1. Introduction
Large language models (LLMs) သည် input-label pairs များပေါ် conditioning ခြင်းဖြင့် downstream tasks များတွင် impressive proficiency ပြသခဲ့ပါသည်။ ဤ inference mode ကို in-context learning ဟု ခေါ်ပါသည် (Brown et al. 2020)။ GPT-4 သည် specific task examples ပေးခြင်းဖြင့် fine-tuning မလုပ်ဘဲ ၎င်း၏ translation capabilities များကို improve လုပ်နိုင်ပါသည်။
Figure 1: Few-shot examples အသုံးပြု၍ Chinese to English translation အတွက် In-context learning
2. Proposed Method
ဤ methodology သည် translation pairs ပါဝင်သော dataset Ds သို့ access ရှိသည်ဟု ယူဆပါသည်။ Text retriever (Gao 2023) သည် user prompt နှင့် meaning တူညီသော top K sentences များကို locate ပြီး select လုပ်ပါသည်။ Retriever တွင် components နှစ်ခု ပါဝင်ပါသည်:- TF-IDF Matrix - term frequency နှင့် inverse document frequency တိုင်းတာသည်
- Cosine Similarity - TF-IDF vectors များအကြား similarity တိုင်းတာသည်
TF-IDF Score
TF-IDF scores သည် documents အတွင်း words များ၏ significance ကို တိုင်းတာပါသည်:- TF (Term Frequency): Word တစ်ခု document တွင် မည်မျှ မကြာခဏ ပေါ်သည်
- IDF (Inverse Document Frequency): Corpus တစ်ခုလုံးတွင် word ၏ significance
Cosine Similarity
Cosine similarity သည် vectors နှစ်ခုအကြား similarity ကို ၎င်းတို့၏ representations များအကြား angle consider လုပ်ခြင်းဖြင့် assess လုပ်ပါသည်။3. Experimental Setup
Experimental Procedure
Experiment သည် scenarios သုံးခုကို cover လုပ်ပါသည်:- No ICL: In-context learning examples မပါဘဲ GPT-4 translation
- Random ICL: Translation examples များ random selection
- Proposed Method: TF-IDF retriever သည် similarity scores အပေါ်အခြေခံ၍ top 4 examples select လုပ်သည်
Evaluation Metrics
- BLEU Score: Translated segments များကို reference translations နှင့် compare လုပ်သည်
