Penulis
Kai-Teh Tzeng - Lehigh UniversityAbstrak
Kajian ini meneroka penggunaan Retrieval-Augmented Fine-Tuning (RAFT) untuk meningkatkan terjemahan dwiarah Inggeris-Cina dengan Llama 3.1-8B. RAFT menggabungkan mekanisme pengambilan dengan penalaan halus untuk menyediakan contoh kontekstual semasa latihan. Penemuan Utama:- Penalaan halus penanda aras mencapai keputusan keseluruhan terbaik
- RAFT menunjukkan peningkatan sederhana pada metrik tertentu
- RAFT berasaskan rawak kadangkala mengatasi RAFT berasaskan kesamaan
- Kualiti terjemahan sangat bergantung pada relevansi data latihan
1. Pengenalan
Latar Belakang
Model Bahasa Besar cemerlang dalam tugas bahasa tetapi boleh mendapat manfaat daripada pengoptimuman khusus domain. Penyelidikan ini meneroka sama ada RAFT - teknik yang menambah latihan dengan contoh yang diambil - boleh meningkatkan kualiti terjemahan.Soalan Penyelidikan
- Bolehkah RAFT meningkatkan terjemahan berbanding penalaan halus standard?
- Adakah pengambilan berasaskan kesamaan mengatasi pengambilan rawak?
- Bagaimana konfigurasi RAFT yang berbeza mempengaruhi terjemahan dwiarah?
2. Metodologi
Gambaran Keseluruhan RAFT
RAFT (Retrieval-Augmented Fine-Tuning) meningkatkan proses latihan dengan:- Mengambil contoh yang relevan dari korpus untuk setiap sampel latihan
- Menambah konteks latihan dengan contoh yang diambil
- Menala halus model dengan konteks yang diperkaya ini
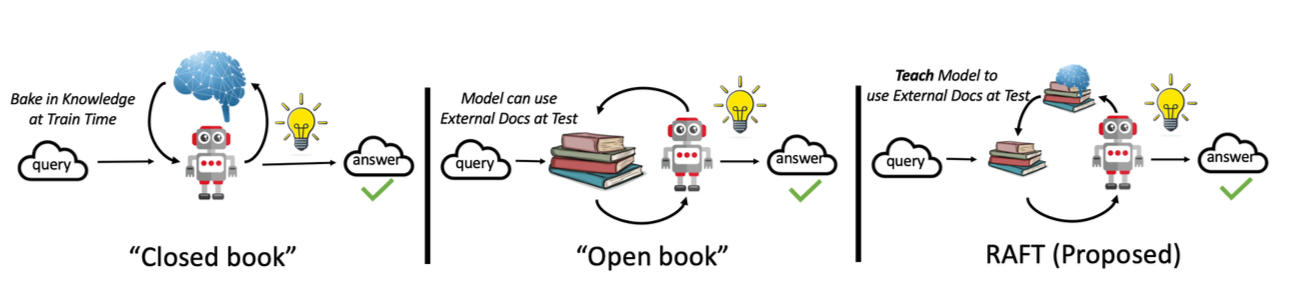
Diagram metodologi RAFT
Persediaan Eksperimen
| Komponen | Konfigurasi |
|---|---|
| Model Asas | Llama 3.1-8B Instruct |
| Penalaan Halus | LoRA (r=16, alpha=16) |
| Set Data | News Commentary v18.1 (zh-en) |
| GPU | NVIDIA A100 80GB |
Penyediaan Set Data
Set data News Commentary mengandungi pasangan ayat selari Inggeris-Cina:- Latihan: 10,000 pasangan ayat
- Penilaian: Korpus TED Talks
- Dipra-proses untuk kualiti dan konsistensi panjang
Konfigurasi RAFT
| Konfigurasi | Penerangan |
|---|---|
| Penanda Aras | Penalaan halus standard tanpa pengambilan |
| RAFT Kesamaan | Ambil contoh k teratas yang serupa menggunakan embeddings |
| RAFT Rawak | Sampel k contoh secara rawak dari korpus |
3. Keputusan
Terjemahan Inggeris-ke-Cina
| Kaedah | BLEU | COMET |
|---|---|---|
| Garis Dasar (Tanpa Penalaan Halus) | 15.2 | 0.785 |
| Penalaan Halus Penanda Aras | 28.4 | 0.856 |
| RAFT Kesamaan (k=3) | 27.1 | 0.849 |
| RAFT Rawak (k=3) | 27.8 | 0.852 |
Terjemahan Cina-ke-Inggeris
| Kaedah | BLEU | COMET |
|---|---|---|
| Garis Dasar (Tanpa Penalaan Halus) | 18.7 | 0.812 |
| Penalaan Halus Penanda Aras | 31.2 | 0.871 |
| RAFT Kesamaan (k=3) | 30.5 | 0.865 |
| RAFT Rawak (k=3) | 30.9 | 0.868 |
Penalaan halus penanda aras secara konsisten mengatasi konfigurasi RAFT dalam eksperimen ini. Ini mungkin disebabkan sifat homogen set data News Commentary.
Perbandingan prestasi latihan
Perbandingan skor BLEU dan COMET
Analisis
Mengapa RAFT tidak mengatasi penanda aras:- Kehomogenan Set Data: News Commentary mempunyai gaya yang konsisten
- Kualiti Pengambilan: Metrik kesamaan mungkin tidak menangkap ciri yang relevan untuk terjemahan
- Panjang Konteks: Contoh tambahan meningkatkan konteks, berpotensi mencairkan tumpuan
4. Kesimpulan
Walaupun RAFT menunjukkan potensi, eksperimen kami mencadangkan bahawa untuk tugas terjemahan pada set data yang homogen, penalaan halus standard kekal kompetitif. Kerja masa depan harus meneroka korpus latihan yang pelbagai dan metrik pengambilan yang lebih baik.Rujukan
- Zhang, T., et al. (2024). “RAFT: Adapting Language Model to Domain Specific RAG.”
- Lewis, P., et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”