TL;DR
Speaker diarization models သုံးခုကို scenarios ခြောက်ခုတွင် evaluate လုပ်ခဲ့ပါသည်:| Model | Description | Avg DER | Avg RTF |
|---|---|---|---|
| NeMo Neural (MSDD) | Neural refinement ပါဝင်သော Multi-Scale Diarization Decoder | 0.081 | 0.020 |
| NeMo Clustering | MSDD မပါဝင်သော Clustering-only approach | 0.103 | 0.010 |
| Pyannote 3.1 | End-to-end diarization pipeline | 0.181 | 0.027 |
- NeMo Neural သည် fast processing ဖြင့် best accuracy ပေးသည်
- Japanese သည် longer context မှ benefit ရသည်: 30min+ audio တွင် Performance တိုးတက်သည်
- Japanese မပါဝင်သော Multilingual သည် ကောင်းမွန်စွာ perform လုပ်သည် (DER: 0.050)
1. Introduction
Production အတွက် diarization model ရွေးချယ်ရန် လိုအပ်ခဲ့ပါသည်။ ကျွန်ုပ်တို့၏ evaluation သည် real-world conditions များကို ကိုယ်စားပြုသော scenarios 6 ခုကို cover လုပ်ပါသည်:- Audio lengths အမျိုးမျိုး (10 minutes to 1 hour)
- Speaker counts အမျိုးမျိုး (4 to 14 speakers)
- Overlap levels အမျိုးမျိုး (0% to 40%)
- Multilingual audio mixing