- COMET Score: Human judgments နှင့် state-of-the-art correlation ရရှိသော multilingual MT evaluation အတွက် Neural framework
Datasets
OPUS-100 (Zhang et al. 2020) ကို ရွေးချယ်ခဲ့ပါသည်:- Diverse translation language pairs ပါဝင်သည် (ZH-EN, JA-EN, VI-EN)
- Effective example selection အတွက် diverse domains cover လုပ်သည်
4. Results and Discussion
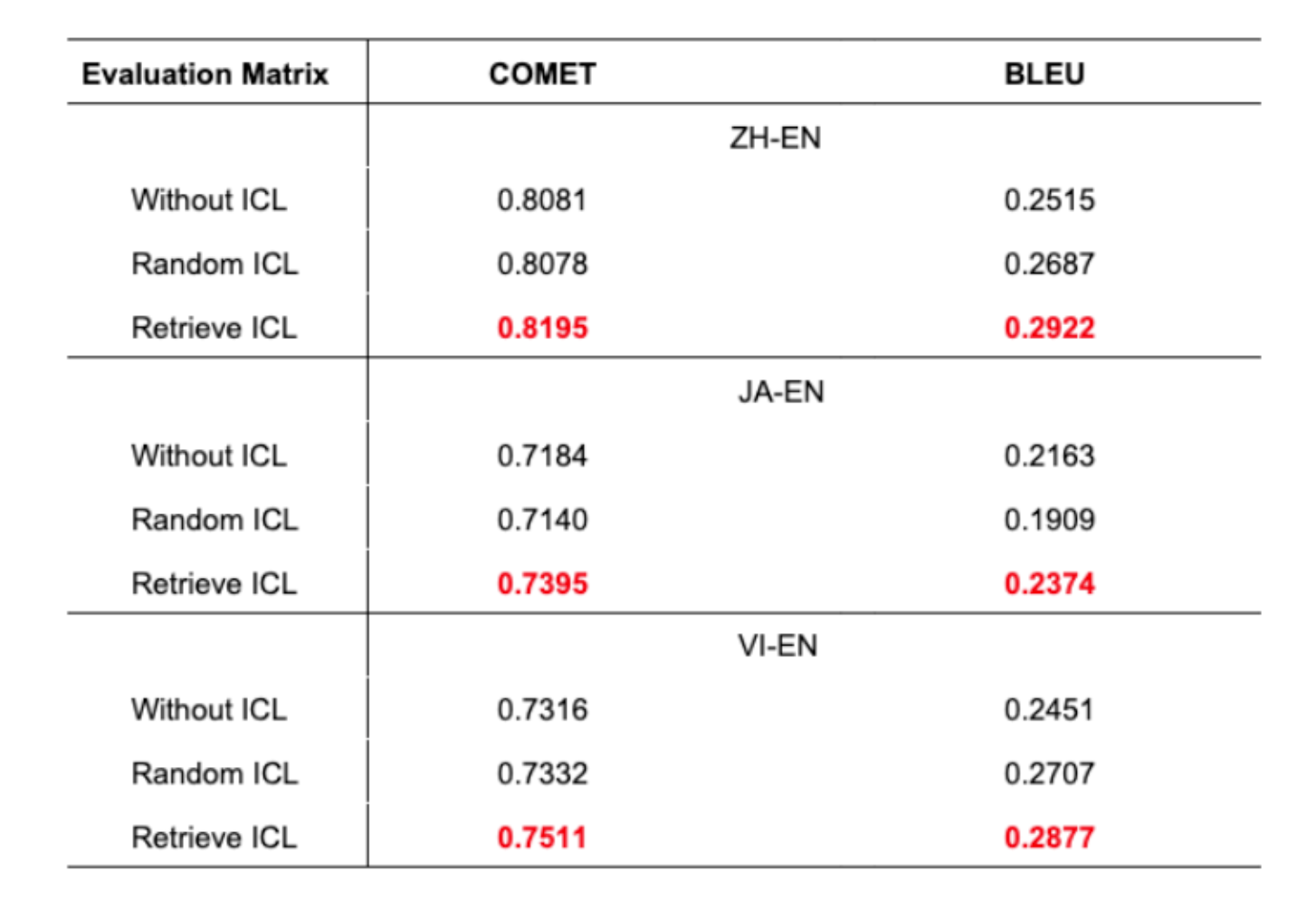
Table 1: Language pairs အားလုံးအတွက် scenarios သုံးခုတွင် Translation accuracy
- Proposed approach သည် language pairs အားလုံးတွင် superior translation accuracy ပြသည်
- Machine translation တွင် BLEU score 1% improvement သည် significant ဖြစ်သည်
- Random ICL သည် တခါတရံ ICL မပါခြင်းထက် ပိုဆိုးသည်
- ၎င်းသည် judicious example selection ၏ အရေးပါမှုကို highlight လုပ်သည်
5. Conclusion and Next Steps
ဤစာတမ်းသည် TF-IDF retrieval ဖြင့် in-context learning မှတစ်ဆင့် GPT-4 translation enhance လုပ်ရန် method တစ်ခု introduce လုပ်ပါသည်။ Approach သည်:- TF-IDF matrix နှင့် cosine similarity အသုံးပြု၍ retriever construct လုပ်သည်
- User prompts နှင့် closely align ဖြစ်သော sentences များ select လုပ်သည်
- BLEU နှင့် COMET scores နှစ်ခုလုံးတွင် improvements ပြသည်
- Dataset Construction: Domains များတွင် comprehensive, high-quality translation datasets ဖန်တီးခြင်း
- Example Quantity: 4 အစား examples 5 သို့မဟုတ် 10 အသုံးပြုခြင်း၏ impact investigate လုပ်ခြင်း
References
- Brown, T., et al. (2020). “Language models are few-shot learners.”
- Xie, S. M., et al. (2022). “An Explanation of In-context Learning as Implicit Bayesian Inference.”
- Papineni, K., et al. (2002). “BLEU: A method for automatic evaluation of machine translation.”
- Rei, R., et al. (2020). “COMET: A Neural Framework for MT Evaluation.”