TL;DR
Kami menilai tiga model diarisasi penutur merentasi enam senario:| Model | Penerangan | Purata DER | Purata RTF |
|---|---|---|---|
| NeMo Neural (MSDD) | Multi-Scale Diarization Decoder dengan penambahbaikan neural | 0.081 | 0.020 |
| NeMo Clustering | Pendekatan pengelompokan sahaja tanpa MSDD | 0.103 | 0.010 |
| Pyannote 3.1 | Saluran paip diarisasi hujung-ke-hujung | 0.181 | 0.027 |
- NeMo Neural menyediakan ketepatan terbaik dengan pemprosesan pantas
- Jepun mendapat manfaat daripada konteks lebih panjang: Prestasi bertambah baik pada audio 30min+
- Berbilang bahasa tanpa Jepun berprestasi cemerlang (DER: 0.050)
1. Pengenalan
Kami perlu memilih model diarisasi untuk pengeluaran. Penilaian kami meliputi 6 senario yang mewakili keadaan dunia sebenar:- Panjang audio berbeza (10 minit hingga 1 jam)
- Kiraan penutur berbeza (4 hingga 14 penutur)
- Tahap pertindihan berbeza (0% hingga 40%)
- Pencampuran audio berbilang bahasa
2. Model Diuji
NeMo Neural (MSDD)
- TitaNet-large untuk penyematan penutur 192-dimensi
- Memproses audio pada 5 skala temporal (tetingkap 1.0s-3.0s)
- Rangkaian neural MSDD memperhalusi keputusan pengelompokan awal
- Purata RTF: ~0.015-0.032
NeMo Clustering (Tulen)
- Model penyematan yang sama (TitaNet-large)
- Menggunakan hanya pengelompokan spektral tanpa penambahbaikan MSDD
- Jauh lebih pantas kerana melangkau penambahbaikan neural
- Purata RTF: ~0.014-0.028
Pyannote 3.1
- Saluran paip hujung-ke-hujung dengan VAD, segmentasi, dan pengelompokan
- Menggunakan model pyannote/segmentation-3.0 dan wespeaker
- Purata RTF: ~0.018-0.043
3. Persediaan Penilaian
