Penulis
Boxuan Lyu - Tokyo Institute of TechnologyAbstrak
Penyelidikan ini membentangkan pembangunan sistem Teks-ke-Pertuturan (TTS) yang pantas dan semula jadi untuk Mandarin Cina menggunakan rangka kerja Bert-VITS2. Sistem ini direka khusus untuk senario mesyuarat, menjana pertuturan yang jelas, ekspresif, dan sesuai dengan konteks. Keputusan Utama:- Mencapai WER 0.27 (terendah antara model yang dibandingkan)
- Mencapai MOS 2.90 untuk keaslian pertuturan
- Berjaya mensintesis pertuturan sehingga 22 saat
- Dilatih pada set data AISHELL-3 (85 jam, 218 penutur)
1. Pengenalan
Apakah Teks-ke-Pertuturan?
Teknologi Teks-ke-Pertuturan (TTS) menukar teks bertulis kepada pertuturan yang berbunyi semula jadi. Sistem TTS moden memanfaatkan pembelajaran mendalam untuk menjana pertuturan yang semakin semula jadi dan ekspresif, dengan aplikasi dalam:
- Pembantu pintar
- Penyelesaian pembacaan yang boleh diakses
- Sistem navigasi
- Perkhidmatan pelanggan automatik
Mengapa Mandarin?
Mandarin Cina adalah bahasa yang paling banyak dituturkan dengan lebih satu bilion penutur. Walau bagaimanapun, ia mengemukakan cabaran unik untuk TTS disebabkan sifat tonalnya dan struktur linguistik yang kompleks.Apakah Bert-VITS2?
Bert-VITS2 menggabungkan model bahasa pra-latihan dengan sintesis suara canggih:- Integrasi BERT: Pemahaman mendalam nuansa semantik dan kontekstual
- Latihan gaya GAN: Menghasilkan pertuturan yang sangat realistik melalui pembelajaran adversarial
- Berdasarkan VITS2: Seni bina sintesis suara terkini
2. Metodologi
2.1 Pemilihan Set Data
AISHELL-3 dipilih untuk kajian ini:- 85 jam audio
- 218 penutur
- ~30 minit purata setiap penutur
- Kualiti transkripsi tinggi
