1. Pengenalan
Model bahasa besar (LLM) telah menunjukkan kemahiran yang mengagumkan dalam tugas hiliran melalui pengkondisian pada pasangan input-label. Mod inferens ini dipanggil pembelajaran dalam konteks (Brown et al. 2020). GPT-4 boleh meningkatkan keupayaan terjemahannya tanpa penalaan halus dengan menyediakan contoh tugas tertentu.
Rajah 1: Pembelajaran dalam konteks untuk terjemahan Cina ke Inggeris menggunakan contoh few-shot
2. Kaedah Dicadangkan
Metodologi ini mengandaikan akses kepada set data Ds yang mengandungi pasangan terjemahan. Pengambil teks (Gao 2023) mencari dan memilih K ayat teratas dengan makna serupa dengan prompt pengguna. Pengambil mempunyai dua komponen:- Matriks TF-IDF - mengukur kekerapan istilah dan kekerapan dokumen songsang
- Kesamaan Kosinus - mengukur kesamaan antara vektor TF-IDF
Skor TF-IDF
Skor TF-IDF mengukur kepentingan perkataan dalam dokumen:- TF (Kekerapan Istilah): Berapa kerap perkataan muncul dalam dokumen
- IDF (Kekerapan Dokumen Songsang): Kepentingan perkataan merentasi korpus
Kesamaan Kosinus
Kesamaan kosinus menilai kesamaan antara dua vektor dengan mempertimbangkan sudut antara representasi mereka. Skor yang lebih tinggi menunjukkan kesamaan yang lebih besar antara prompt pengguna dan dokumen set data.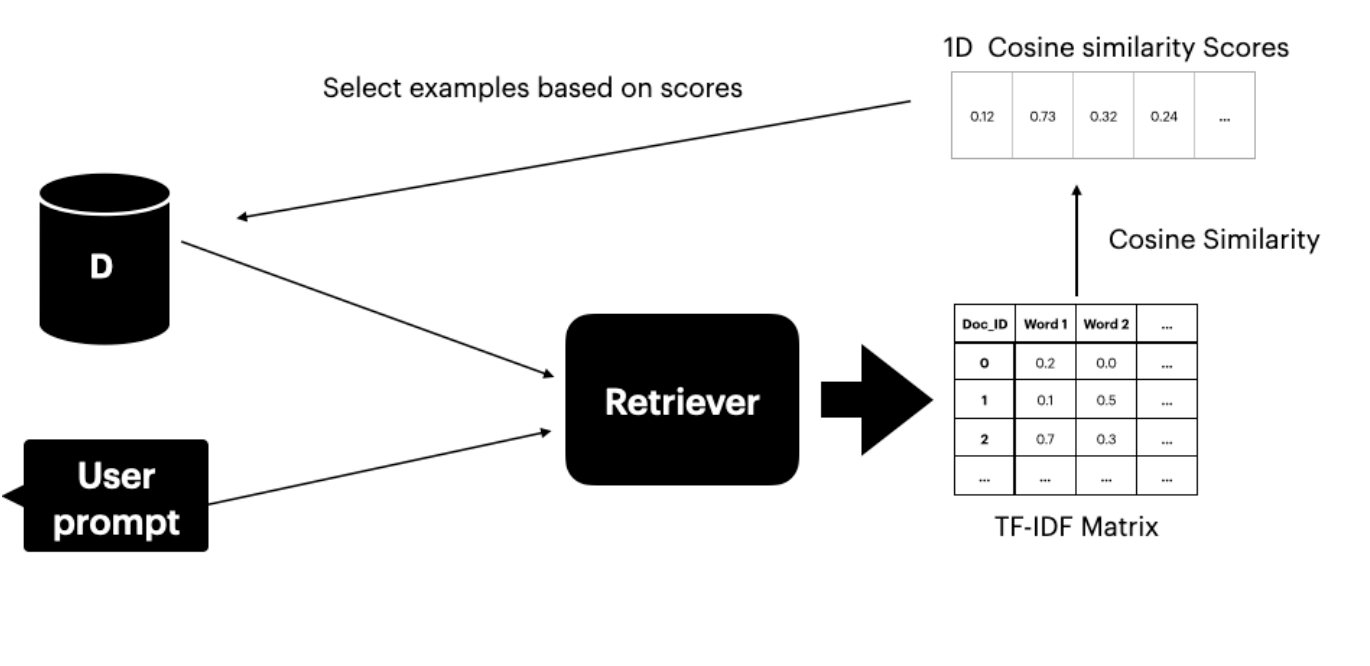
Rajah 2: Menggunakan matriks TF-IDF dan kesamaan kosinus untuk memilih contoh top-K dari set data
3. Persediaan Eksperimen
3.1 Prosedur Eksperimen
Eksperimen meliputi tiga senario:- Tanpa ICL: Terjemahan GPT-4 tanpa contoh pembelajaran dalam konteks