2. Models Under Test
NeMo Neural (MSDD)
- 192-dimensional speaker embeddings အတွက် TitaNet-large
- Temporal scales 5 ခုတွင် (1.0s-3.0s windows) audio process လုပ်သည်
- MSDD neural network သည် initial clustering results များကို refine လုပ်သည်
NeMo Clustering (Pure)
- တူညီသော embedding model (TitaNet-large)
- MSDD refinement မပါဘဲ spectral clustering သာ အသုံးပြုသည်
- Neural refinement skip လုပ်သောကြောင့် သိသိသာသာ ပိုမြန်သည်
Pyannote 3.1
- VAD, segmentation နှင့် clustering ပါဝင်သော End-to-end pipeline
- pyannote/segmentation-3.0 နှင့် wespeaker models အသုံးပြုသည်
3. Evaluation Setup
Test Scenarios
| Scenario | Duration | Speakers | Overlap | Purpose |
|---|---|---|---|---|
| Long Audio | 10min | 4-5 | 15% | Standard production |
| Very Long | 30min | 10-12 | 15% | Stress test |
| 1-Hour Audio | 60min | 12-14 | 15% | Extreme duration |
| High Overlap | 15min | 8-10 | 40% | Worst-case overlap |
| Multilingual (5-lang) | 15min | 8 | 20% | EN+JA+KO+VI+ZH |
| Multilingual (4-lang) | 15min | 8 | 20% | EN+KO+VI+ZH (no JP) |
