Penulis
Ashar Mirza - VoicePing Inc.Masalah
Kami menjalankan perkhidmatan mikro terjemahan menggunakan FastAPI dan vLLM. Di bawah beban berat, kami mengalami isu latensi pelayan yang tidak sepadan dengan apa yang dicadangkan oleh metrik penggunaan GPU kami. Penggunaan GPU menunjukkan corak tersentak: lonjak ke 93%, jatuh ke 0%, lonjak semula. Bukan penggunaan tinggi yang konsisten yang kami jangkakan. Soalannya: jika GPU mempunyai tempoh terbiar, di mana bottlenecknya? Artikel ini meliputi bagaimana kami mengenal pasti isu seni bina dalam persediaan FastAPI + multiprocessing kami yang menghalang penggunaan GPU yang cekap.Konteks Sistem
Perkhidmatan terjemahan kami berjalan sebagai berbilang pelayan API di belakang pengimbang beban:
Rajah 1: Seni bina sistem keseluruhan menunjukkan aplikasi klien, proksi/pengimbang beban, dan berbilang pelayan API
- Klien: Web, mudah alih, perkhidmatan backend
- Proksi: Mengarahkan permintaan berdasarkan pasangan bahasa dan kesihatan pelayan
- Pelayan API: Berbilang contoh FastAPI, setiap satu menjalankan vLLM
