Penulis
Aditya Sundar - Universiti WasedaAbstrak
Projek ini mencipta saluran paip automatik untuk pra-pemprosesan data video dan audio, mengekstrak maklumat utama untuk melatih model penjanaan video. Saluran paip mengendalikan pengesanan wajah, klasifikasi emosi, anggaran pose, dan pemprosesan audio. Ciri Utama:- Pengesanan dan pengasingan wajah unik automatik
- Anggaran pose kepala (yaw, pitch, roll)
- Klasifikasi emosi menggunakan pembelajaran mendalam
- Klasifikasi audio dan pengasingan pertuturan
- Penjanaan klip (segmen 3-10 saat)
1. Pengenalan
Kebangkitan model generatif berasaskan video telah mewujudkan keperluan untuk set data video pra-proses yang teguh. Projek ini mengautomasikan pra-pemprosesan data video dan audio untuk:- Mengklasifikasikan dan mengecam wajah unik secara automatik
- Mengesan emosi wajah dan pose kepala merentasi masa
- Mengklasifikasikan audio untuk muzik latar belakang dan mengasingkan pertuturan
- Memotong dan memperhalusi video untuk digunakan dalam model generatif
2. Metodologi
Gambaran Keseluruhan Saluran Paip
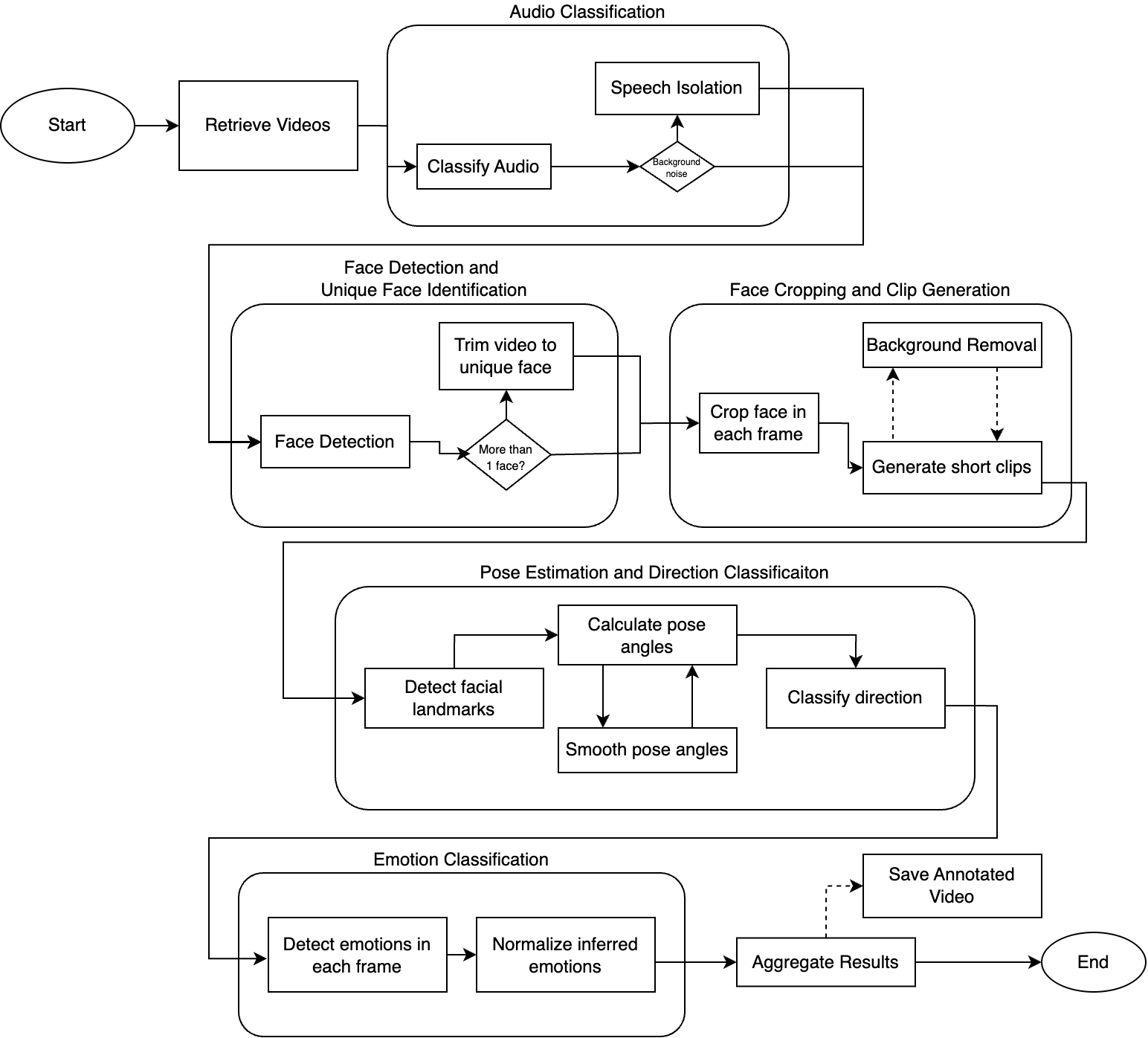
Aliran kerja saluran paip pra-pemprosesan video
| Peringkat | Fungsi |
|---|---|
| Klasifikasi Audio | Kenal pasti pertuturan dan asingkan dari bunyi latar belakang |
| Pengesanan Wajah | Kesan dan kenal pasti wajah unik dalam video |
| Pemotongan Wajah | Jana klip berfokus wajah (3-10 saat) |
| Anggaran Pose | Anggarkan orientasi kepala (yaw, pitch, roll) |