Metrics
Accuracy Metrics:- DER Full (collar=0.0s): Strictest metric, boundary tolerance မပါ
- DER Fair (collar=0.25s): 250ms tolerance ပါဝင်သော primary metric
- DER Forgiving (collar=0.25s, overlap ignored): Most lenient
4. Overall Performance
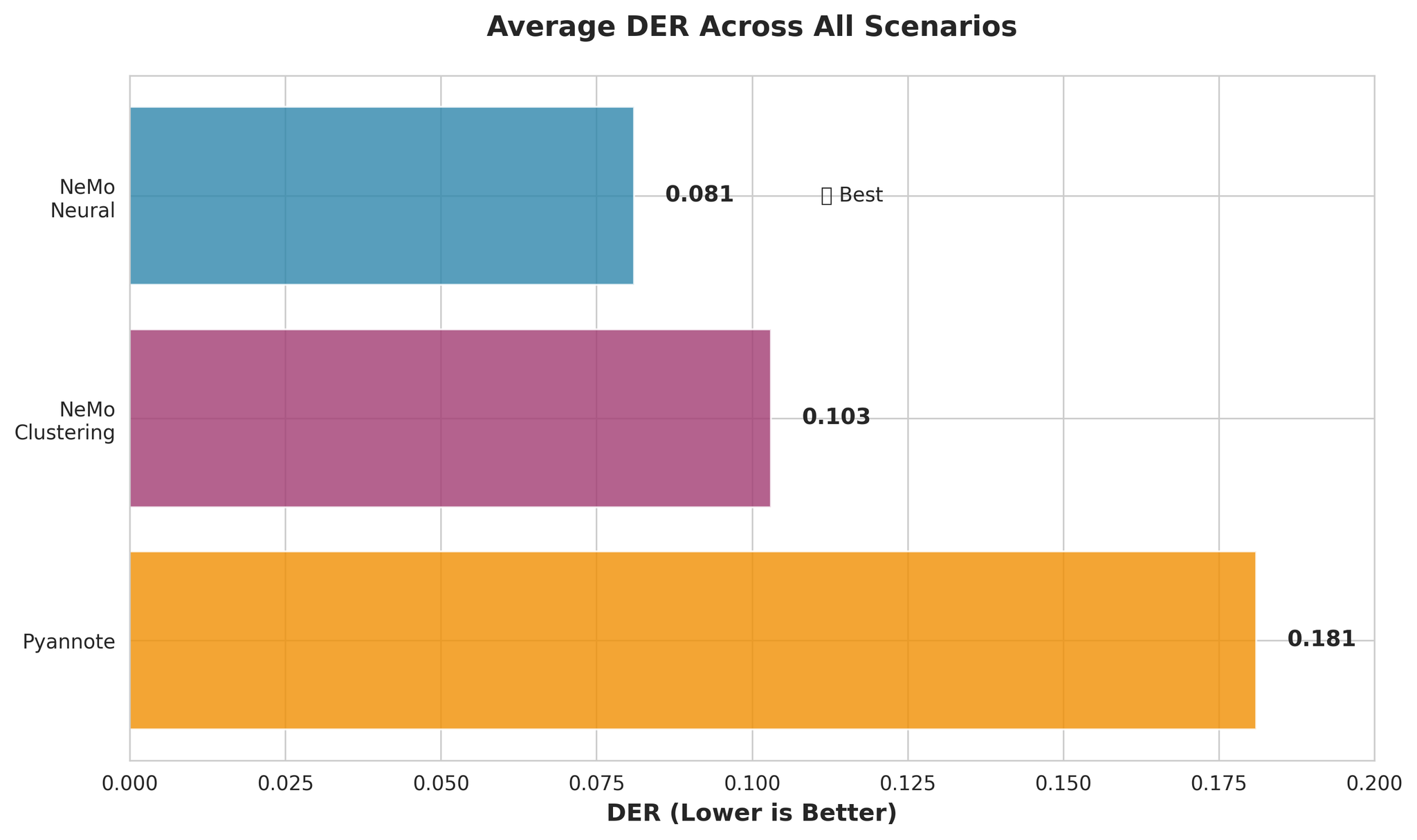
Scenarios အားလုံးတွင် Overall DER comparison
- NeMo Neural သည် Pyannote ထက် ~55% ပိုမိုတိကျသည် (DER: 0.081 vs 0.181)
- NeMo Clustering သည် Neural နီးပါး ကောင်းမွန်စွာ perform လုပ်သည် (27% သာ ပိုဆိုးသည်)
- Pyannote သည် 3.4x higher confusion rate ရှိသည်
5. Language-Specific Analysis
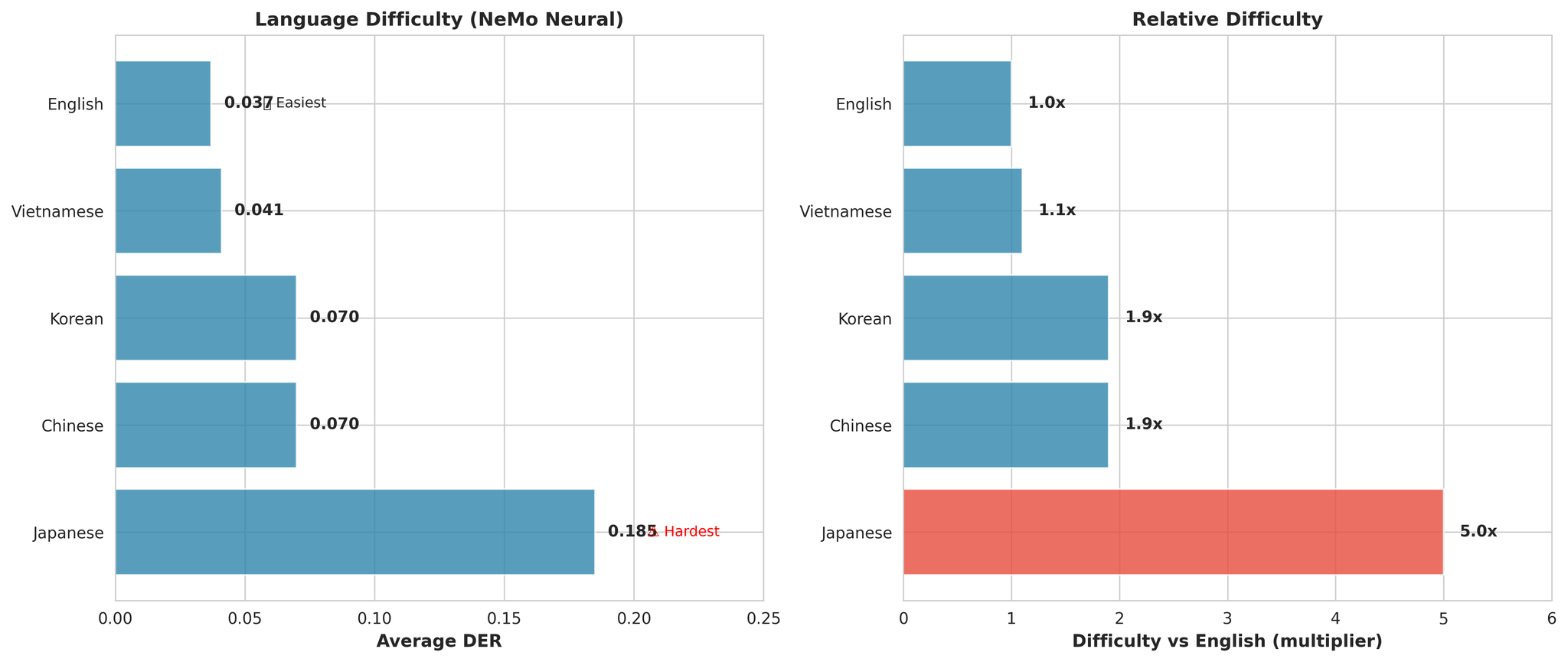
Overall language difficulty ranking
- Japanese သည် universally အခက်ဆုံးဖြစ်သည် (English ထက် ပျမ်းမျှ 5.0x ပိုခက်သည်)
- English သည် အလွယ်ဆုံးဖြစ်သည် (DER: 0.037)
- Vietnamese သည် ဒုတိယ ကောင်းသည် (English ထက် 1.1x သာ ပိုခက်သည်)
Japanese ဘာကြောင့် ခက်ခဲသလဲ
ယူဆချက်များ:- Pitch-accent language: Pitch သည် linguistic meaning ဆောင်သောကြောင့် speaker embeddings များကို ရှုပ်ထွေးစေသည်
