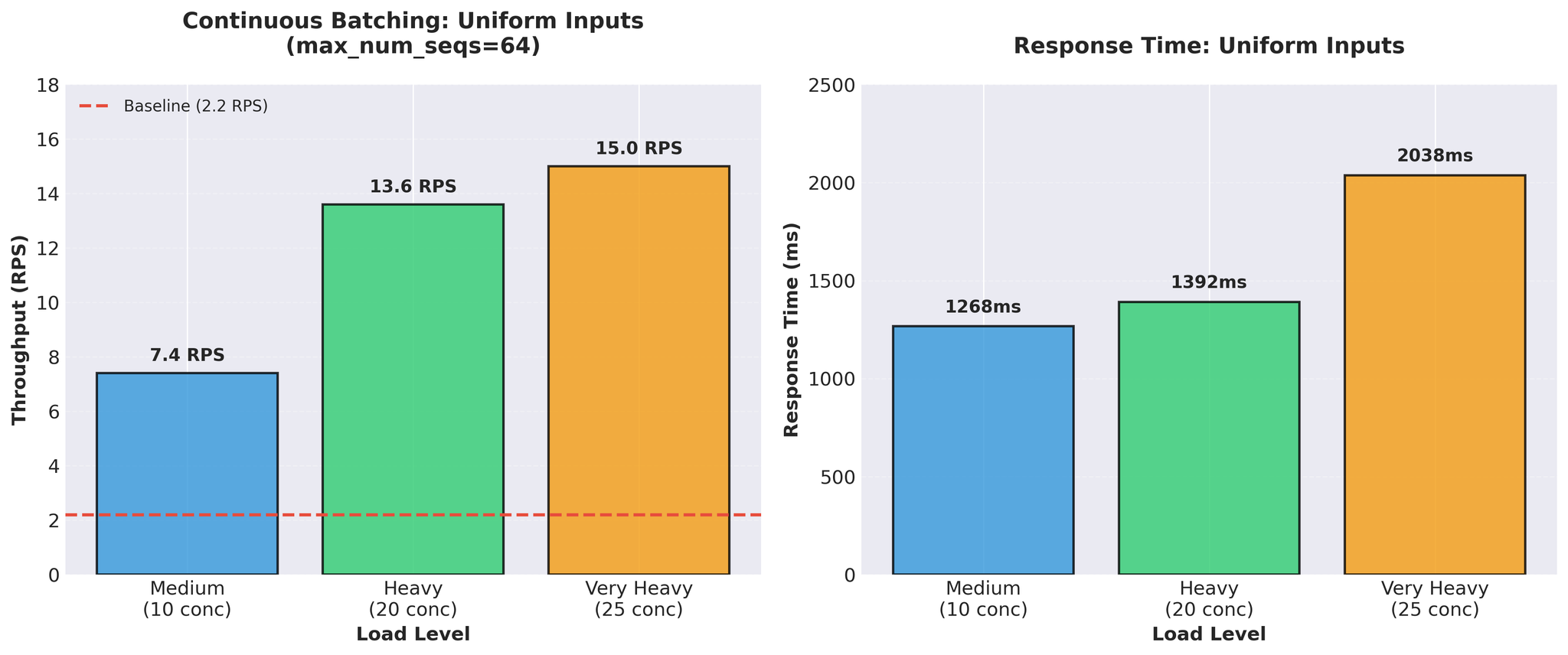
Rajah 2: Continuous batching dengan input seragam menunjukkan throughput 15 RPS yang mengagumkan
Input Panjang Berubah-ubah (Realiti)
Kemudian kami menguji dengan input panjang berubah-ubah yang realistik (10-200 token, campuran pendek dan panjang): Jalankan semula garis dasar dengan input berubah-ubah:- Beban sangat berat: 1.1 RPS (vs 2.2 RPS dengan seragam)
- Malah garis dasar berprestasi lebih teruk dengan data realistik
- Beban sangat berat: 3.5 RPS (dengan penalaan max_num_seqs=16)
- Konfigurasi yang sama yang memberikan kami 15 RPS dengan input seragam
