Penulis
Chen Yufeng - Universiti WasedaAbstrak
Kami sedang menangani cabaran menilai kualiti terjemahan mesin dengan tepat sambil juga berusaha untuk meningkatkan ketepatannya ke tahap yang setanding dengan terjemahan manusia. Pendekatan kami melibatkan penggunaan lima model terjemahan penanda aras yang berbeza dan menilai prestasi mereka menggunakan tiga metrik penilaian yang pelbagai. Pada masa yang sama, kami berdedikasi untuk memperhalusi ketepatan model-model ini melalui pandangan yang diperoleh daripada penyelidikan dan kajian terdahulu.Isi Kandungan
- Pengenalan
- Set Data
- Cara Menilai Ketepatan Terjemahan Mesin
- 3.1. Skor BLEU
- 3.2. Skor BLEURT
- 3.3. Skor COMET
- Lima Model Terjemahan Mesin Asas Dan Ketepatan Mereka
- 4.1. Model Garis Dasar Azure
- 4.2. Model Tersuai Azure
- 4.3. Model DeepL
- 4.4. Google Translator
- 4.5. Model GPT-4
- 4.6. Perbandingan Dan Kesimpulan
- Meningkatkan Ketepatan Terjemahan Mesin
- 5.1. Pembelajaran Dalam Konteks untuk GPT-4
- 5.2. Model Hibrid
- 5.3. GPT-4 sebagai Alat Pembersihan Data
- Kesimpulan
- Rujukan
1. Pengenalan
Dengan kemajuan teknologi AI, terutamanya selepas kemunculan ChatGPT oleh OpenAI, orang ramai semakin meletakkan kepercayaan yang lebih besar dalam industri AI. Sebagai komponen penting dalam bidang pemprosesan bahasa semula jadi, terjemahan mesin