| Klasifikasi Emosi | Kesan emosi dalam setiap bingkai |
2.1 Pemprosesan Video
Video dimuat turun menggunakan yt-dlp dan diproses bingkai demi bingkai:2.2 Klasifikasi Audio
Audio diklasifikasikan menggunakan model Audio Spectrogram Transformer:- Menukar audio kepada spektrogram
- Menggunakan Vision Transformer untuk klasifikasi
- Ambang ~20% digunakan untuk mengesan bunyi latar belakang
| Jenis Video | Pertuturan % | Muzik % |
|---|---|---|
| Ulasan dengan muzik | 50.28% | 37.20% |
| Persembahan langsung | 1.50% | 46.54% |
| Temuduga berita | 82.64% | 0% |
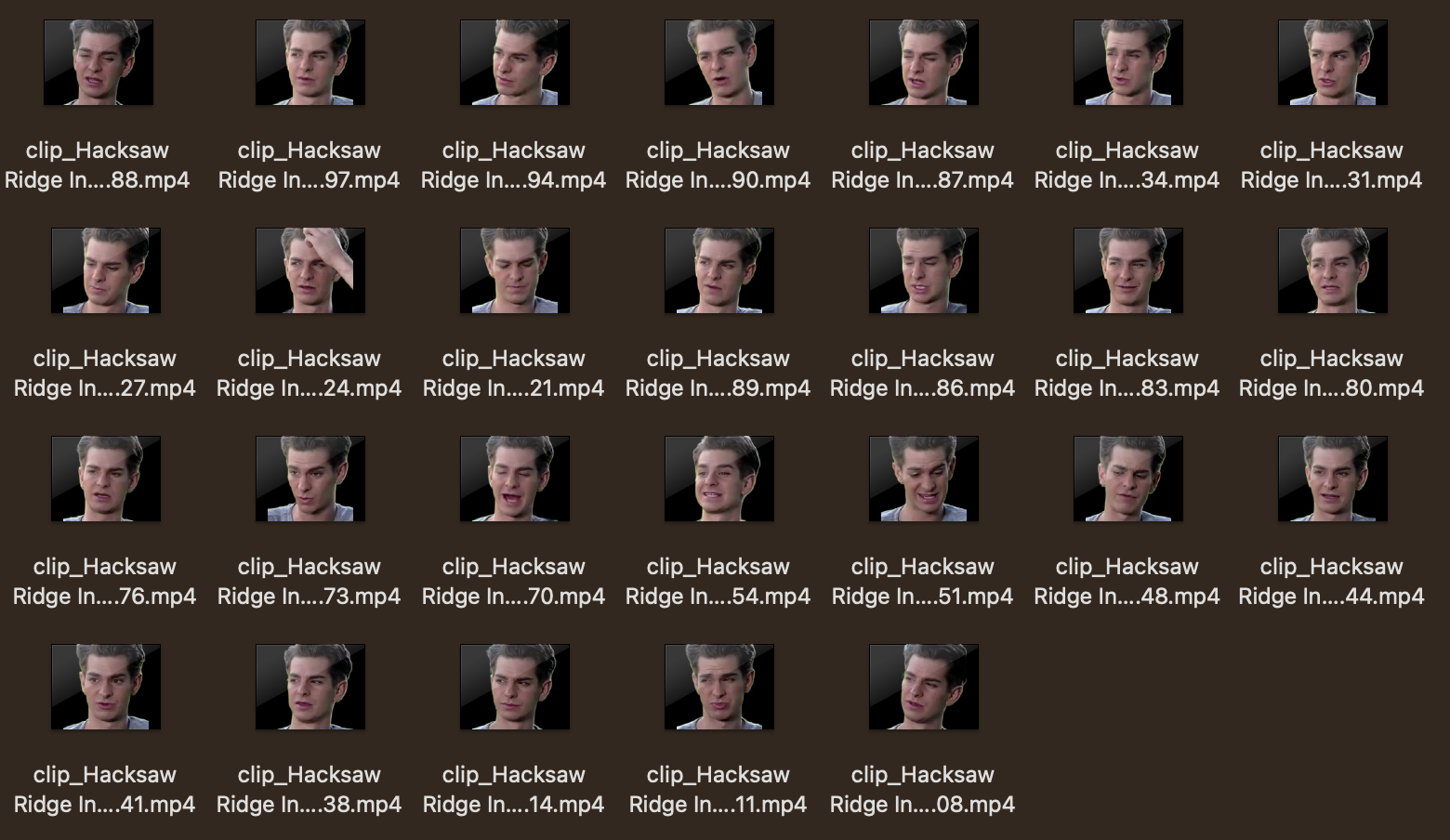
2.3 Pengesanan dan Pemotongan Wajah
Menggunakan model pengesanan wajah YuNet:- Kesan semua wajah dalam setiap bingkai
- Pilih wajah terbesar sebagai subjek
- Potong dan ubah saiz kepada dimensi yang konsisten
- Jana klip 3-10 saat
Penyingkiran latar belakang pilihan menggunakan rembg boleh mengasingkan subjek lebih lanjut.
Contoh klip wajah dipotong
Klip latar belakang dibuang
2.4 Anggaran Pose
Pose kepala dianggarkan menggunakan 68 penanda wajah:- Yaw: Putaran kiri-kanan (>10 darjah = melihat kanan/kiri)
- Pitch: Putaran atas-bawah (>10 darjah = melihat atas/bawah)
- Roll: Kecondongan kepala
2.5 Klasifikasi Emosi
Menggunakan facial_emotions_image_detection dari Hugging Face:- Mengesan: gembira, sedih, marah, neutral, takut, jijik, terkejut
- Skor dinormalisasikan untuk berjumlah 100%