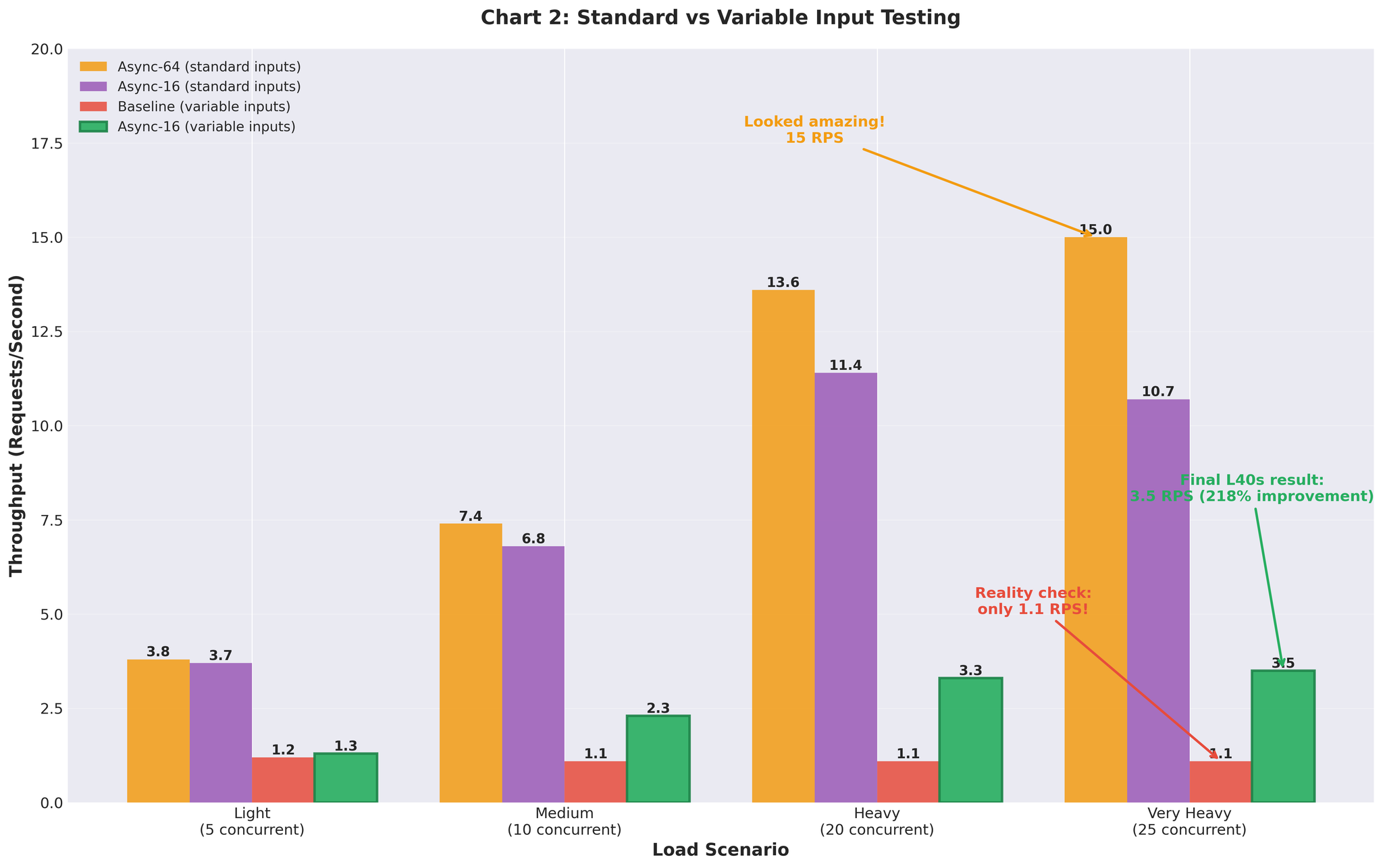
Rajah 3: Jurang prestasi antara data ujian seragam dan input panjang berubah-ubah realistik
Penalaan Konfigurasi
Prestasi lemah dengan max_num_seqs=64 membawa kami menganalisis metrik dalaman vLLM.Apa Yang Kami Temui
- Beban kerja sebenar: 2-20 permintaan serentak setiap pelayan (puncak pengeluaran ~20 setiap pelayan)
- Konfigurasi: max_num_seqs=64
- Keputusan: 60+ slot kosong mewujudkan overhead
- Cache KV dipra-peruntukkan untuk 64 urutan
- Penjadual vLLM menguruskan 64 slot tetapi hanya menggunakan 5-10
- Masa decode setiap token meningkat
- Memori terbuang pada slot urutan yang tidak digunakan