Eksperimen awal dengan Alimeeting (118.75 jam) menghasilkan penjanaan audio kosong disebabkan kualiti transkripsi yang lemah dan tempoh rendah setiap penutur.
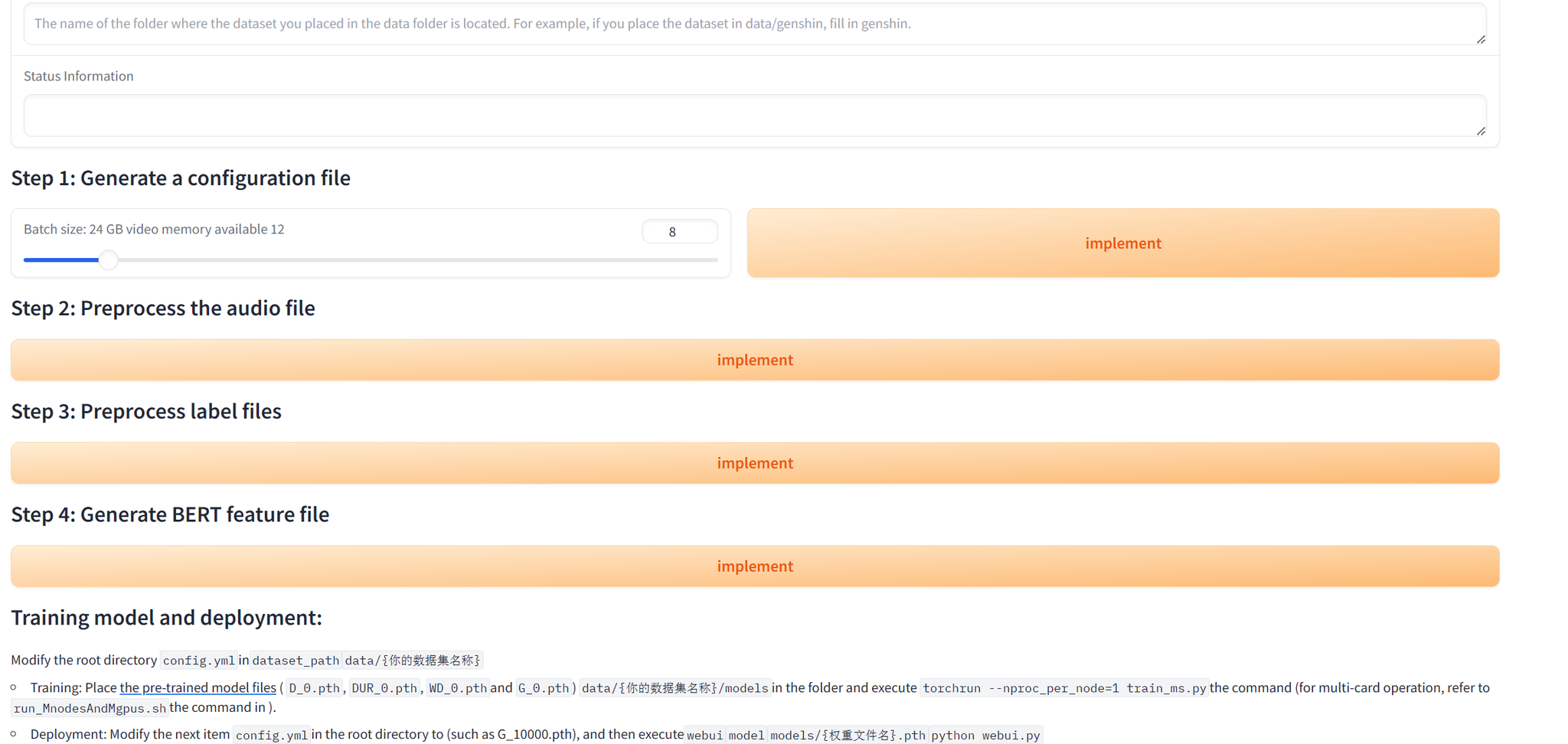
Antara muka webui pra-pemprosesan data
2.2 Seni Bina Model
Rangka kerja Bert-VITS2 terdiri daripada empat komponen utama:| Komponen | Fungsi |
|---|---|
| TextEncoder | Memproses teks input dengan BERT pra-latihan untuk pemahaman semantik |
| DurationPredictor | Menganggarkan tempoh fonem dengan variasi stokastik |
| Flow | Memodelkan pic dan tenaga menggunakan normalizing flows |
| Decoder | Mensintesis bentuk gelombang pertuturan akhir |
2.3 Proses Latihan
Fungsi Kehilangan
- Reconstruction Loss: Memadankan pertuturan yang dijana dengan kebenaran asas
- Duration Loss: Meminimumkan ralat ramalan tempoh fonem
- Adversarial Loss: Menggalakkan penjanaan pertuturan realistik
- Feature Matching Loss: Menjajarkan ciri pertengahan
Mitigasi Mode Collapse
- Gradient Penalty untuk kestabilan discriminator
- Spectral Normalization dalam generator dan discriminator
- Progressive Training dengan kerumitan yang meningkat
Hiper-parameter
3. Keputusan dan Perbincangan
Dinamik Latihan
Latihan awal menunjukkan mode collapse (menjana pertuturan kosong). Selepas penambahbaikan:- Kehilangan discriminator stabil
- Kehilangan generator menunjukkan trend menurun yang jelas
- WER menurun dari ~0.5 ke ~0.2 semasa latihan
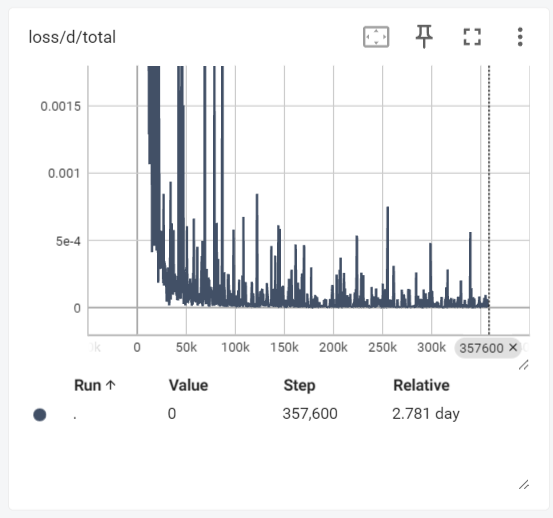
Keluk kehilangan latihan
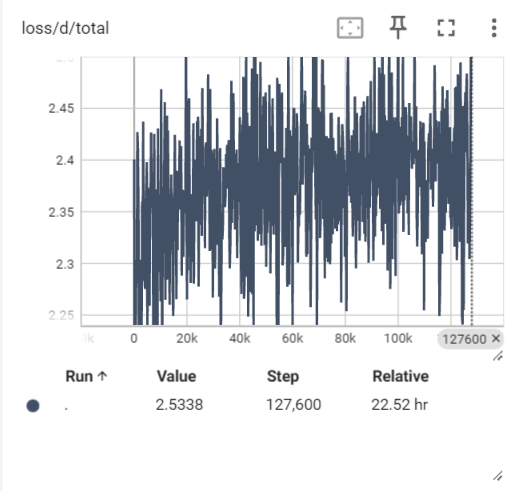
Peningkatan WER semasa latihan
Perbandingan dengan Model Lain
| Model | WER | MOS |
|---|---|---|
| Kami (Bert-VITS2) | 0.27 | 2.90 |
| myshell-ai/MeloTTS-Chinese | 5.62 | 3.04 |