- Narrow phonetic inventory: English phonemes ထောင်ပေါင်းများစွာနှင့် နှိုင်းယှဉ်လျှင် ~100 mora သာ ရှိသည်
- Shorter syllable durations: Speaking turn တစ်ခုလျှင် temporal context နည်းသည်
6. Multilingual Performance
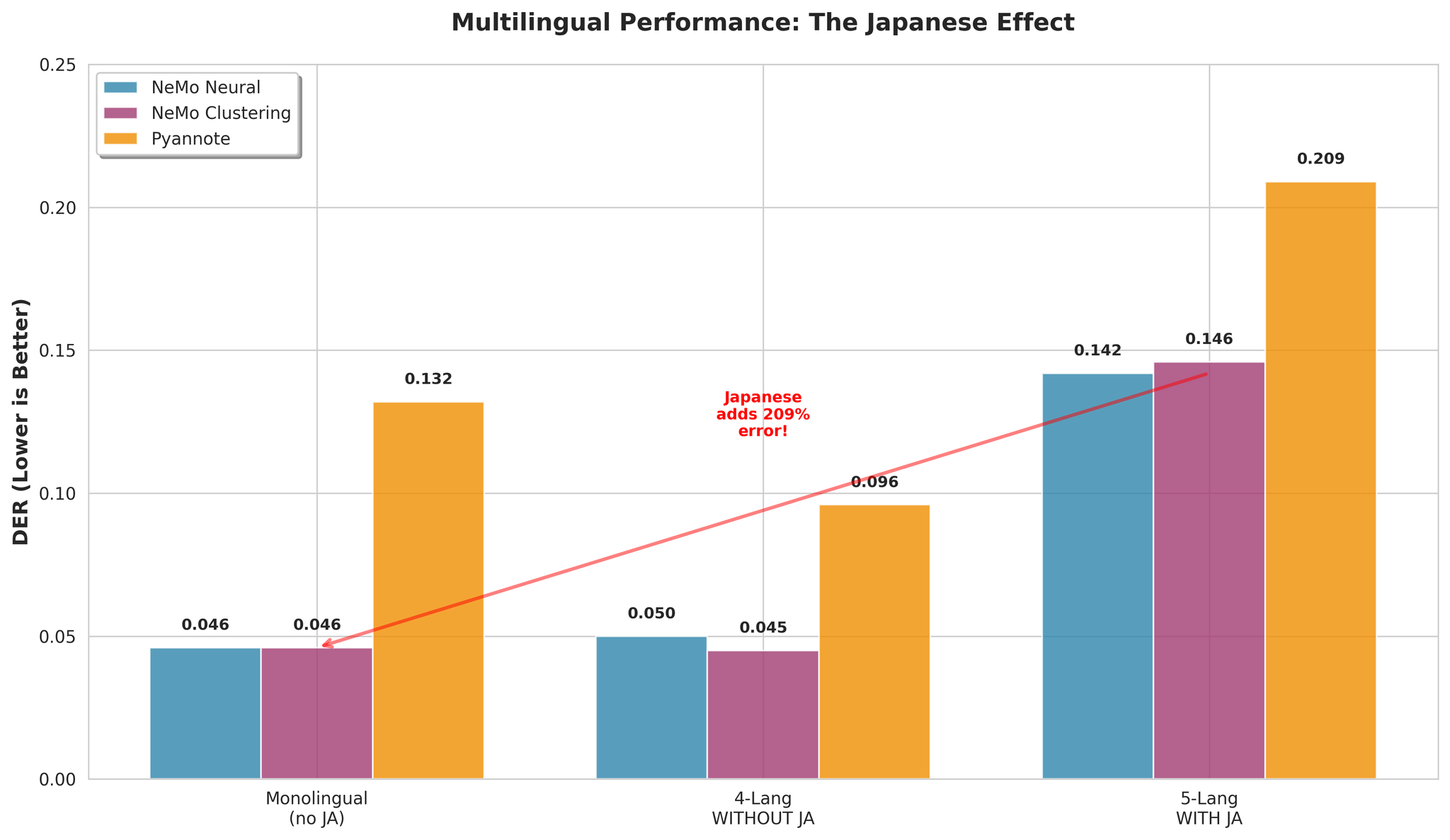
Japanese ပါ/မပါ Multilingual performance
| Configuration | NeMo Neural DER |
|---|---|
| Japanese ပါဝင် (5-lang) | 0.142 |
| Japanese မပါဝင် (4-lang) | 0.050 |
7. Conclusion
အဓိက ရယူချက်များ
NeMo Neural သည် clear winner ဖြစ်သည်:- Best accuracy: DER 0.081 average
- Fast processing: RTF 0.020 (real-time ထက် 50x faster)
- Japanese မပါဝင်သော Excellent multilingual: DER 0.050
အကြံပြုချက်များ
| Use Case | Model | Reason |
|---|---|---|
| Best accuracy | NeMo Neural | DER 0.081 |
| Maximum speed | NeMo Clustering | 2x faster |
| Long audio (30min-1h) | NeMo Neural | Complexity handle လုပ်နိုင်သည် |
| Multilingual (no Japanese) | NeMo Neural | DER 0.050 |
| Japanese (30min+) | NeMo Neural | Context ကူညီသည် |