- ICL Rawak: Pemilihan rawak contoh terjemahan
- Kaedah Dicadangkan: Pengambil TF-IDF memilih 4 contoh teratas berdasarkan skor kesamaan
Metrik Penilaian
- Skor BLEU: Membandingkan segmen yang diterjemahkan dengan terjemahan rujukan (Papineni et al. 2002)
- Skor COMET: Rangka kerja neural untuk penilaian MT berbilang bahasa yang mencapai korelasi terkini dengan penilaian manusia (Rei et al. 2020)
3.2 Set Data
OPUS-100 (Zhang et al. 2020) dipilih kerana ia:- Mengandungi pasangan bahasa terjemahan yang pelbagai (ZH-EN, JA-EN, VI-EN)
- Meliputi domain yang pelbagai untuk pemilihan contoh yang berkesan
- 10,000 contoh latihan setiap pasangan bahasa untuk Ds
- 100 ayat pertama dari set ujian untuk penilaian
3.3 Pelaksanaan
MenggunakanTfidfVectorizer dan fungsi cosine_similarity scikit-learn:
- Gabungkan prompt pengguna dengan Ds
- Kira skor kesamaan kosinus antara prompt dan semua ayat
- Pilih 4 contoh teratas berdasarkan kesamaan
- Benamkan contoh ke dalam prompt GPT-4

Rajah 3: Prompt akhir dengan empat contoh yang dikenal pasti oleh pengambil
4. Keputusan dan Perbincangan
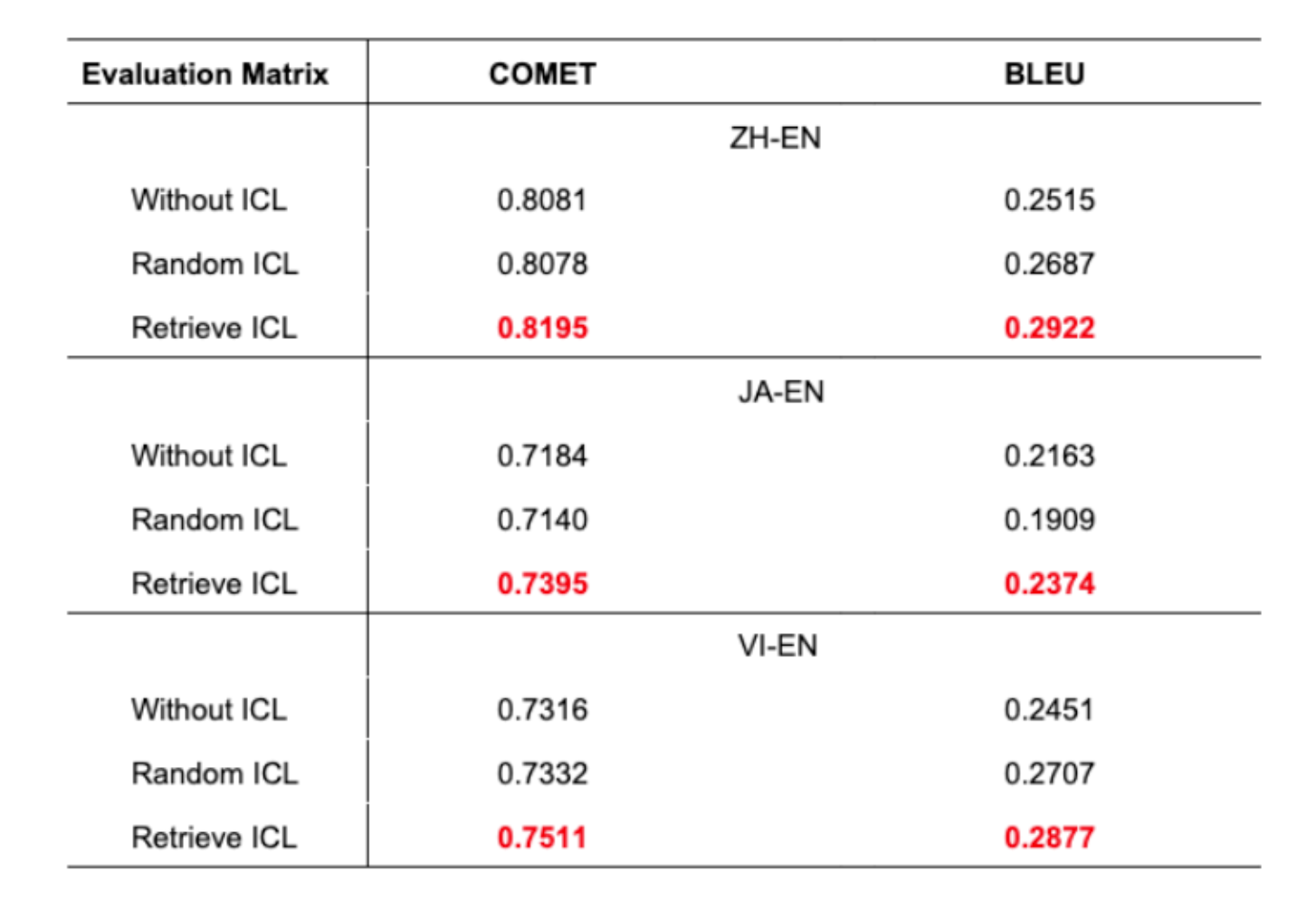
Jadual 1: Ketepatan terjemahan merentasi tiga senario untuk semua pasangan bahasa
- Pendekatan yang dicadangkan menunjukkan ketepatan terjemahan unggul merentasi semua pasangan bahasa
- Peningkatan 1% dalam skor BLEU adalah signifikan dalam terjemahan mesin
- ICL rawak kadangkala berprestasi lebih teruk daripada tanpa ICL langsung
- Ini menyerlahkan kepentingan pemilihan contoh yang bijaksana