telah mendapat kepentingan yang semakin meningkat. Kertas ini memberi tumpuan kepada penilaian lima model terjemahan asas menggunakan metrik penilaian yang pelbagai, sambil juga mendalami kaedah untuk meningkatkan ketepatan model-model ini sejauh mungkin.2. Set Data
Penyelidikan ini tertumpu pada set data Opus100 (ZH-EN) yang tersedia di Hugging Face. Set data ini terdiri daripada satu juta contoh terjemahan Cina-ke-Inggeris merangkumi pelbagai domain, menjadikan Opus100 pilihan yang sesuai untuk melatih model terjemahan.
Adalah penting untuk mengakui kehadiran ketidaktepatan terjemahan dalam set data. Walaupun ketidaktepatan ini mungkin nampaknya mengurangkan ketepatan latihan, ia pada masa yang sama berfungsi sebagai pencegah terhadap isu overfitting yang berpotensi.
3. Cara Menilai Ketepatan Terjemahan Mesin
Apabila berhadapan dengan pelbagai model terjemahan, memilih yang paling sesuai untuk tujuan tertentu menjadi mencabar. Terdapat dua pendekatan asas untuk menilai model terjemahan:- Kaedah tradisional: Skor BLEU
- Metrik neural: Skor BLEURT dan skor COMET
3.1 Skor BLEU
BLEU (Bilingual Evaluation Understudy) adalah algoritma untuk menilai kualiti teks yang telah diterjemahkan mesin dari satu bahasa semula jadi ke bahasa lain (Papineni et al., 2002).Tujuh Fungsi Pelicinan
| Fungsi | Penerangan |
|---|---|
