Author
Ashar Mirza - VoicePing Inc.Recap: Problem
Part 1 တွင် bottleneck ကို identify လုပ်ခဲ့ပါသည်: ကျွန်ုပ်တို့၏ FastAPI service သည် translation tasks distribute လုပ်ရန် IPC queues ပါဝင်သော multiprocessing workers အသုံးပြုခဲ့ပါသည်။ ၎င်းသည်:- Queue serialization overhead
- Worker processes များအကြား GPU compute contention
- Spiky GPU utilization pattern ဖန်တီးခဲ့ပါသည်
Attempt 2: Static Batching
Existing worker processes အတွင်း static batching implement လုပ်ခဲ့ပါသည်။Results
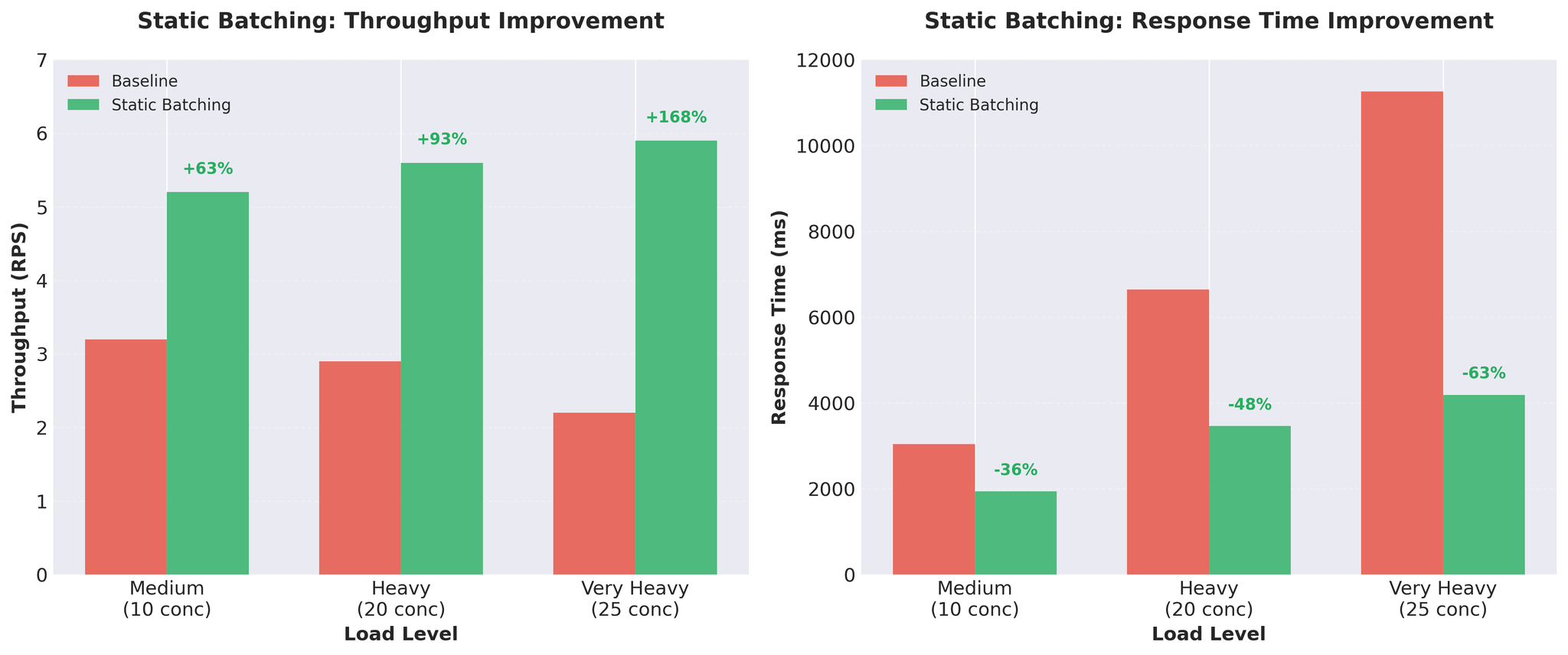
Figure 1: Significant throughput နှင့် response time improvements ပေးသော Static batching
Trade-offs
Pros:- Massive throughput gains
- GPU better utilized
- Simple implementation
- Head-of-line blocking: Requests အားလုံးသည် slowest one စောင့်ရသည်
- Variable-length inputs ဖြင့် short translations များသည် long ones စောင့်ရသည်
Attempt 3: Continuous Batching
Solution: vLLM ၏ AsyncLLMEngine with continuous batching။Continuous Batching ဆိုသည်မှာ
Static batching နှင့် မတူဘဲ continuous batching သည် batches ကို dynamically compose လုပ်သည်:- New requests များသည် mid-generation တွင် join ဖြစ်သည်
- Completed requests များသည် ချက်ချင်း leave ဖြစ်သည် (others စောင့်ရန် မလိုပါ)