3.1 Senario Ujian
| Senario | Tempoh | Penutur | Pertindihan | Tujuan |
|---|---|---|---|---|
| Audio Panjang | 10min | 4-5 | 15% | Pengeluaran standard |
| Sangat Panjang | 30min | 10-12 | 15% | Ujian tekanan |
| Audio 1 Jam | 60min | 12-14 | 15% | Tempoh ekstrem |
| Pertindihan Tinggi | 15min | 8-10 | 40% | Kes terburuk pertindihan |
| Berbilang bahasa (5-bahasa) | 15min | 8 | 20% | EN+JA+KO+VI+ZH |
| Berbilang bahasa (4-bahasa) | 15min | 8 | 20% | EN+KO+VI+ZH (tanpa JP) |
3.2 Metrik
Metrik Ketepatan:- DER Full (collar=0.0s): Metrik paling ketat, tiada toleransi sempadan
- DER Fair (collar=0.25s): Metrik utama dengan toleransi 250ms
- DER Forgiving (collar=0.25s, pertindihan diabaikan): Paling pemaaf
- Miss Rate: Pertuturan terlepas oleh sistem
- False Alarm Rate: Bukan pertuturan ditanda sebagai pertuturan
- Confusion Rate: Pertuturan diberikan kepada penutur yang salah
4. Prestasi Keseluruhan
4.1 Perbandingan Ketepatan
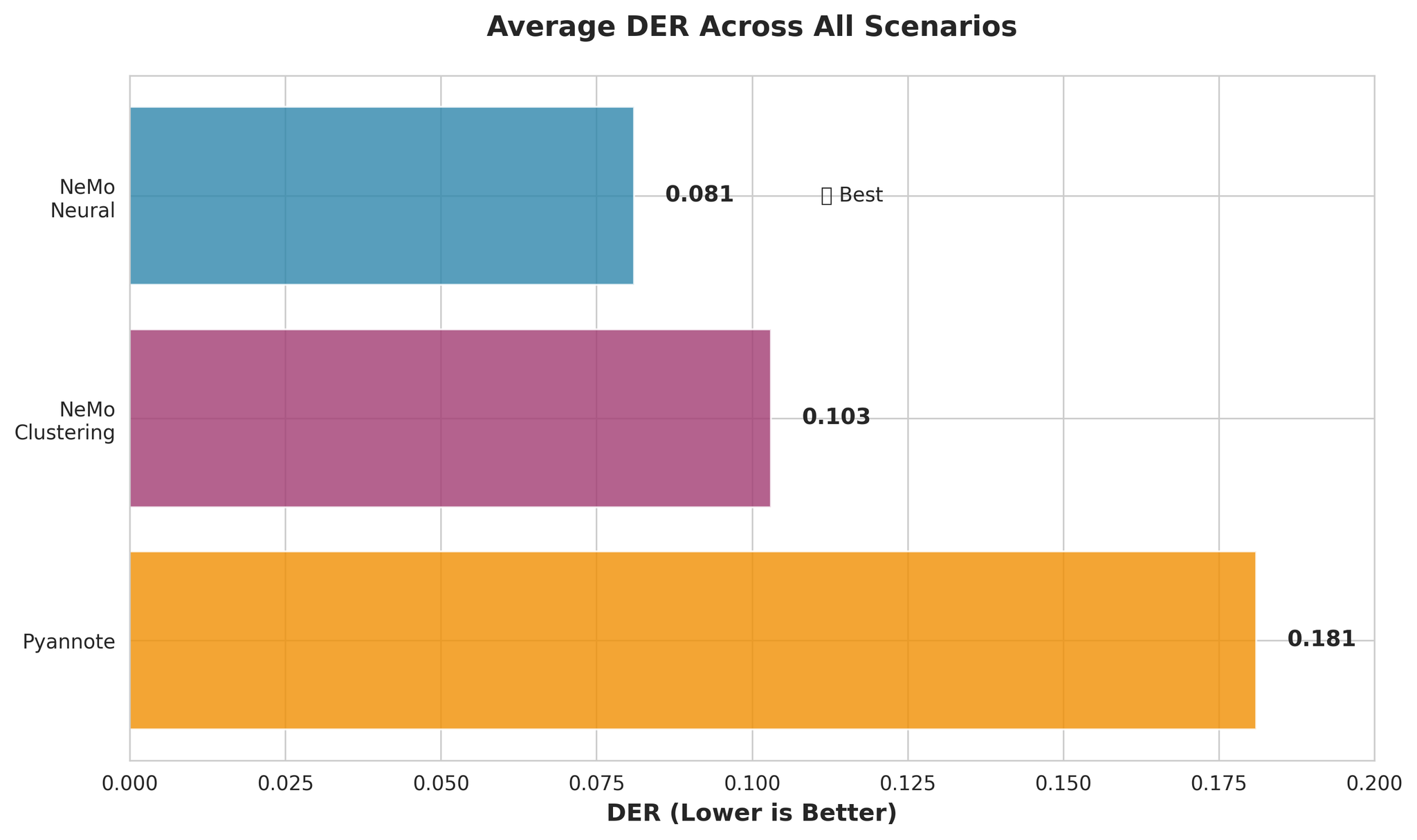
Perbandingan DER keseluruhan merentasi semua senario
- NeMo Neural ~55% lebih tepat daripada Pyannote (DER: 0.081 vs 0.181)
- NeMo Clustering berprestasi hampir sama baiknya dengan Neural (hanya 27% lebih teruk)
- Pyannote mempunyai kadar kekeliruan 3.4x lebih tinggi
4.2 Perbandingan Kelajuan
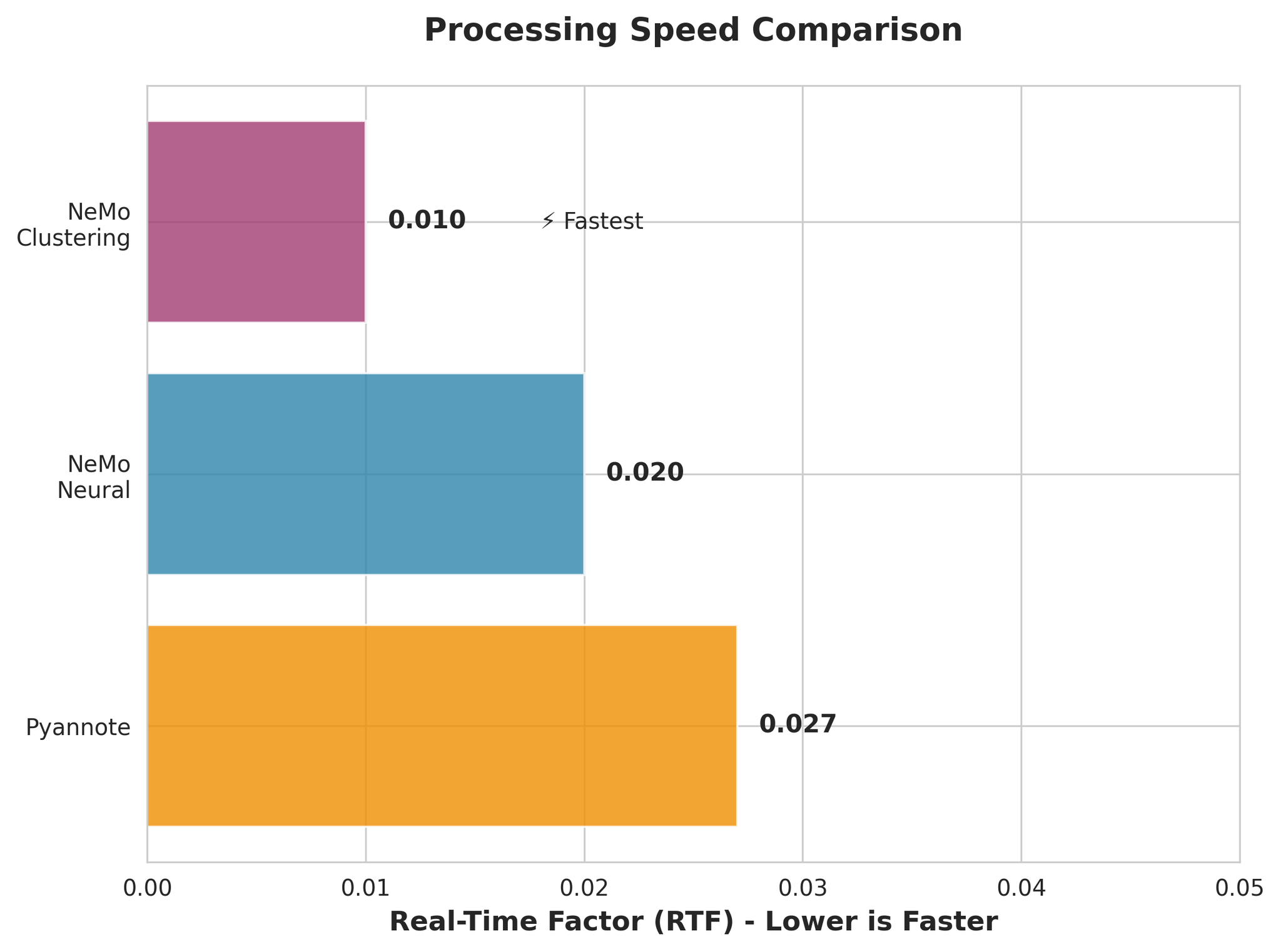
Perbandingan kelajuan pemprosesan (RTF - lebih rendah lebih pantas)
- NeMo Clustering adalah terpantas (RTF 0.010)
- NeMo Neural sangat pantas (RTF 0.020)
- Semua model jauh lebih pantas daripada masa nyata
4.3 Pertukaran Ketepatan vs Kelajuan
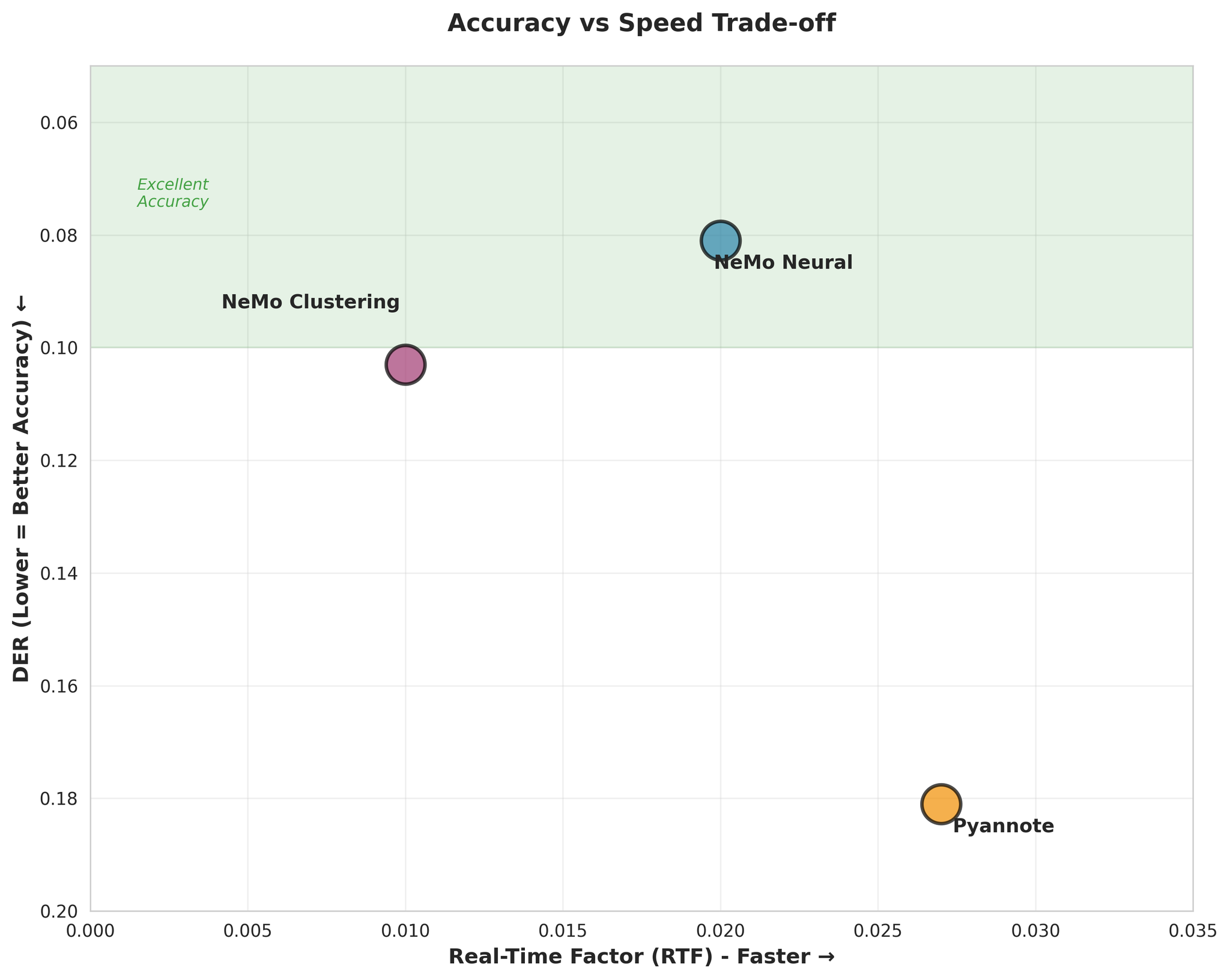