| fish-speech (GPT) w/o ref | 0.49 | 3.57 |
Model kami mencapai WER terendah, menunjukkan penjanaan pertuturan yang tepat. Walau bagaimanapun, MOS (keaslian) masih boleh diperbaiki berbanding fish-speech, yang mempunyai parameter yang jauh lebih banyak.
Contoh Penjanaan
Contoh yang berjaya disintesis termasuk:- Frasa pendek (2-10 saat)
- Pertuturan bentuk panjang (22 saat) - di luar skop data latihan
Batasan
Code-switching: Model tidak dapat mengendalikan teks dengan bahasa campuran (cth., Cina dengan istilah Inggeris seperti “Speech processing”).4. Kesimpulan dan Kerja Masa Depan
Pencapaian
- Berjaya menala halus Bert-VITS2 untuk TTS Mandarin
- Mencapai WER terendah antara model yang dibandingkan
- Menguasai metodologi untuk mengurangkan cabaran latihan GAN
- Menjana pertuturan yang jelas dan boleh dikenali merentasi pelbagai tempoh
Hala Tuju Masa Depan
- Latih lebih banyak langkah untuk meningkatkan skor MOS
- Tangani batasan code-switching
- Kembangkan kepada penutur dan domain tambahan
5. Rujukan
- Ren, Y., et al. (2019). “Fastspeech: Fast, robust and controllable text to speech.” NeurIPS.
- Wang, Y., et al. (2017). “Tacotron: Towards end-to-end speech synthesis.” Interspeech.
- Kim, J., et al. (2021). “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.” ICML.
- Kong, J., et al. (2023). “VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech.” INTERSPEECH.
- Shi, Y., et al. (2020). “AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines.” ArXiv.
- Saeki, T., et al. (2022). “UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022.” INTERSPEECH.
Sumber
- Repositori Bert-VITS2: github.com/fishaudio/Bert-VITS2
- Set Data AISHELL-3: openslr.org/93