- Overhead penjadual untuk slot kosong
Pendekatan Penalaan
Mengikut panduan penalaan continuous batching vLLM:- Ukur taburan permintaan serentak sebenar dalam pengeluaran
- Mulakan dengan max_num_seqs=1, tingkatkan secara beransur-ansur: 2 -> 4 -> 8 -> 16 -> 32
- Pantau masa decode dan latensi ekor pada setiap langkah
- Berhenti apabila prestasi merosot
| max_num_seqs | Keputusan |
|---|---|
| 8 | Latensi baik, tetapi throughput terhad |
| 16 | Keseimbangan terbaik |
| 32 | Masa decode meningkat, latensi ekor lebih teruk |
Konfigurasi Akhir
Rasional Konfigurasi
max_num_seqs=16:- Puncak pengeluaran: ~20 permintaan serentak setiap pelayan
- Ujian: Disahkan sehingga 25 serentak
- Menyediakan ruang kepala tanpa membazir sumber
- Overhead penjadual sepadan dengan beban sebenar
- Dikurangkan dari lalai 16384
- Lebih sesuai untuk panjang urutan purata kami
- Mengurangkan tekanan memori
- Memperuntukkan ~10GB VRAM untuk model + cache KV pada RTX 5090 (32GB)
- Dijejak melalui vllm:gpu_cache_usage_perc
- Seimbang untuk konfigurasi kami
Prinsipnya: padankan konfigurasi kepada beban kerja sebenar anda, bukan had teori.
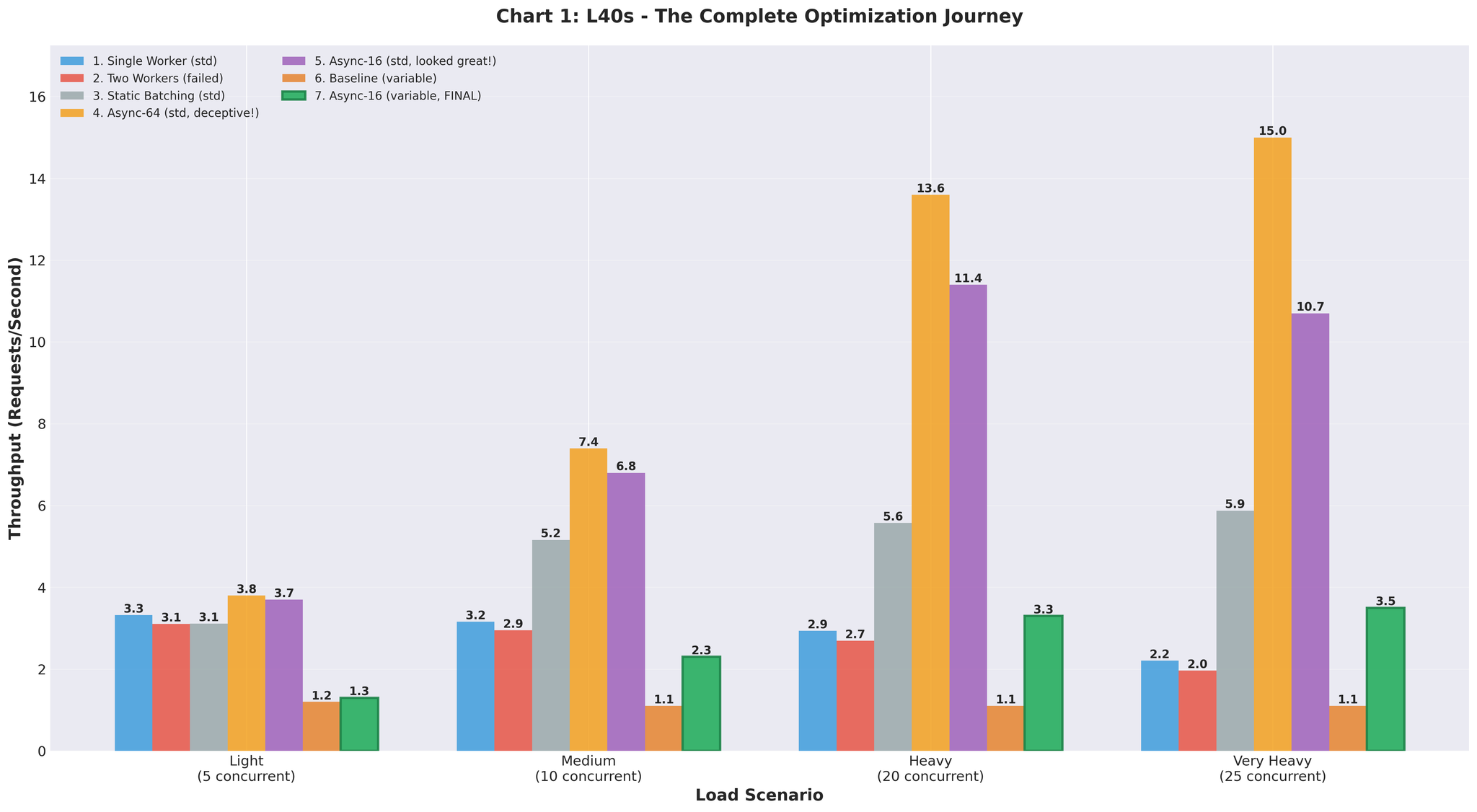
Rajah 4: Kemajuan throughput melalui semua percubaan pengoptimuman