- Batch composition သည် token တိုင်း update ဖြစ်သည်
- vLLM ၏ AsyncLLMEngine သည် ၎င်းကို automatically handle လုပ်သည်
Configuration Tuning
ကျွန်ုပ်တို့ တွေ့ရှိသည်
- Actual workload: server တစ်ခုလျှင် 2-20 concurrent requests (production peak ~20 per server)
- Configuration: max_num_seqs=64
- Result: overhead create လုပ်သော 60+ empty slots
- 64 sequences အတွက် KV cache pre-allocated
- vLLM scheduler သည် 64 slots manage လုပ်သော်လည်း 5-10 သာ အသုံးပြုသည်
- Token တစ်ခုလျှင် decode time တိုးသည်
- Unused sequence slots များတွင် memory waste ဖြစ်သည်
Final Configuration
| max_num_seqs | Result |
|---|---|
| 8 | Good latency, but throughput limited |
| 16 | Best balance |
| 32 | Decode time increased, tail latency worse |
- Production peak: server တစ်ခုလျှင် ~20 concurrent requests
- Testing: 25 concurrent အထိ validated
- Resources waste မဖြစ်ဘဲ headroom ပေးသည်
Principle: configuration ကို theoretical limits မဟုတ်ဘဲ actual workload နှင့် match ပြုလုပ်ပါ။
Production Results
Optimized configuration ကို production (RTX 5090 GPUs) သို့ deploy လုပ်ခဲ့ပါသည်။Before vs After
| Metric | Before (Multiprocessing) | After (Optimized AsyncLLM) | Change |
|---|---|---|---|
