Author
Akira Noda - VoicePing Inc.
TL;DR
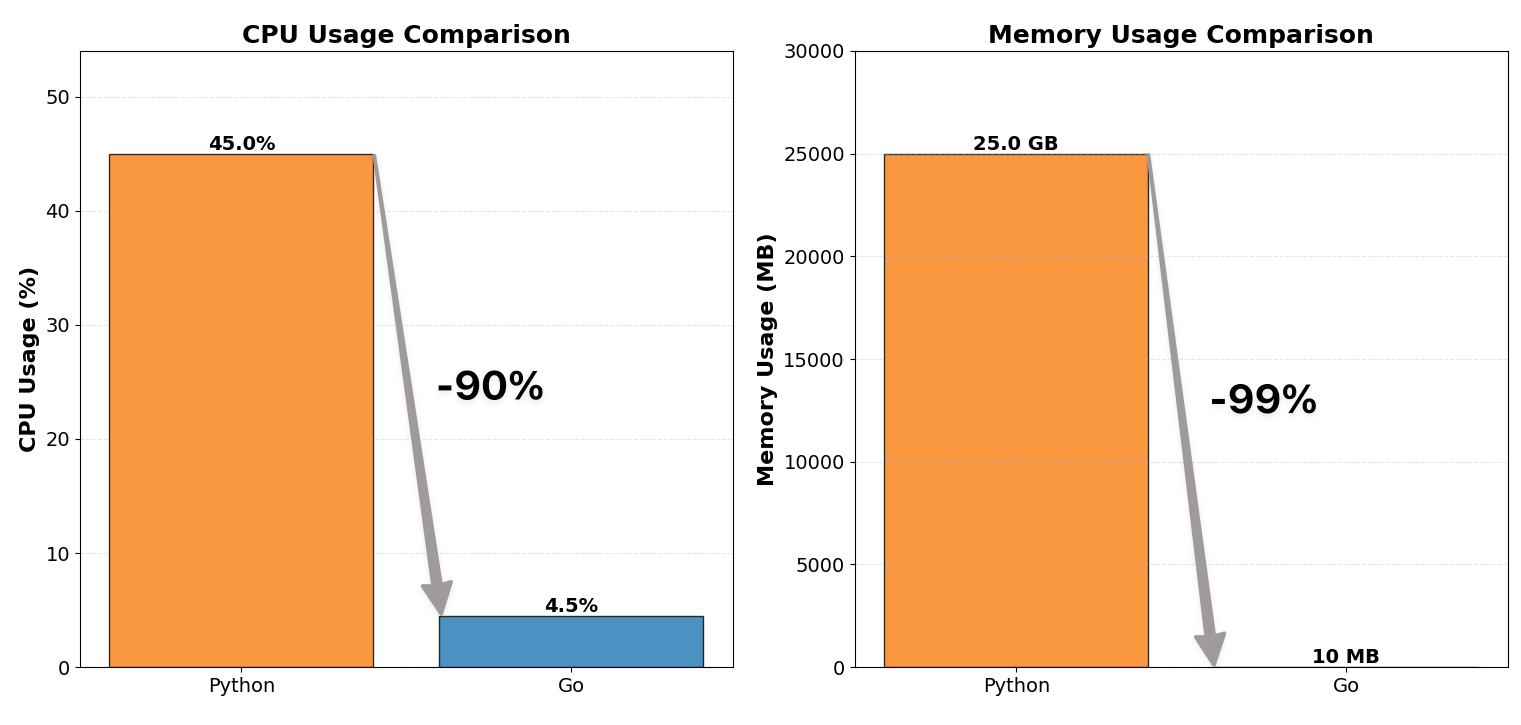
ကျွန်ုပ်တို့၏ WebSocket proxy server ကို Python မှ Go သို့ rewrite လုပ်ပြီး CPU usage ကို 1/10 နှင့် memory consumption ကို 1/100 သို့ လျှော့ချနိုင်ခဲ့ပါသည်။
Project သည် resource efficiency တိုးတက်မှုသာမက crucial concurrency lesson တစ်ခုလည်း သင်ပေးခဲ့ပါသည်:
Locks များကို တတ်နိုင်သမျှ သေးငယ်စွာနှင့် နည်းနည်းသာ ထားပါ။
Context
ကျွန်ုပ်တို့၏ system သည် VoicePing တွင် အသုံးပြုသော real-time STT (speech-to-text) နှင့် translation pipeline ဖြစ်ပြီး client device တစ်ခုချင်းစီသည် speech-to-text နှင့် multiple languages translation အတွက် ကျွန်ုပ်တို့၏ backend သို့ audio stream လုပ်ပါသည်။
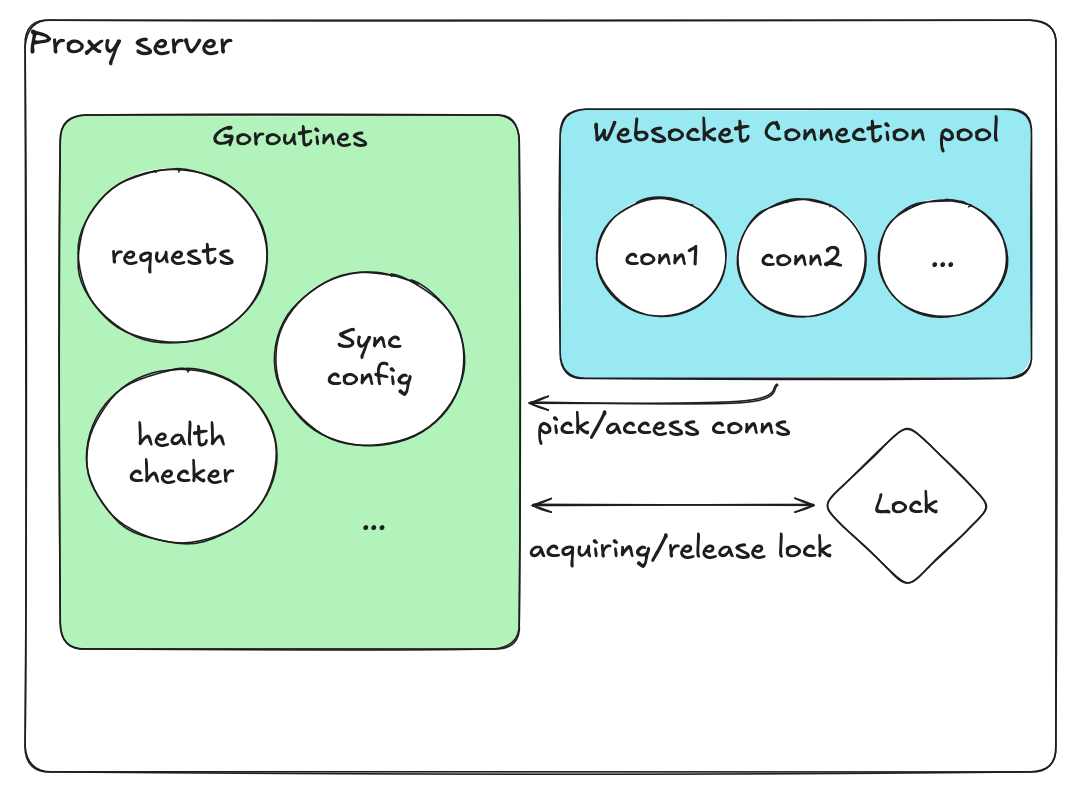
WebSocket proxy server သည် ဤ pipeline ၏ အလယ်တွင် ရှိပါသည်:
System architecture overview
- Client တစ်ခုချင်းစီသည် STT proxy နှင့် persistent WebSocket session ထိန်းသိမ်းသည်
- Proxy သည် audio packets များကို GPU-based inference servers များထဲမှ တစ်ခုသို့ relay လုပ်သည်
- Transcribed text နှင့် translations များကို စောင့်ဆိုင်းပြီး partial transcripts stream back လုပ်သည်
ဤ architecture သည် concurrent real-time audio sessions ထောင်ပေါင်းများစွာ ကို sub-second latency ဖြင့် handle လုပ်ရပါသည်။
သို့သော် ကျွန်ုပ်တို့၏ ယခင် Python-based proxy သည် bottleneck ဖြစ်လာခဲ့ပါသည်။
Before: Python Proxy (Inefficient)