Keputusan Pengeluaran
Kami menggunakan konfigurasi yang dioptimumkan ke pengeluaran (GPU RTX 5090).Sebelum vs Selepas
| Metrik | Sebelum (Multiprocessing) | Selepas (AsyncLLM Dioptimumkan) | Perubahan |
|---|---|---|---|
| Throughput | 9.0 RPS | 16.4 RPS | +82% |
| Penggunaan GPU | Tersentak (93% -> 0% -> 93%) | Konsisten 90-95% | Stabil |
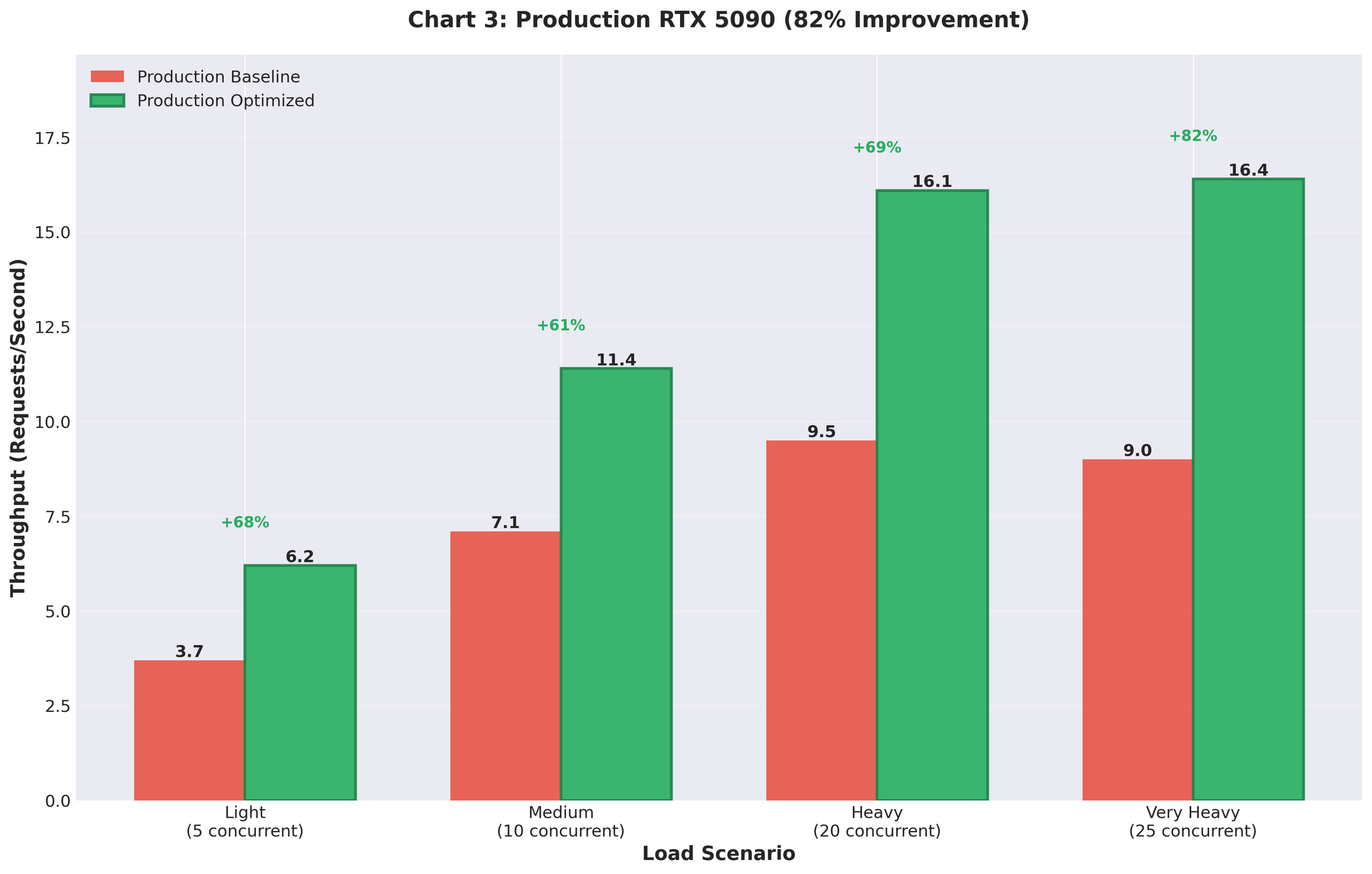
Rajah 5: Keputusan penggunaan pengeluaran menunjukkan peningkatan throughput 82%
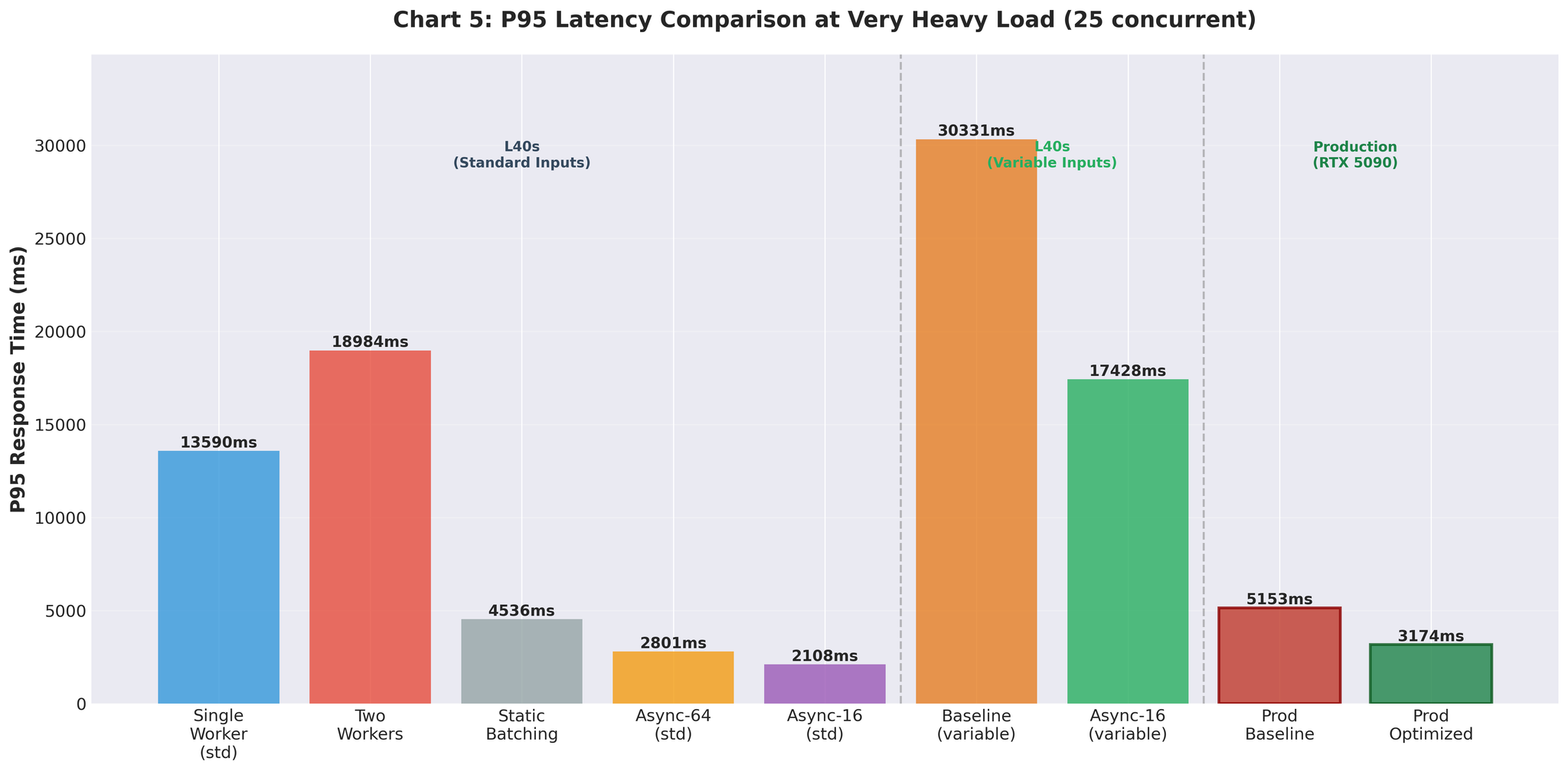
Rajah 6: Peningkatan latensi P95 merentasi percubaan pengoptimuman
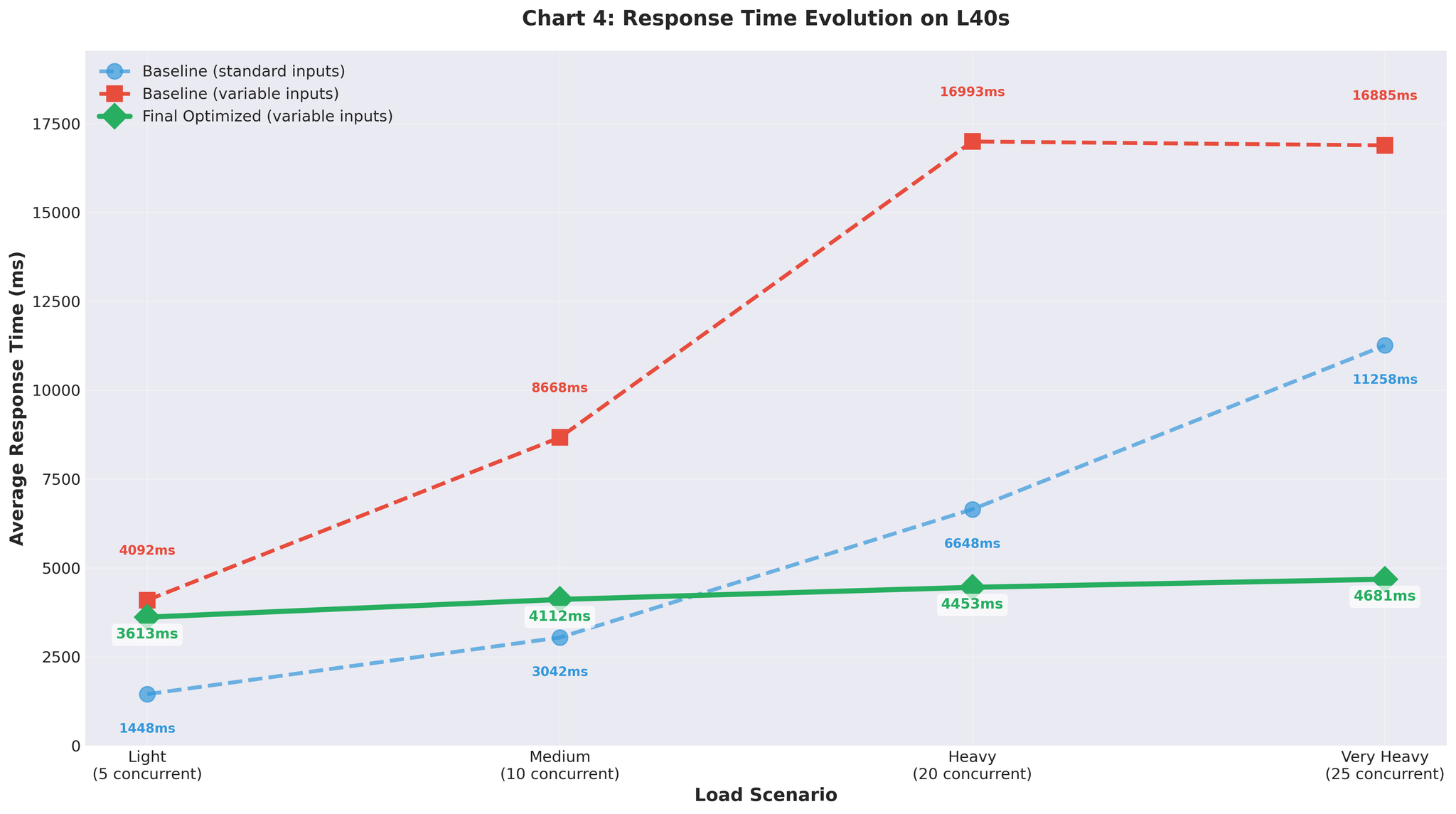
