Author
Aditya Sundar - Waseda UniversityAbstract
ဤ project သည် video နှင့် audio data များကို preprocess လုပ်ပြီး video generation models များ train ရန် key information extract လုပ်သည့် automated pipeline တစ်ခု ဖန်တီးပါသည်။ Pipeline သည် face detection, emotion classification, pose estimation နှင့် audio processing များကို handle လုပ်ပါသည်။ အဓိက Features များ:- Automatic unique face detection နှင့် isolation
- Head pose estimation (yaw, pitch, roll)
- Deep learning အသုံးပြုသော Emotion classification
- Audio classification နှင့် speech isolation
- Clip generation (3-10 second segments)
1. Introduction
Video-based generative models ၏ တိုးတက်လာမှုသည် robust preprocessed video datasets များအတွက် လိုအပ်ချက် ဖန်တီးခဲ့ပါသည်။ ဤ project သည် video နှင့် audio data preprocessing ကို automate လုပ်ပြီး:- Unique faces များကို automatically classify ပြီး recognize လုပ်သည်
- Time တစ်လျှောက် facial emotions နှင့် head poses များကို detect လုပ်သည်
- Background music အတွက် audio classify လုပ်ပြီး speech isolate လုပ်သည်
- Generative models များတွင် အသုံးပြုရန် videos များကို trim ပြီး refine လုပ်သည်
2. Methodology
Pipeline Overview
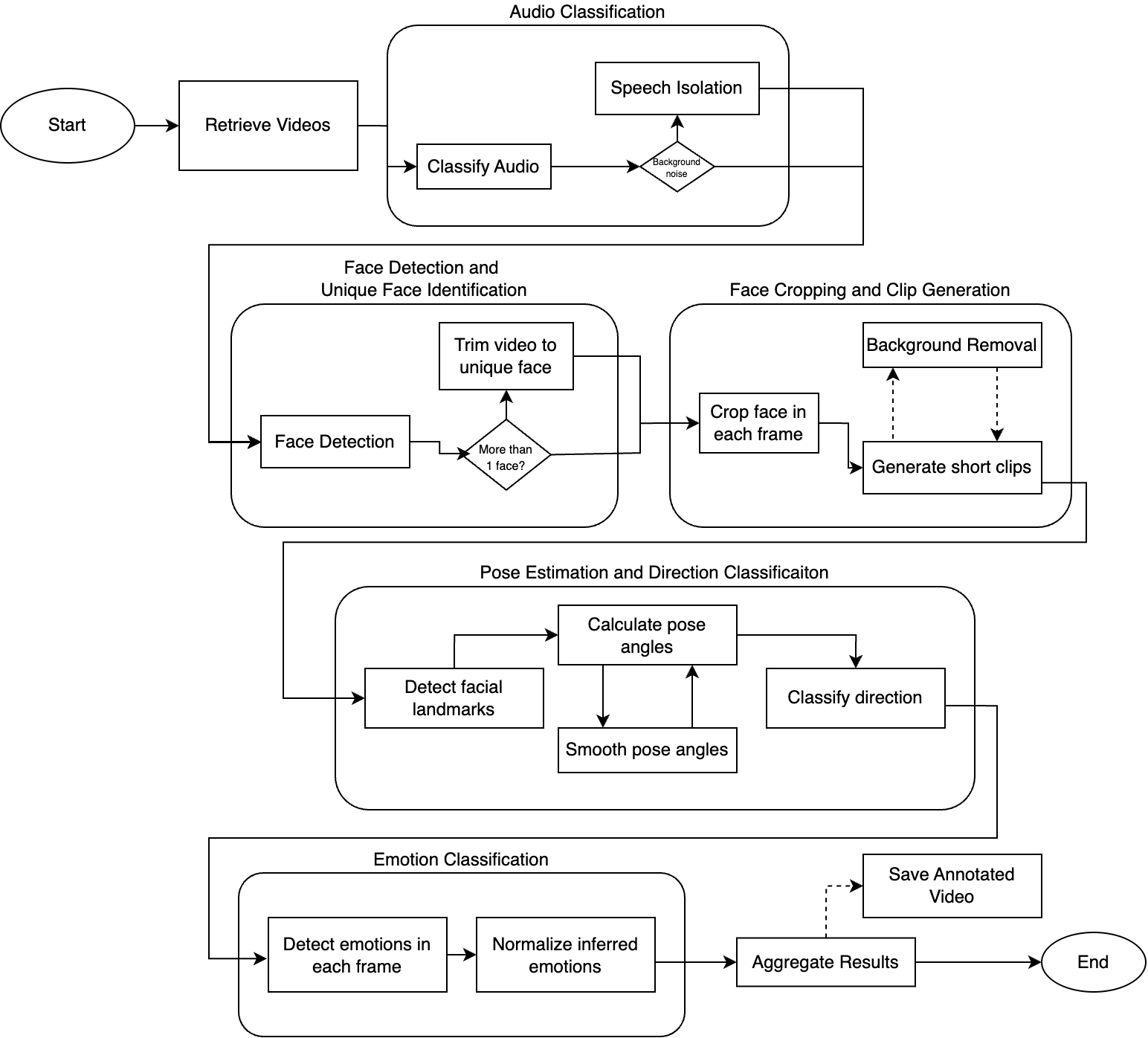
Video preprocessing pipeline workflow
| Stage | Function |
|---|---|
| Audio Classification | Speech identify ပြီး background noise မှ isolate လုပ်သည် |
| Face Detection | Video တွင် unique faces detect ပြီး identify လုပ်သည် |
| Face Cropping | Face-focused clips (3-10 seconds) generate လုပ်သည် |
| Pose Estimation | Head orientation (yaw, pitch, roll) estimate လုပ်သည် |
| Emotion Classification | Frame တစ်ခုချင်းစီတွင် emotions detect လုပ်သည် |
Audio Classification
Audio ကို Audio Spectrogram Transformer model အသုံးပြု၍ classify လုပ်ပါသည်:- Audio ကို spectrogram အဖြစ် convert လုပ်သည်