Impak Saiz Set Data

Jadual 2: Ketepatan terjemahan dengan saiz set data yang berbeza
5. Kesimpulan dan Langkah Seterusnya
Kertas ini memperkenalkan kaedah untuk meningkatkan terjemahan GPT-4 melalui pembelajaran dalam konteks dengan pengambilan TF-IDF. Pendekatan ini:- Membina pengambil menggunakan matriks TF-IDF dan kesamaan kosinus
- Memilih ayat yang sejajar rapat dengan prompt pengguna
- Menunjukkan peningkatan dalam kedua-dua skor BLEU dan COMET
- Pembinaan Set Data: Mencipta set data terjemahan komprehensif berkualiti tinggi merentasi domain
- Kuantiti Contoh: Menyiasat impak menggunakan 5 atau 10 contoh berbanding 4
6. Rujukan
- Brown, T., et al. (2020). “Language models are few-shot learners.”
- Xie, S. M., et al. (2022). “An Explanation of In-context Learning as Implicit Bayesian Inference.”
- Bashir, D. (2023). “In-Context Learning, in Context.” The Gradient.
- Das, R., et al. (2021). “Case-based reasoning for natural language queries over knowledge bases.”
- Liu, J., et al. (2022). “What makes good in-context examples for GPT-3?”
- Margatina, K., et al. (2023). “Active learning principles for in-context learning with large language models.”
- Gao, L., et al. (2023). “Ambiguity-Aware In-Context Learning with Large Language Models.”
- Papineni, K., et al. (2002). “BLEU: A method for automatic evaluation of machine translation.”
- Rei, R., et al. (2020). “COMET: A Neural Framework for MT Evaluation.”
- Zhang, B., et al. (2020). “Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation.”