Seni Bina Pelayan API
Berikut adalah struktur dalaman satu pelayan API:
Rajah 2: Seni bina pelayan API tunggal menunjukkan FastAPI, baris gilir multiprocessing, proses pekerja, dan contoh vLLM
Komponen
1. Proses Utama FastAPI
- Mengendalikan permintaan HTTP dengan async/await
- Satu proses Python, satu event loop
- I/O tidak menyekat untuk pengendalian permintaan serentak
2. TranslationService
- Mencipta tugas terjemahan
- Mengurus objek EventTask dengan asyncio.Event
- Menjambatani async/await dengan multiprocessing
3. TranslationWorker (Proses Utama)
- Baris gilir dicipta dalam proses utama (dikongsi dengan pekerja)
- JoinableQueue untuk pengagihan tugas
- manager().dict() untuk keadaan tugas dikongsi
- Baris gilir event untuk keputusan
4. Proses Pekerja
- Dicipta sebagai proses berasingan (ctx.Process)
- Setiap satu memuatkan contoh model vLLM sendiri
- Tarik dari translation_queue dikongsi
- Kembalikan melalui event_queue dikongsi
5. EventTask (Penyegerakan Async)
- Menjambatani multiprocessing dengan async/await
- Setiap permintaan mendapat EventTask
await event.wait()menyekat coroutine sehingga pekerja selesai
Aliran Permintaan
Berikut adalah apa yang berlaku untuk satu permintaan terjemahan:
Rajah 3: Aliran permintaan langkah demi langkah menunjukkan titik serialisasi dan menunggu async
- Klien POST /translate -> FastAPI mencipta coroutine async
- async translate() -> TranslationService mengendalikan permintaan
- create_task() -> Jana ID, cipta TranslationTask dalam dict dikongsi
- queue.put(key) -> Serialisasikan kunci tugas, hantar ke pekerja (overhead IPC)
- Pekerja: vllm.translate() -> Pekerja memproses terjemahan
- event_queue.put(result) -> Serialisasikan keputusan, hantar balik (overhead IPC)
- event.set() -> Kemas kini EventTask, bangkitkan coroutine
- await event.wait() tidak disekat -> Dapatkan keputusan
- Kembalikan respons -> Hantar ke klien
- Langkah 4: Serialisasi (pickle kunci tugas)
- Langkah 6: Serialisasi (pickle keputusan)
- Langkah 8: Menunggu async untuk keputusan multiprocessing