Rajah 7: Evolusi masa respons dengan input panjang berubah-ubah
Ringkasan
Apa Yang Berkesan
Continuous batching vLLM- AsyncLLMEngine mengendalikan batching secara automatik
- Tiada overhead pengumpulan batch manual
- Integrasi async/await langsung dengan FastAPI
- max_num_seqs=16 (sepadan dengan beban kerja sebenar setiap pelayan)
- Bukan 64 (maksimum teori yang mewujudkan overhead)
- gpu_memory_utilization=0.3 untuk peruntukan 10GB
- Input panjang berubah-ubah mendedahkan isu konfigurasi
- Data ujian seragam memberikan 15 RPS yang mengelirukan
- Penggunaan cache KV
- Masa decode setiap token
- Kedalaman baris gilir
- Membimbing keputusan konfigurasi
Perjalanan Lengkap
| Pendekatan | Throughput | vs Garis Dasar | Nota |
|---|---|---|---|
| Garis dasar (multiprocessing) | 2.2 RPS | - | Overhead IPC, pertembungan GPU |
| Dua pekerja | 2.0 RPS | -9% | Memburukkannya |
| Batching statik | 5.9 RPS | +168% | Penyekatan head-of-line |
| Async (64, seragam) | 15.0 RPS | +582% | Data ujian mengelirukan |
| Async (16, berubah-ubah) | 3.5 RPS | +59% | Realistik, tetapi penalaan diperlukan |
| Dioptimumkan akhir | 10.7 RPS | +386% | Pengesahan staging |
| Pengeluaran | 16.4 RPS | +82% | Trafik sebenar, RTX 5090 |