- Classification အတွက် Vision Transformer apply လုပ်သည်
- Background noise detect ရန် ~20% threshold အသုံးပြုသည်
Face Detection နှင့် Cropping
YuNet face detection model အသုံးပြုပြီး:- Frame တစ်ခုချင်းစီတွင် faces အားလုံး detect လုပ်သည်
- အကြီးဆုံး face ကို subject အဖြစ် select လုပ်သည်
- Consistent dimensions အဖြစ် crop ပြီး resize လုပ်သည်
- 3-10 second clips generate လုပ်သည်
Pose Estimation
68 facial landmarks အသုံးပြု၍ Head pose estimate လုပ်ပါသည်:- Yaw: Left-right rotation (>10 degrees = looking right/left)
- Pitch: Up-down rotation (>10 degrees = looking up/down)
- Roll: Head tilt
Emotion Classification
Hugging Face မှ facial_emotions_image_detection အသုံးပြုပြီး:- Detect လုပ်နိုင်သည်: happy, sad, angry, neutral, fear, disgust, surprise
- Scores များကို 100% ဖြစ်အောင် normalize လုပ်သည်
- Summary အတွက် video တစ်ခုလုံးတွင် average ပြုလုပ်သည်
3. Results
Example Video Analysis
Test video: “Hacksaw Ridge Interview - Andrew Garfield” (4 min 11 sec)| Metric | Value |
|---|---|
| Total frames | 6,024 |
| FPS | 23.97 |
| Face detection rate | 98.26% |
| Average faces per frame | 1.0 |
| Clips generated | 26 |
Pose Estimation Examples
Forward-facing clip:- Yaw: 0.65 degrees, Pitch: 4.07 degrees
- Direction: “Forward”

Forward-facing pose detection
4. Future Directions
- Additional classifications: Lip reading, gesture detection
- GPU acceleration: Resource limits ကြောင့် လက်ရှိ CPU-only ဖြစ်သည်
- Fine-tuned models: Specific tasks အတွက် custom models
- Advanced emotion detection: Static images များထက် ကျော်လွန်သော multi-modal approaches
References
- 1adrianb/face-alignment - 2D and 3D Face alignment library
- ageitgey/face_recognition - Face recognition API for Python
- danielgatis/rembg - Background removal tool
- MIT/ast-finetuned-audioset - Audio Spectrogram Transformer