Visualisasi pertukaran Ketepatan vs Kelajuan
5. Keputusan mengikut Senario
5.1 Audio Panjang (10 minit)
Keputusan NeMo Neural mengikut Bahasa:- EN: 0.019 (Cemerlang)
- JA: 0.157 (8.3x lebih sukar daripada Inggeris)
- KO: 0.046
- VI: 0.037
- ZH: 0.053
- Purata: 0.062
5.2 Audio Sangat Panjang (30 minit)
Penemuan Kritikal - Jepun Mendapat Manfaat daripada Konteks Lebih Panjang:- Audio 10min: DER 0.157 (8.3x lebih sukar daripada Inggeris)
- Audio 30min: DER 0.067 (2.9x lebih sukar daripada Inggeris)
5.3 Pertindihan Tinggi (40%)
- NeMo Neural dan Clustering berprestasi hampir sama (DER: 0.114 vs 0.115)
- Pyannote lebih sukar (DER: 0.202, ~77% lebih teruk daripada NeMo)
- Jepun kekal bahasa paling sukar (DER: 0.232)
6. Analisis Khusus Bahasa
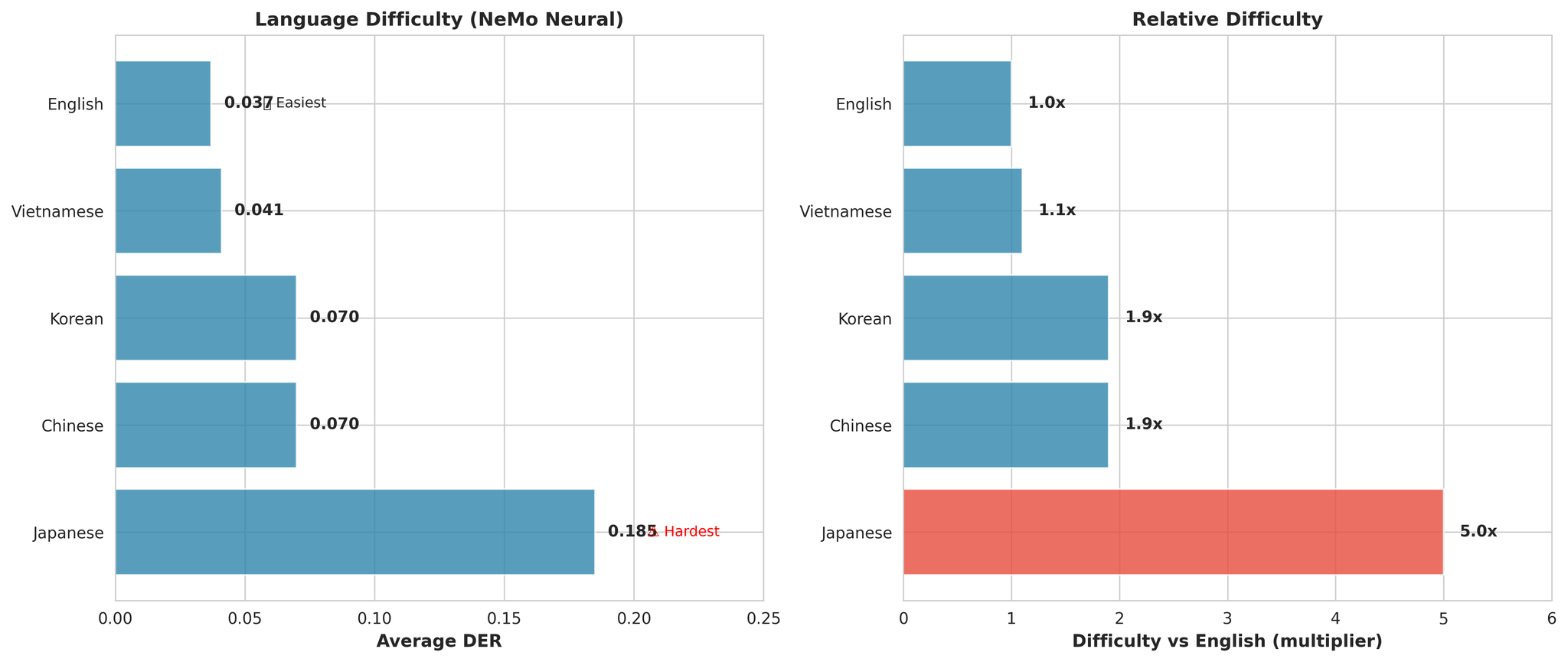
Kedudukan kesukaran bahasa keseluruhan