- Dipuratakan merentasi keseluruhan video untuk ringkasan
3. Keputusan
Contoh Analisis Video
Video ujian: “Hacksaw Ridge Interview - Andrew Garfield” (4 min 11 saat)| Metrik | Nilai |
|---|---|
| Jumlah bingkai | 6,024 |
| FPS | 23.97 |
| Kadar pengesanan wajah | 98.26% |
| Purata wajah setiap bingkai | 1.0 |
| Klip dijana | 26 |
Klasifikasi Audio
Contoh Anggaran Pose
Klip menghadap hadapan:- Yaw: 0.65 darjah, Pitch: 4.07 darjah
- Arah: “Hadapan”

Pengesanan pose menghadap hadapan
- Yaw: 10.36 darjah, Pitch: -1.22 darjah
- Arah: “Kanan”

Pengesanan pose menghadap kanan
Klasifikasi Emosi
Model menunjukkan ketidakpastian merentasi emosi, dengan kebarangkalian tertinggi ~25%. Ini menunjukkan kerumitan pengesanan emosi dari imej wajah statik.4. Hala Tuju Masa Depan
- Klasifikasi tambahan: Pembacaan bibir, pengesanan gerak isyarat
- Percepatan GPU: Pada masa ini hanya CPU disebabkan had sumber
- Model ditala halus: Model tersuai untuk tugas tertentu
- Pengesanan emosi lanjutan: Pendekatan berbilang modal melangkaui imej statik
Rujukan
- 1adrianb/face-alignment - Pustaka penyelarasan Wajah 2D dan 3D
- ageitgey/face_recognition - API pengecaman wajah untuk Python
- CelebV-HQ - Set Data Atribut Wajah Video Skala Besar
- danielgatis/rembg - Alat penyingkiran latar belakang
- dima806/facial_emotions_image_detection - Hugging Face
- facebookresearch/demucs - Pemisahan sumber muzik
- MIT/ast-finetuned-audioset - Audio Spectrogram Transformer