ကျွန်ုပ်တို့၏ ပထမ proxy server ကို Python (FastAPI + asyncio + websockets) တွင် implement လုပ်ပြီး multiple worker processes ဖြင့် Gunicorn အသုံးပြု၍ deploy လုပ်ထားပါသည်။
| Metric | Before (Python) | After (Go) |
|---|
| CPU usage | ~12 cores, 40-50% | ~12 cores, 4-5% |
| Memory usage | ~25 GB | ~10 MB |
Python ဘာကြောင့် ရုန်းကန်ခဲ့သလဲ
Python ၏ architecture သည် systemic bottlenecks များစွာ ဖန်တီးခဲ့ပါသည်:
Single-Threaded Event Loop:
asyncio model သည် coroutines ထောင်ပေါင်းများစွာကို thread တစ်ခုတွင် multiplex လုပ်သည်။ တစ်ချိန်တည်းမှာ coroutine တစ်ခုသာ run ပြီး အခြားများသည် loop yield control ပြုလုပ်သည်အထိ စောင့်ရပါသည်။
Gunicorn Multiprocessing:
CPU cores အားလုံးကို အသုံးပြုရန် multiple worker processes spawn လုပ်ရပါသည်။ Process တစ်ခုချင်းစီသည် full Python runtime နှင့် app state load လုပ်ပြီး memory usage ကို linearly multiply လုပ်ပါသည်။
ထို့ကြောင့် Go တွင် rewrite လုပ်ခဲ့ပါသည်။
Revised Design
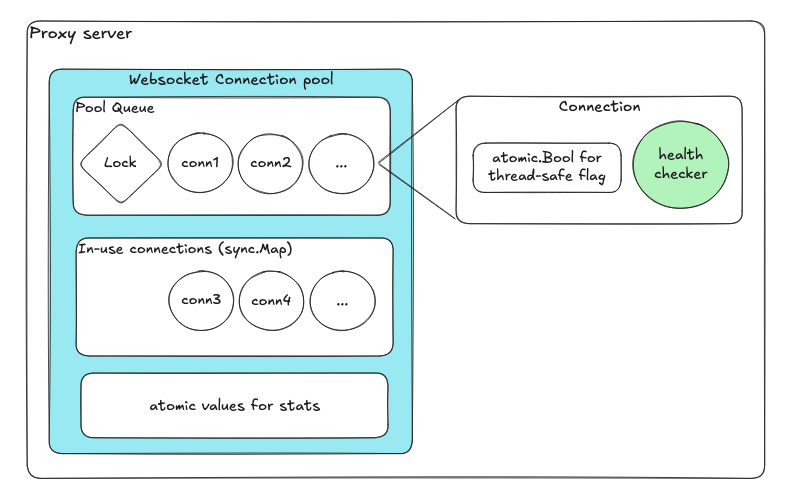
Atomics နှင့် channels ပါဝင်သော Lock-free design
| Component | Purpose |
|---|
| Queue for available connections | Enqueue/dequeue သည် internal locks ကို automatically handle လုပ်သည် |
| sync.Map for in-use connections | Lock-free concurrent map |
| Atomic variables | Health flags နှင့် counters |
| Dedicated goroutine per connection | Independent health checks |
Event-Driven Reconciliation