- Koordinasi IPC sepanjang masa
Prestasi Garis Dasar
Sebelum percubaan pengoptimuman: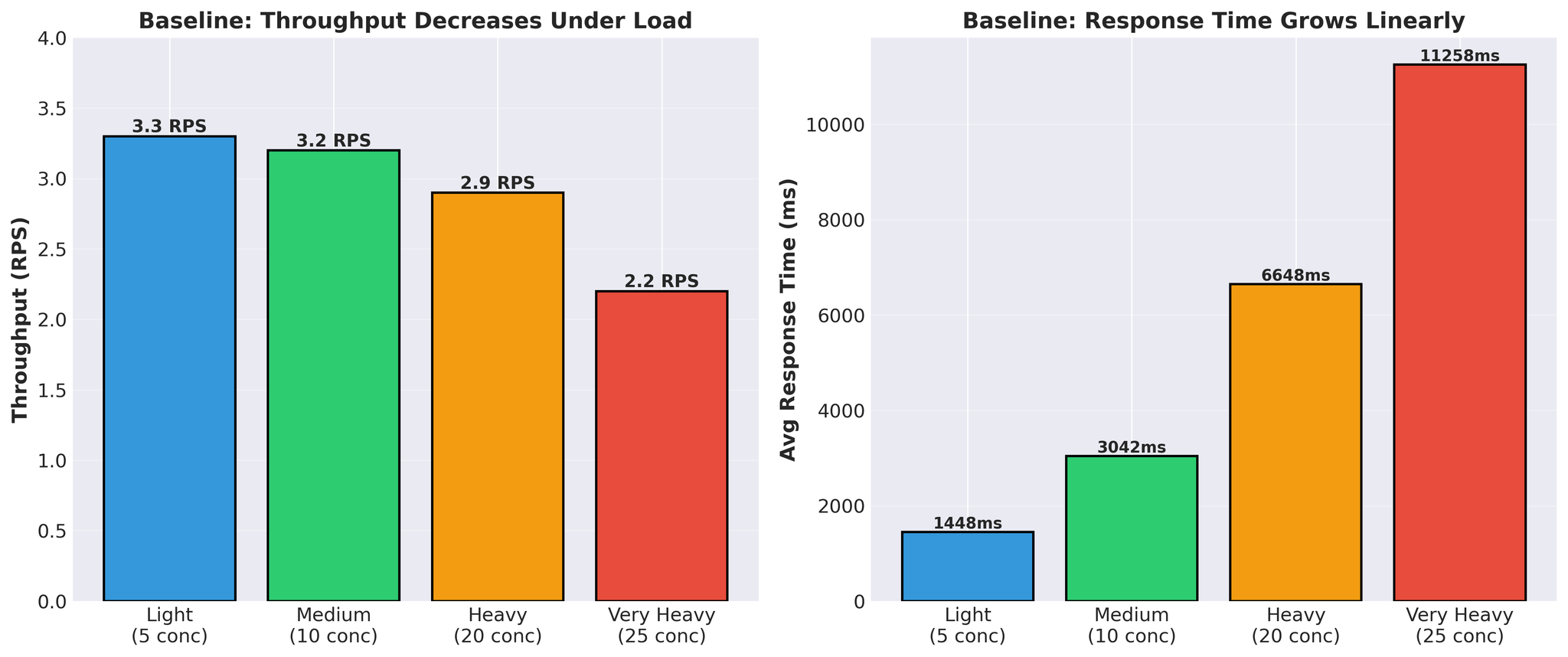
Rajah 4: Prestasi garis dasar menunjukkan penurunan throughput dan peningkatan masa respons di bawah beban
- Masa respons berkembang secara linear (1.4s -> 11.3s)
- Throughput menurun di bawah beban (3.3 -> 2.2 RPS)
- Masa terjemahan vLLM sebenar setiap permintaan: 300-450ms
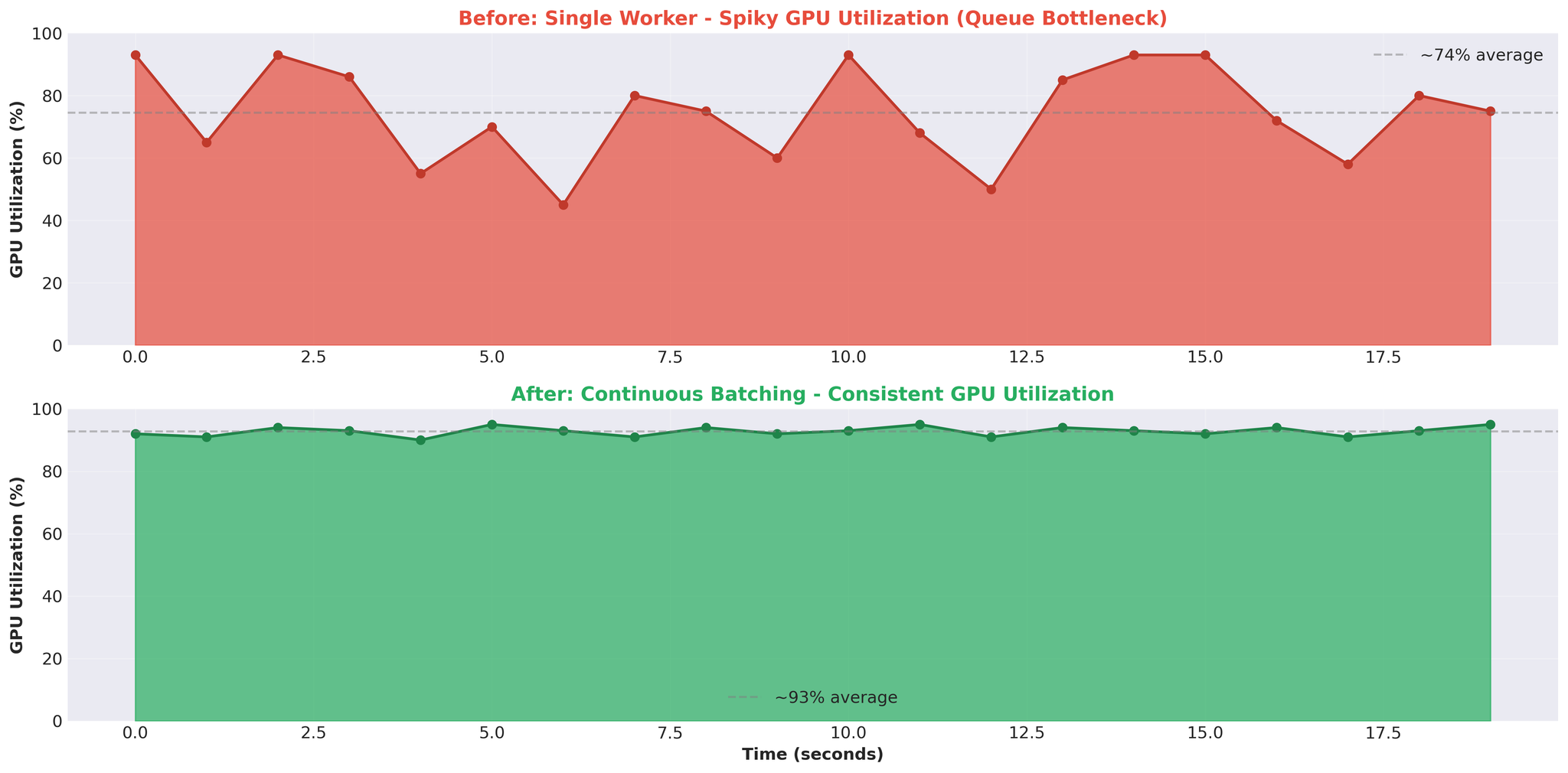
Rajah 5: Corak penggunaan GPU sebelum (tersentak) dan selepas (konsisten) pengoptimuman
Percubaan 1: Berbilang Pekerja
Hipotesis pertama: lebih banyak pekerja = penselarian lebih baik. Kami meningkatkan dari 1 pekerja ke 2 pekerja.Konfigurasi
- Pekerja 1: Model A+B
- Pekerja 2: Model C
- Kedua-dua berkongsi GPU yang sama
Keputusan
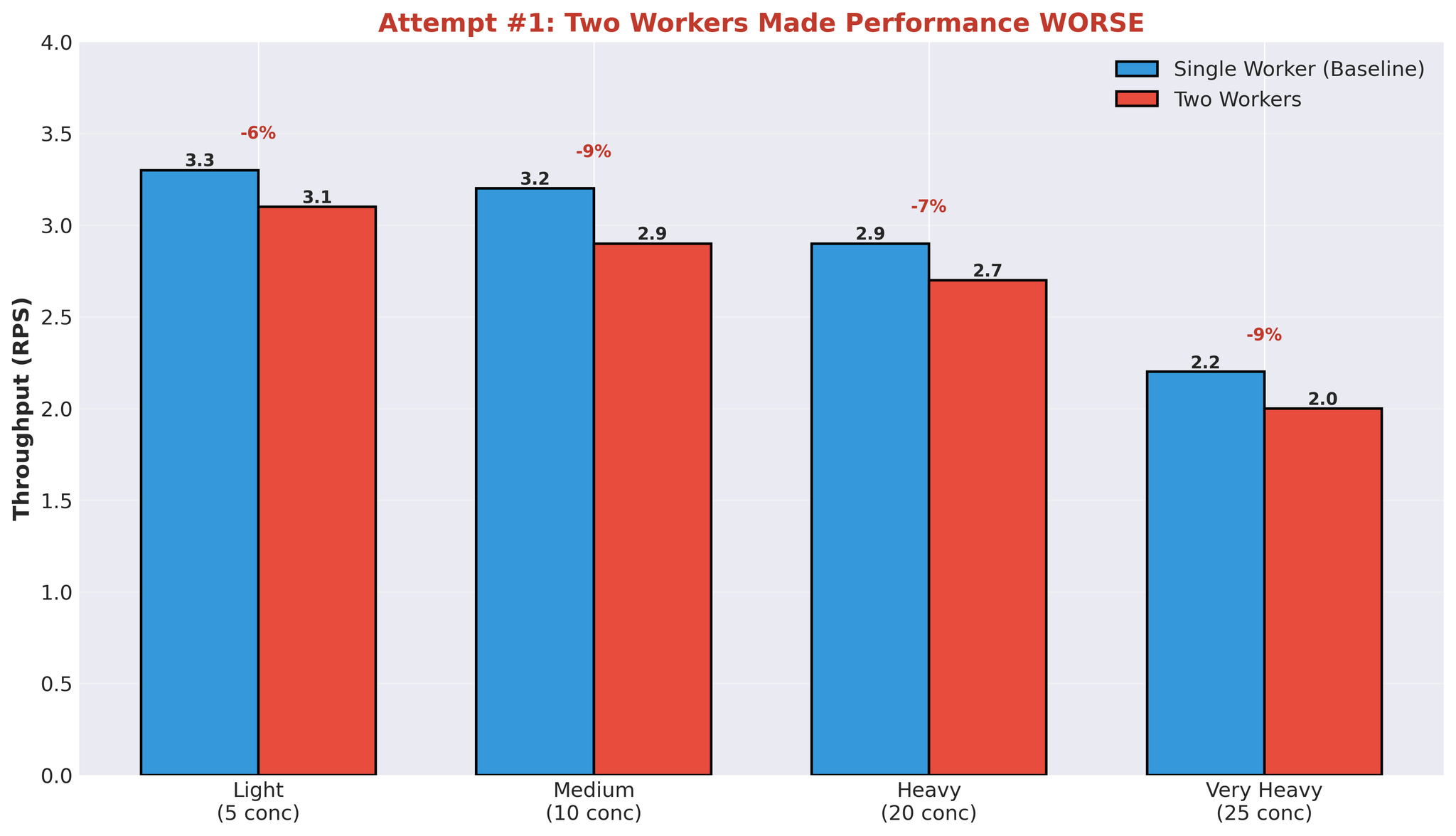
Rajah 6: Kemerosotan prestasi apabila menambah proses pekerja kedua
Mengapa Berbilang Pekerja Gagal
Keputusan ini masuk akal apabila anda memahami tingkah laku GPU dan seni bina kami.