- Jepun adalah paling sukar secara universal (5.0x lebih sukar daripada Inggeris secara purata)
- Inggeris adalah paling mudah (DER: 0.037)
- Vietnam adalah kedua hampir (hanya 1.1x lebih sukar daripada Inggeris)
Mengapa Jepun Sukar
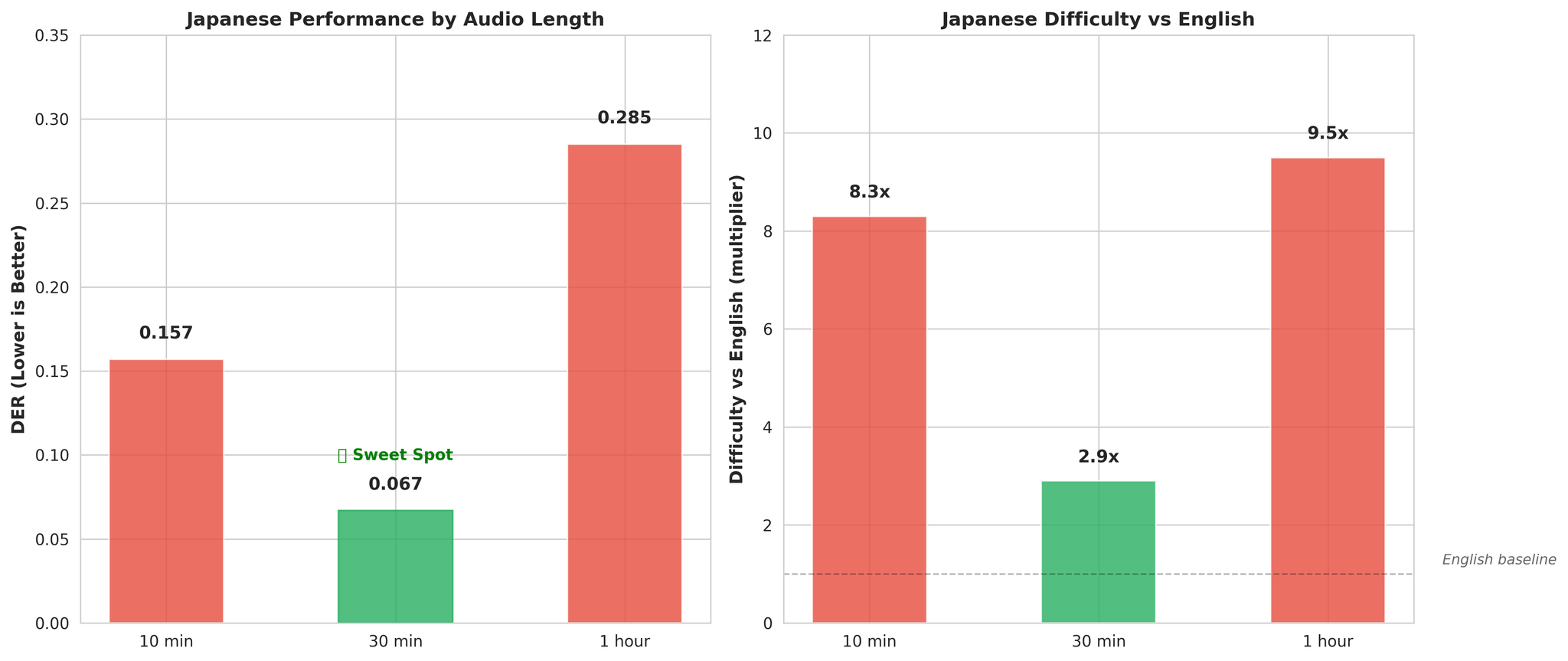
Prestasi Jepun merentasi panjang audio berbeza
- Bahasa aksen pic: Pic membawa makna linguistik, mengelirukan penyematan penutur
- Inventori fonetik sempit: ~100 mora vs ribuan fonem Inggeris
- Tempoh suku kata lebih pendek: Kurang konteks temporal setiap giliran bercakap
7. Neural vs Clustering
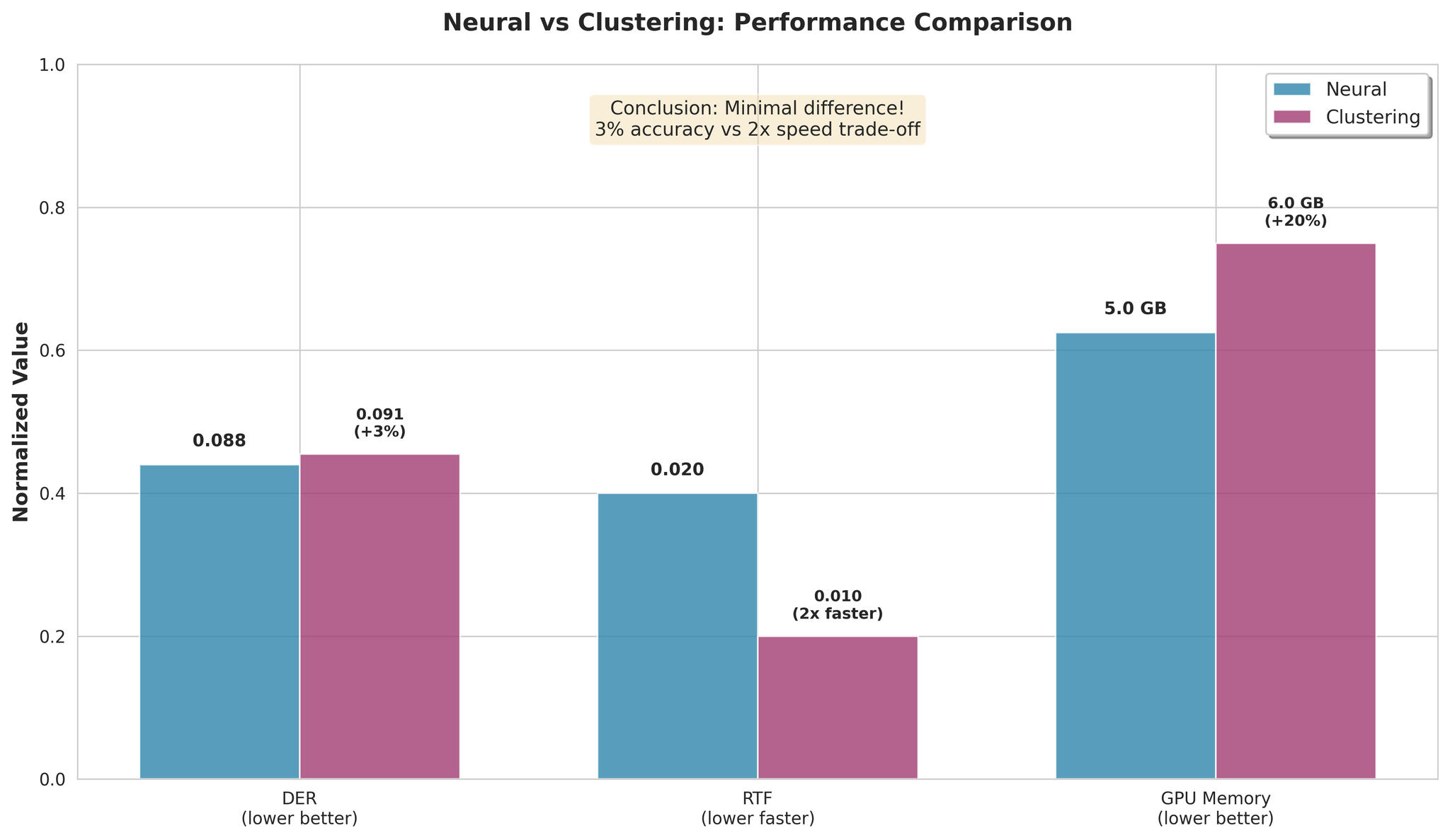
Perbandingan prestasi Neural vs Clustering
- Clustering hanya 3% lebih teruk secara purata
- Clustering 2x lebih pantas dalam pemprosesan
- Pertukaran kelajuan/ketepatan adalah minimum