Reconciliation worker pattern
- Operation တစ်ခုချင်းစီသည် channel (messageCh) ထဲသို့ message ပို့သည်
- Reconciliation goroutine သည် ဤ messages များကို sequentially process လုပ်သည်
- ၎င်းသည် race conditions မရှိစေရန် ensure လုပ်သည်
Test Setup
| Component | Configuration |
|---|
| Proxy | Go-based WebSocket proxy |
| Backends | 3 x Echo WebSocket servers |
| Load | 3,000 connections simultaneously (no ramp-up) |
| Traffic | 1 KB text messages @ 100 msg/s per connection |
Results
| Metric | Value |
|---|
| Concurrent sessions | ~3,000 stable |
| Throughput | ~300K messages/sec |
| Peak memory | ~150 MB |
| Average memory | ~60 MB |
| CPU usage | ~4-5% of 12 cores |
Conclusion
Go-based proxy အသစ်ကို deploy လုပ်ပြီးနောက် performance, scalability နှင့် stability တို့တွင် major improvements များ တွေ့ရှိခဲ့ပါသည်:
| Category | Python | Go | Improvement |
|---|
| CPU usage | ~12 cores x 40-50% | ~12 cores x 4-5% | ~90% reduction |
| Memory usage | ~25 GB | ~60-150 MB | ~99% reduction |
| Scalability | Hundreds limited | Thousands sustains | 10x scale |
အဓိက ရယူချက်: Concurrency ကို shared mutable state under protection အဖြစ်မဟုတ်ဘဲ independent, communicating processes များအဖြစ် design ပါ။
References
- Go Concurrency Patterns - golang.org/doc/effective_go
- gorilla/websocket - github.com/gorilla/websocket