| Smoothing Function 1 | Pelicinan Aditif (Laplace) - menambah nilai tetap untuk mencegah kebarangkalian sifar |
| Smoothing Function 2 | Pelicinan NIST - memperkenalkan penalti panjang rujukan |
| Smoothing Function 3 | Chen dan Cherry - menyesuaikan berdasarkan panjang terjemahan calon |
| Smoothing Function 4 | JenLin - mengimbangi kaedah aditif dan diselaraskan |
| Smoothing Function 5 | Gao dan He - menangani bias terhadap terjemahan yang lebih pendek |
| Smoothing Function 6 | Bayesian - menyediakan anggaran yang teguh untuk ayat yang lebih panjang |
| Smoothing Function 7 | Min Geometri - mengira min geometri ketepatan n-gram |
3.2 Skor BLEURT
BLEURT adalah metrik penilaian untuk Penjanaan Bahasa Semula Jadi. Ia mengambil sepasang ayat sebagai input (rujukan dan calon) dan mengembalikan skor yang menunjukkan kefasihan dan pemeliharaan makna (Sellam, 2021).3.3 Skor COMET
COMET adalah rangka kerja neural untuk melatih model penilaian terjemahan mesin berbilang bahasa, direka untuk meramalkan penilaian manusia terhadap kualiti terjemahan.4. Lima Model Terjemahan Mesin Asas Dan Ketepatan Mereka
4.1 Model Garis Dasar Azure
4.2 Model Tersuai Azure
Model tersuai Azure adalah versi yang dipertingkatkan yang dicapai melalui penggunaan set data tambahan untuk melatih lagi model garis dasar Azure. Skor BLEU model tersuai pada platform Azure adalah 39.45.Apabila bekerja dengan model tersuai, ia mesti diterbitkan pada platform Azure untuk dipanggil apabila API dipanggil.