- Gunakan NeMo Neural untuk ketepatan terbaik
- Gunakan NeMo Clustering untuk kelajuan maksimum (2x lebih pantas, 3% lebih teruk)
8. Prestasi Berbilang Bahasa
8.1 Kesan Jepun
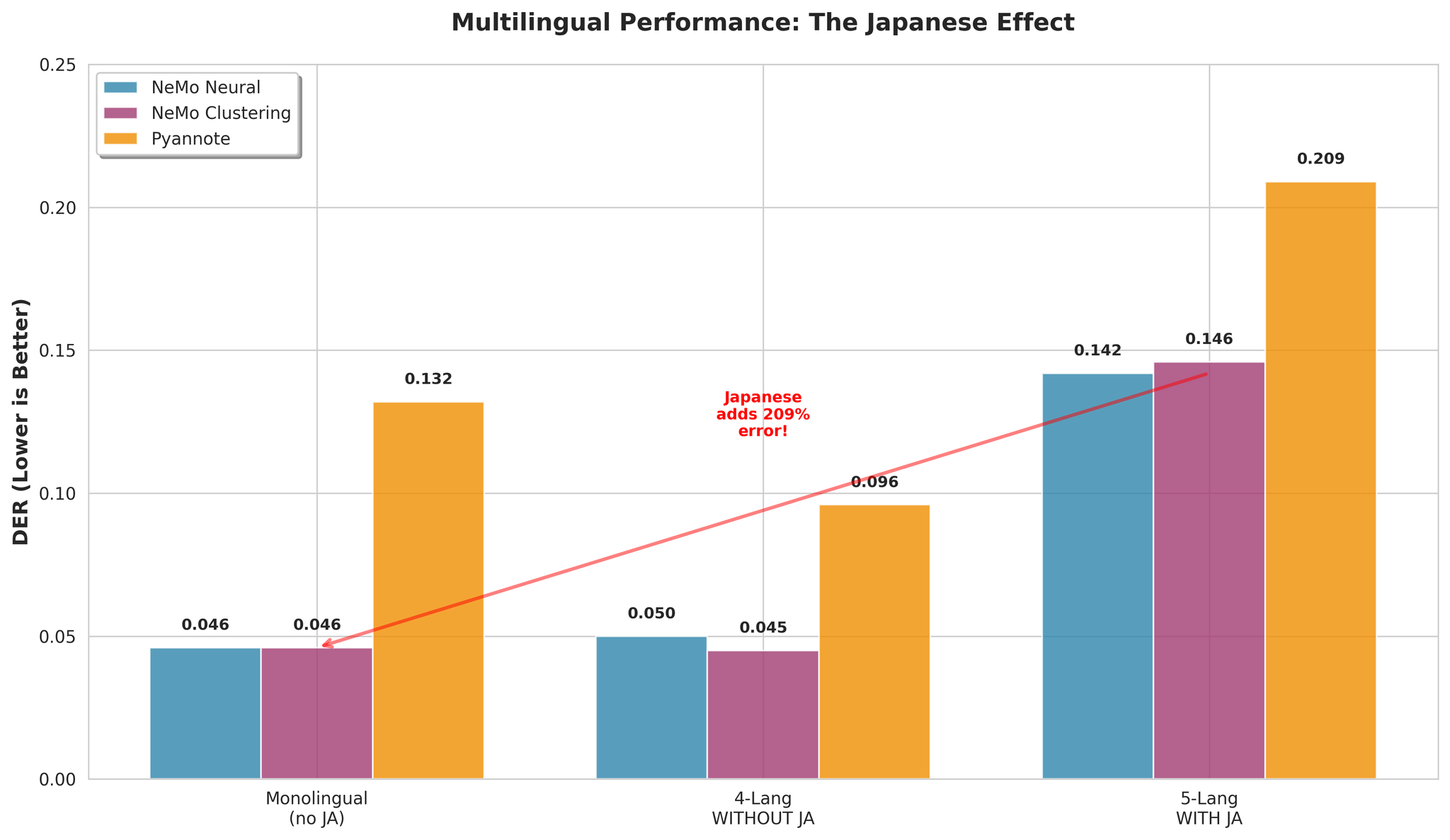
Prestasi berbilang bahasa dengan dan tanpa Jepun
| Konfigurasi | DER NeMo Neural |
|---|---|
| Dengan Jepun (5-bahasa) | 0.142 |
| Tanpa Jepun (4-bahasa) | 0.050 |
8.2 Analisis Ralat
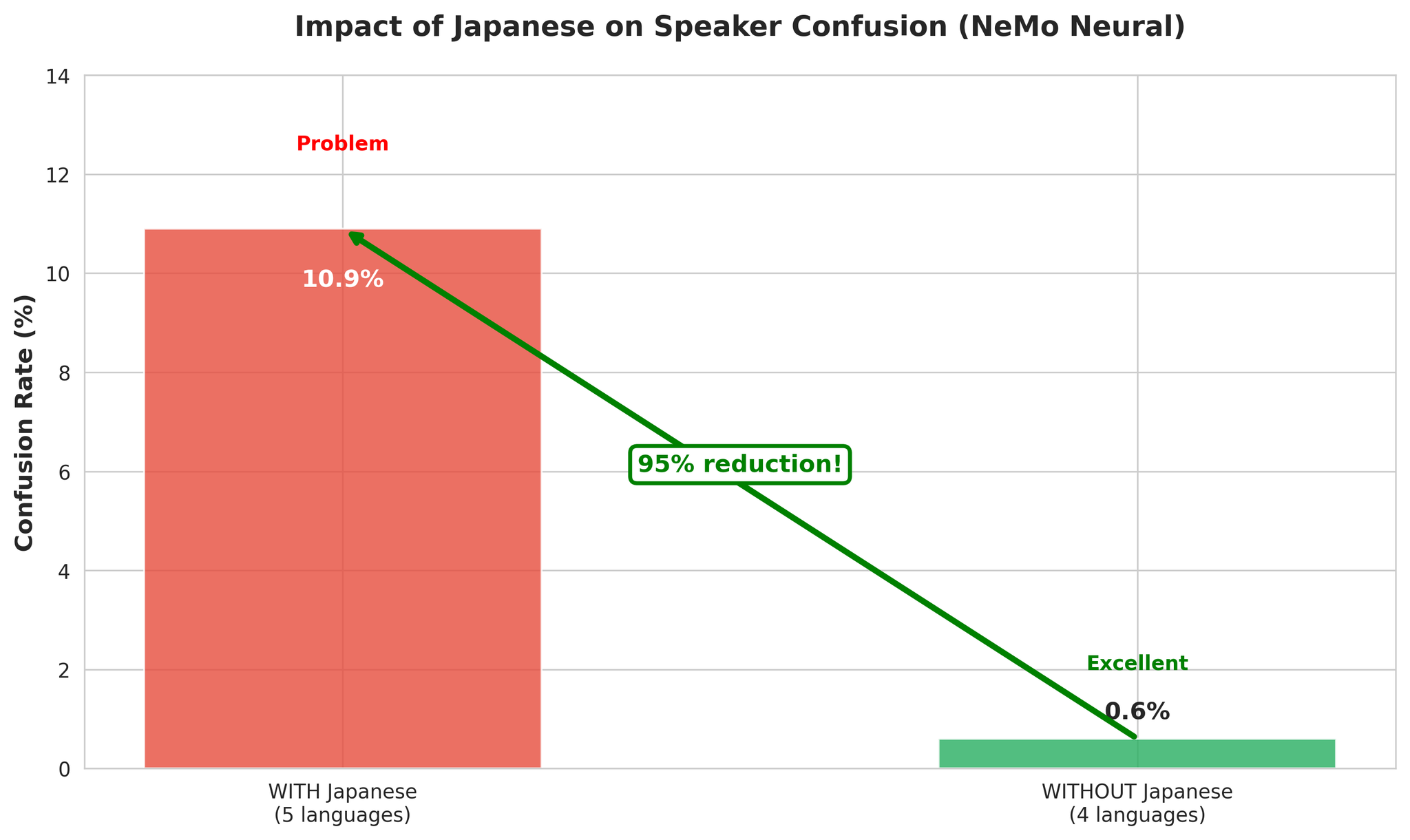
Pecahan ralat dengan vs tanpa Jepun
- Lebih banyak kepelbagaian akustik membantu VAD mengesan sempadan pertuturan
- Perubahan bahasa menyediakan sempadan segmen semula jadi
- EN, KO, VI, ZH mempunyai ciri akustik yang serasi
- Ciri aksen pic Jepun menyebabkan kekeliruan penutur merentas bahasa
9. Kesimpulan
Pengambilan Utama
NeMo Neural adalah pemenang jelas:- Ketepatan terbaik: DER 0.081 purata
- Pemprosesan pantas: RTF 0.020 (50x lebih pantas daripada masa nyata)
- Cemerlang berbilang bahasa tanpa Jepun: DER 0.050
- Jepun mendapat manfaat secara dramatik daripada konteks lebih panjang (30min optimum)
- Berbilang bahasa dengan Jepun adalah mencabar (DER 0.142) tetapi boleh diurus
- Penambahbaikan neural MSDD menyediakan manfaat minimum berbanding pengelompokan (27% lebih baik)
- Semua model adalah pantas dan sedia pengeluaran
Cadangan
| Kes Penggunaan | Model | Sebab |
|---|---|---|
| Ketepatan terbaik | NeMo Neural | DER 0.081 |
| Kelajuan maksimum | NeMo Clustering | 2x lebih pantas |
| Audio panjang (30min-1j) | NeMo Neural | Mengendalikan kerumitan |
| Berbilang bahasa (tanpa Jepun) | NeMo Neural | DER 0.050 |
| Jepun (30min+) | NeMo Neural | Konteks membantu |