| Throughput | 9.0 RPS | 16.4 RPS | +82% |
| GPU Utilization | Spiky (93% -> 0% -> 93%) | Consistent 90-95% | Stable |
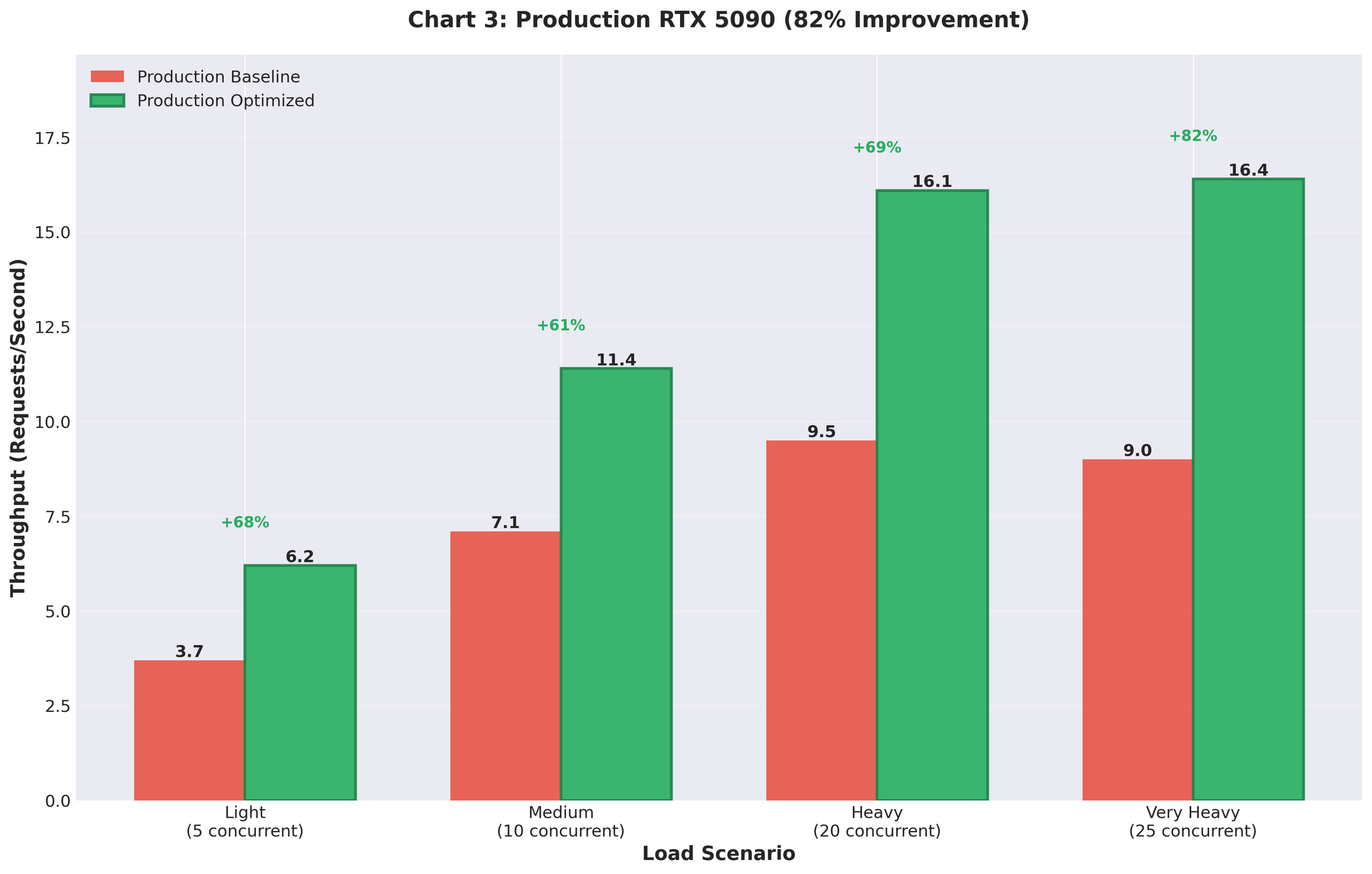
Figure 5: 82% throughput improvement ပြသော production deployment results
Summary
ဘာက Work ဖြစ်ခဲ့သလဲ
vLLM ၏ continuous batching- AsyncLLMEngine သည် batching ကို automatically handle လုပ်သည်
- Manual batch collection overhead မရှိ
- FastAPI နှင့် direct async/await integration
- max_num_seqs=16 (server တစ်ခုလျှင် actual workload နှင့် matched)
- 64 မဟုတ် (overhead create လုပ်သော theoretical max)
- Variable-length inputs သည် configuration issues ထုတ်ပြသည်
- Uniform test data သည် misleading 15 RPS ပေးခဲ့သည်
Complete Journey
| Approach | Throughput | vs Baseline | Notes |
|---|---|---|---|
| Baseline (multiprocessing) | 2.2 RPS | - | IPC overhead, GPU contention |
| Two workers | 2.0 RPS | -9% | Worse ဖြစ်စေခဲ့သည် |
| Static batching | 5.9 RPS | +168% | Head-of-line blocking |
| Async (64, uniform) | 15.0 RPS | +582% | Misleading test data |
| Async (16, variable) | 3.5 RPS | +59% | Realistic, tuning လိုအပ်သည် |
| Final optimized | 10.7 RPS | +386% | Staging validation |
| Production | 16.4 RPS | +82% | Real traffic, RTX 5090 |