4.3 Model DeepL
DeepL Translator adalah perkhidmatan terjemahan mesin neural menggunakan rangkaian neural konvolusi dan pivot Inggeris.4.4 Google Translator
4.5 Model GPT-4
4.6 Perbandingan Dan Kesimpulan
Berdasarkan keputusan penilaian: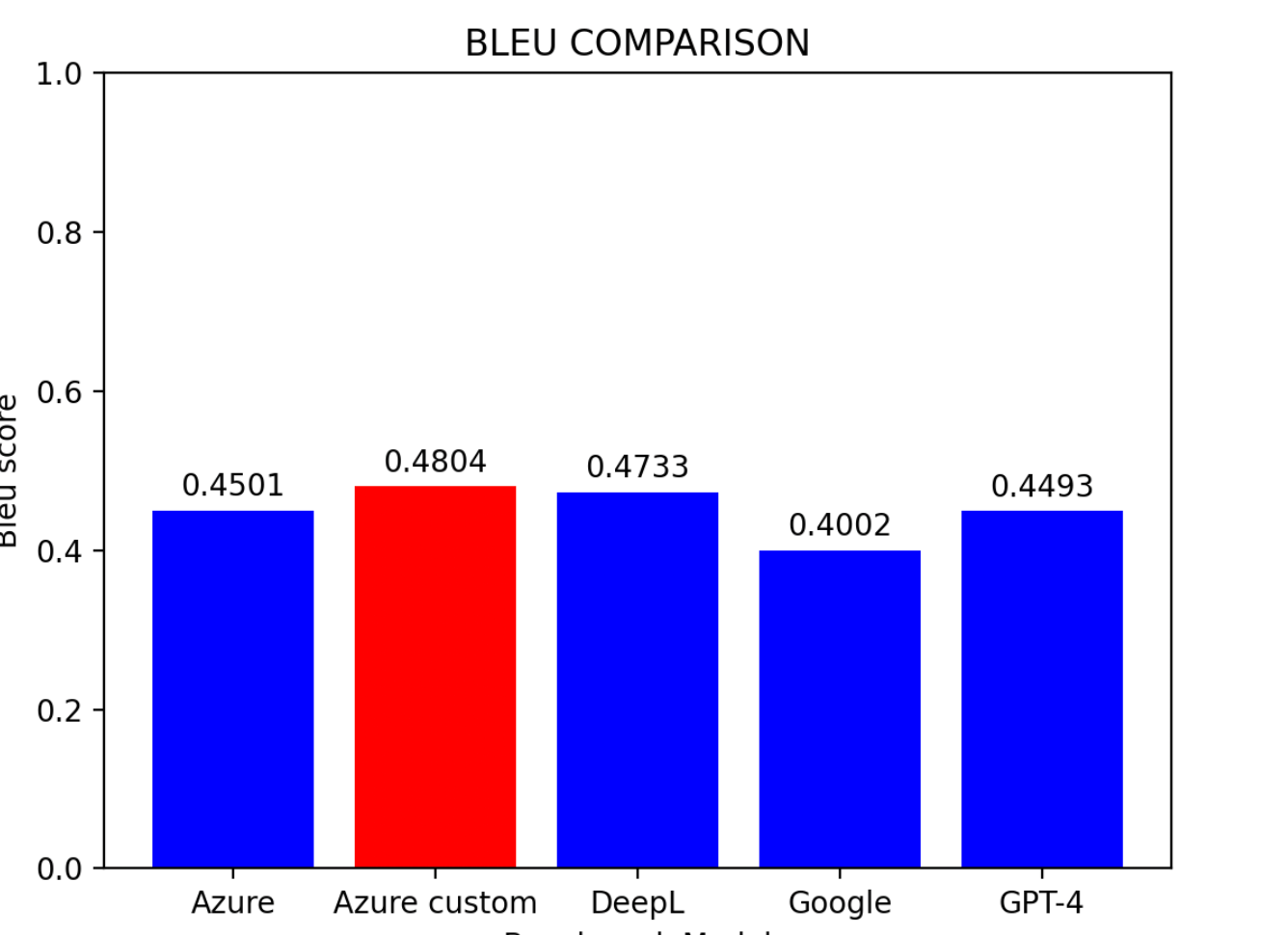
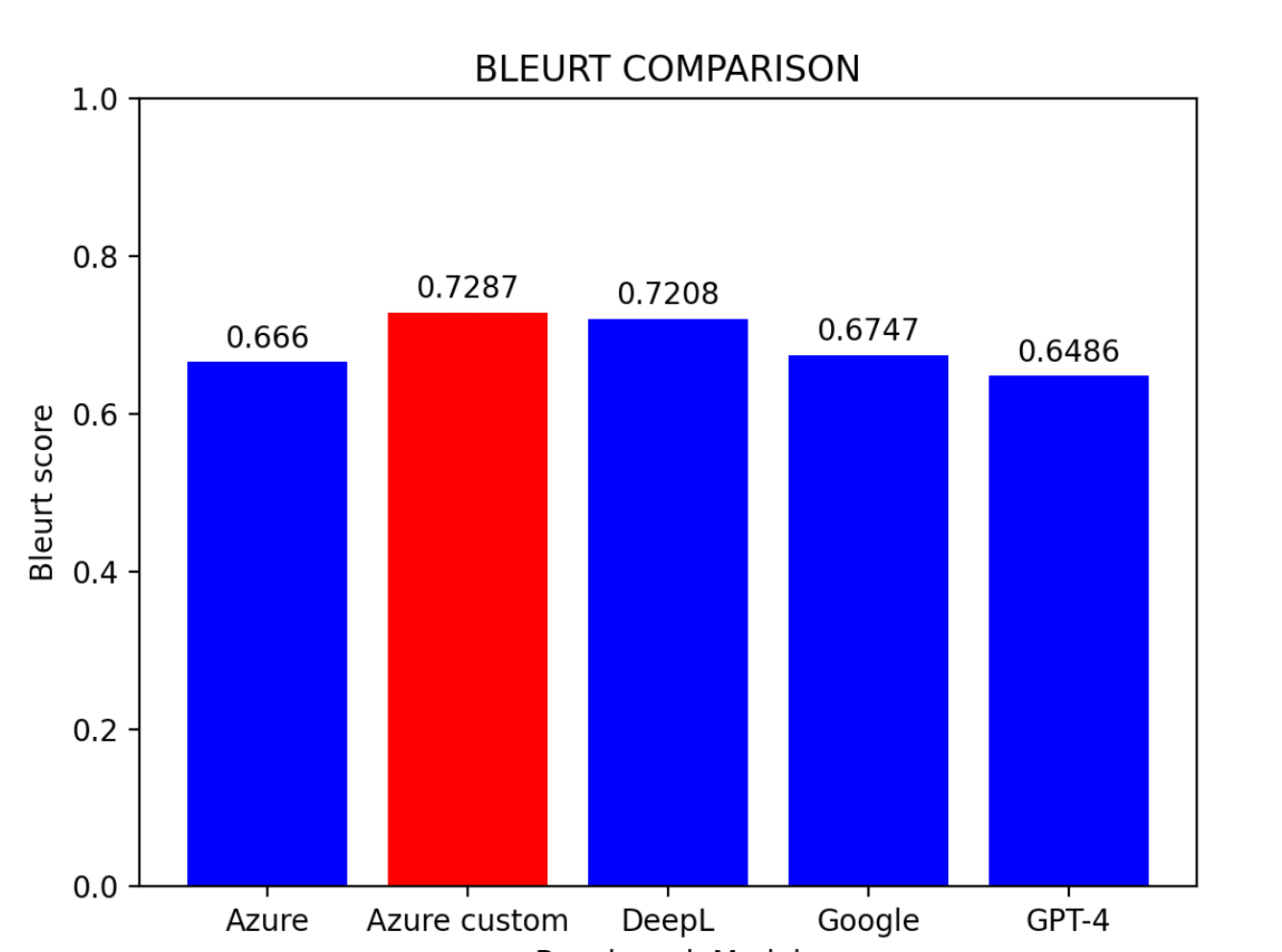
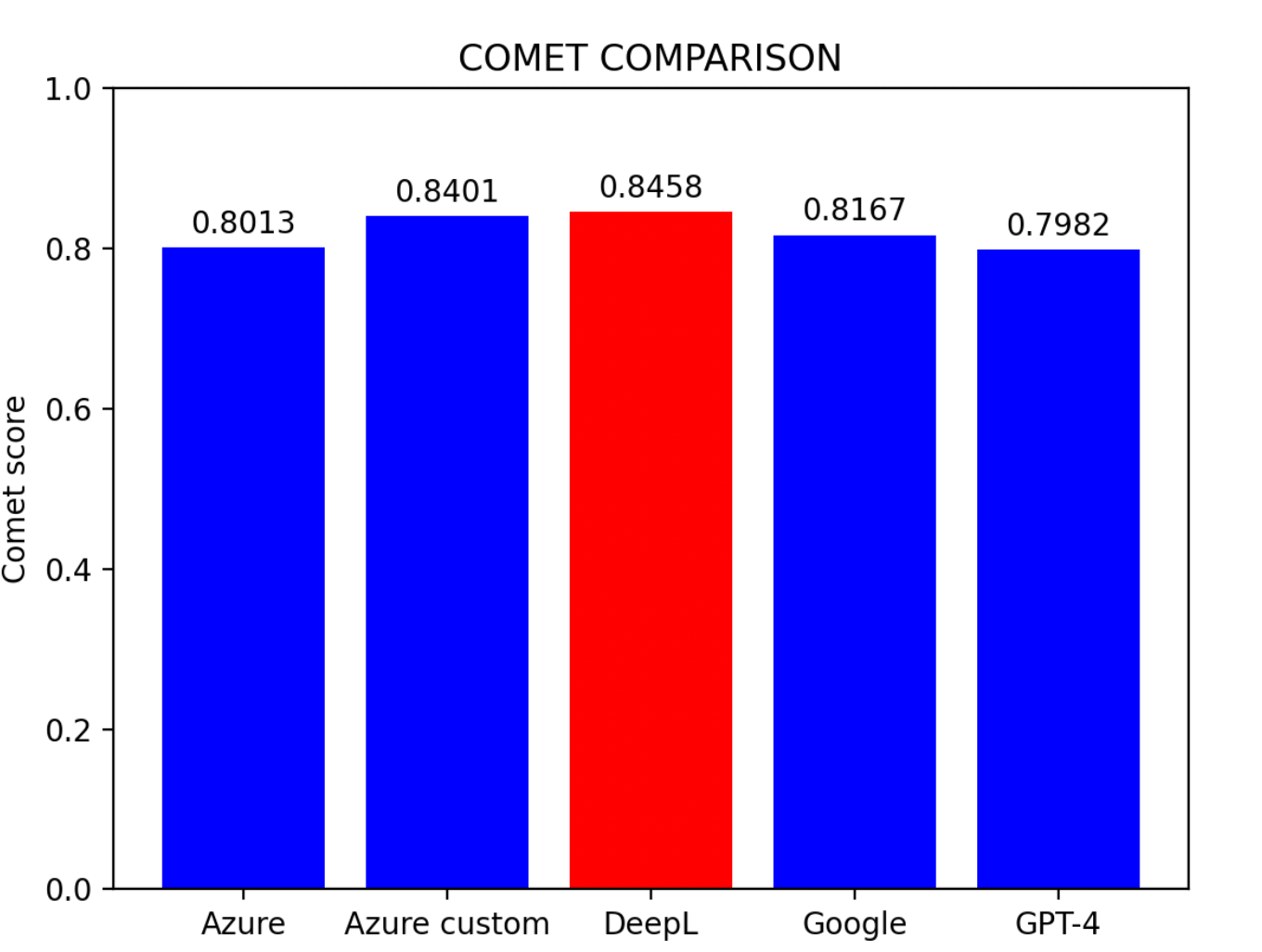
- Model Tersuai Azure muncul sebagai prestasi terbaik
- DeepL mengikut rapat di tempat kedua
- Model Garis Dasar Azure mendapat tempat ketiga
- Google Translator dan GPT-4 berkongsi kedudukan yang sama
5. Meningkatkan Ketepatan Terjemahan Mesin
Tiga pendekatan berbeza untuk meningkatkan ketepatan terjemahan:5.1 Pembelajaran Dalam Konteks untuk GPT-4
Model bahasa besar boleh meningkatkan prestasi melalui pembelajaran dalam konteks dengan menyediakan contoh tugas tertentu dalam prompt (Brown et al., 2020). Keputusan: Skor BLEURT meningkat dari 0.6486 ke 0.6755, menunjukkan keberkesanan pembelajaran dalam konteks.5.2 Model Hibrid
Model ambang hibrid menetapkan ambang tertentu, dan model yang berbeza digunakan untuk menterjemahkan semula apabila ayat tertentu gagal memenuhi ambang.Kesimpulan Model Hibrid