Rajah 7: Berbilang proses pekerja bersaing untuk kapasiti pengiraan GPU
Isu: Pertembungan Pengiraan
Apabila satu pekerja sedang memproses terjemahan:- Ia menggunakan ~90% kapasiti pengiraan GPU
- Pekerja lain tidak dapat menggunakan kapasiti selebihnya secara efektif secara selari
- Pekerja akhirnya menunggu ketersediaan GPU
- Pekerja 1 memulakan penjanaan vLLM -> menggunakan ~90% pengiraan GPU
- Pekerja 2 cuba memulakan -> hanya ~10% pengiraan GPU tersedia
- Pekerja 2 berjalan perlahan atau menunggu
- Pelaksanaan berurutan secara efektif walaupun proses berasingan
- Penciptaan dan pengurusan proses
- Memori GPU dibahagi antara pekerja (setiap satu memuatkan pemberat model)
- Koordinasi baris gilir IPC
- Pertukaran konteks antara proses
Bottleneck Dikenal Pasti
Selepas eksperimen ini, kami mengenal pasti isu teras:1. Overhead Serialisasi IPC
- Setiap permintaan: serialisasikan tugas -> pekerja, serialisasikan keputusan -> utama
- Baris gilir multiprocessing Python menggunakan pickle
- Overhead pada setiap permintaan
2. Pertembungan Pengiraan
- Satu pekerja menggunakan ~90% pengiraan GPU
- Pekerja lain tidak dapat berjalan secara efektif secara selari
- Pelaksanaan berurutan walaupun multiprocessing
3. Jambatan Async/Await + Multiprocessing
- asyncio.Event menunggu keputusan multiprocessing
- Pengguna baris gilir event berasaskan thread
- Overhead koordinasi antara model async dan multiprocess
4. Kitaran GPU Terbuang
- GPU terbiar sambil menunggu operasi baris gilir
- Penggunaan tersentak (93% -> 0% -> 93%)
- Masa terjemahan ~400ms, jumlah masa respons 11+ saat
- Kebanyakan masa dihabiskan dalam baris gilir, bukan mengira
5. Kerumitan Seni Bina
- FastAPI (async/await)
- TranslationService (jambatan)
- TranslationWorker (koordinasi)
- JoinableQueue (IPC)
- Proses pekerja (multiprocessing)
- Baris gilir event (IPC)
- EventTask (segerak async)
- vLLM (kerja sebenar)
Pandangan Utama
1. Async/Await + Multiprocessing = Overhead
Menjambatani dua model keserentakan ini memerlukan koordinasi:- asyncio.Event untuk menunggu async
- Kumpulan thread untuk menggunakan baris gilir event
- Serialisasi pada sempadan proses
2. Berbilang Proses ≠ Penselarian GPU
Menambah proses pekerja tidak secara automatik meningkatkan penggunaan GPU apabila:- Satu pekerja menggunakan ~90% pengiraan GPU
- Kapasiti selebihnya tidak mencukupi untuk kerja selari
- Pelaksanaan berurutan walaupun overhead multiprocessing
3. Overhead Baris Gilir Mendominasi
Pada 25 permintaan serentak:- Masa terjemahan vLLM: ~400ms
- Jumlah masa respons: 11,258ms
- Overhead baris gilir: ~97% daripada jumlah masa
4. GPU Tersentak = Isu Seni Bina
- Penggunaan GPU konsisten (cth. 90-95%) menunjukkan beban kerja terikat pengiraan
- Corak tersentak (93% -> 0% -> 93%) menunjukkan GPU sedang menunggu kerja - bottleneck di tempat lain (dalam kes kami, baris gilir dan IPC)
Kesimpulan
Bottleneck bukan kapasiti GPU. Ia adalah seni bina multiprocessing kami: Isu dikenal pasti:- Overhead IPC daripada serialisasi baris gilir
- Pertembungan pengiraan GPU tanpa penselarian efektif
- Overhead koordinasi async/await + multiprocessing
- Kebanyakan latensi dari baris gilir, bukan pemprosesan vLLM
- Penggunaan GPU tersentak
- Masa respons didominasi oleh menunggu baris gilir
- Menambah pekerja memburukkan prestasi
Dalam Bahagian 2, kami akan meliputi penyelesaian: menghapuskan multiprocessing, menggunakan AsyncLLMEngine vLLM secara langsung, dan mencapai peningkatan throughput 82% dalam pengeluaran.
- Buang seni bina multiprocessing sepenuhnya
- Gunakan AsyncLLMEngine vLLM dengan FastAPI secara langsung
- Saiz betul konfigurasi continuous batching
- Keputusan pengeluaran: Throughput diperbaiki (+82%)