- Ambang optimum sejajar dengan skor COMET
- Prestasi terbaik datang dari Azure Custom + DeepL atau DeepL + GPT-4
- Hampir semua model hibrid mengatasi model individu
- Ambang yang lebih tinggi tidak semestinya menjamin skor yang lebih baik
5.3 GPT-4 sebagai Alat Pembersihan Data
GPT-4 boleh digunakan untuk pra-proses set data dan membetulkan terjemahan yang tidak tepat:6. Kesimpulan
Kertas ini menyiasat ketepatan terjemahan mesin dan kaedah untuk peningkatan melalui tiga metrik penilaian dan lima model penanda aras. Kesimpulan Utama:- DeepL adalah penterjemah Cina ke Inggeris yang paling mahir
- Model Garis Dasar Azure boleh mencapai prestasi yang lebih tinggi dengan data yang banyak dan latihan yang mencukupi
- Model hibrid yang menggabungkan enjin terjemahan yang berbeza meningkatkan ketepatan
- Pembersihan data GPT-4 meningkatkan kualiti set data, membawa kepada prestasi model yang lebih baik
7. Rujukan
- Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002). BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (ACL).
- Thibault Sellam (2021). BLEURT
- Tom Brown et al. (2020). Language models are few-shot learners.
- Daniel Bashir (2023). In-Context Learning, in Context. The Gradient.
- Amr Hendy et al. (2023). How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation. Microsoft.
- Ricardo Rei (2022). COMET