लेखक
Ashar Mirza - VoicePing Inc.Recap: समस्या
भाग 1 मा, हामीले bottleneck पहिचान गर्यौं: हाम्रो FastAPI सेवाले अनुवाद tasks वितरण गर्न IPC queues को साथ multiprocessing workers प्रयोग गर्यो। Baseline: 25 concurrent requests मा 2.2 RPS अगाडि बढ्ने बाटो: multiprocessing हटाउने र vLLM को batch inference utilize गर्ने।Attempt 2: Static Batching
हामीले विद्यमान worker processes भित्र static batching implement गर्यौं।परिणामहरू
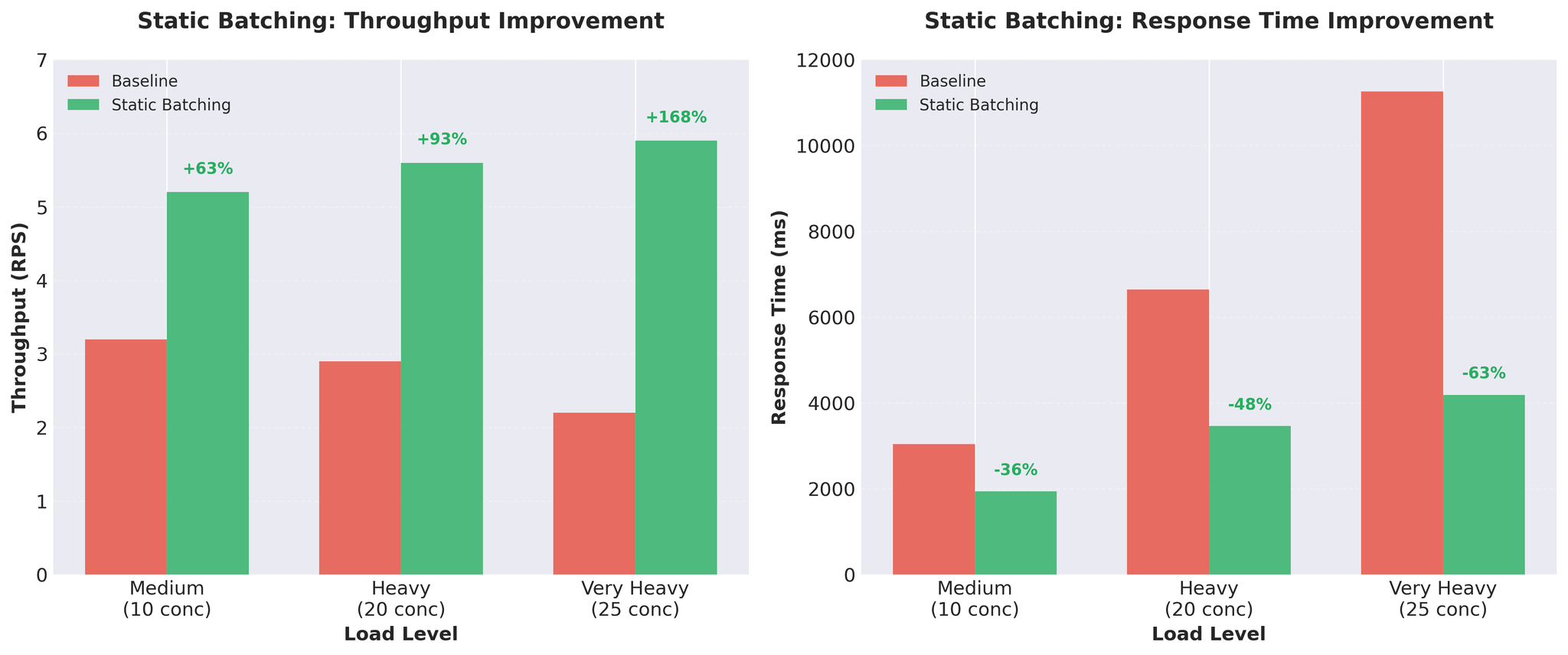
Figure 1: Static batching ले significant throughput र response time सुधारहरू दिन्छ
Trade-offs
Pros:- ठूलो throughput gains
- GPU राम्रोसँग utilized
- सरल implementation
- Head-of-line blocking: सबै requests ले सबैभन्दा ढिलो एउटाको लागि पर्खन्छन्
Attempt 3: Continuous Batching
समाधान: continuous batching को साथ vLLM को AsyncLLMEngine।Continuous Batching के हो?
Static batching विपरीत, continuous batching ले batches dynamically compose गर्दछ:- नयाँ requests mid-generation मा सामेल हुन्छन्
- पूरा भएका requests तुरुन्तै छोड्छन् (अरूको लागि पर्खँदैनन्)
- Batch composition प्रत्येक token अपडेट हुन्छ
- vLLM को AsyncLLMEngine ले यो स्वचालित रूपमा ह्यान्डल गर्दछ
Configuration Tuning
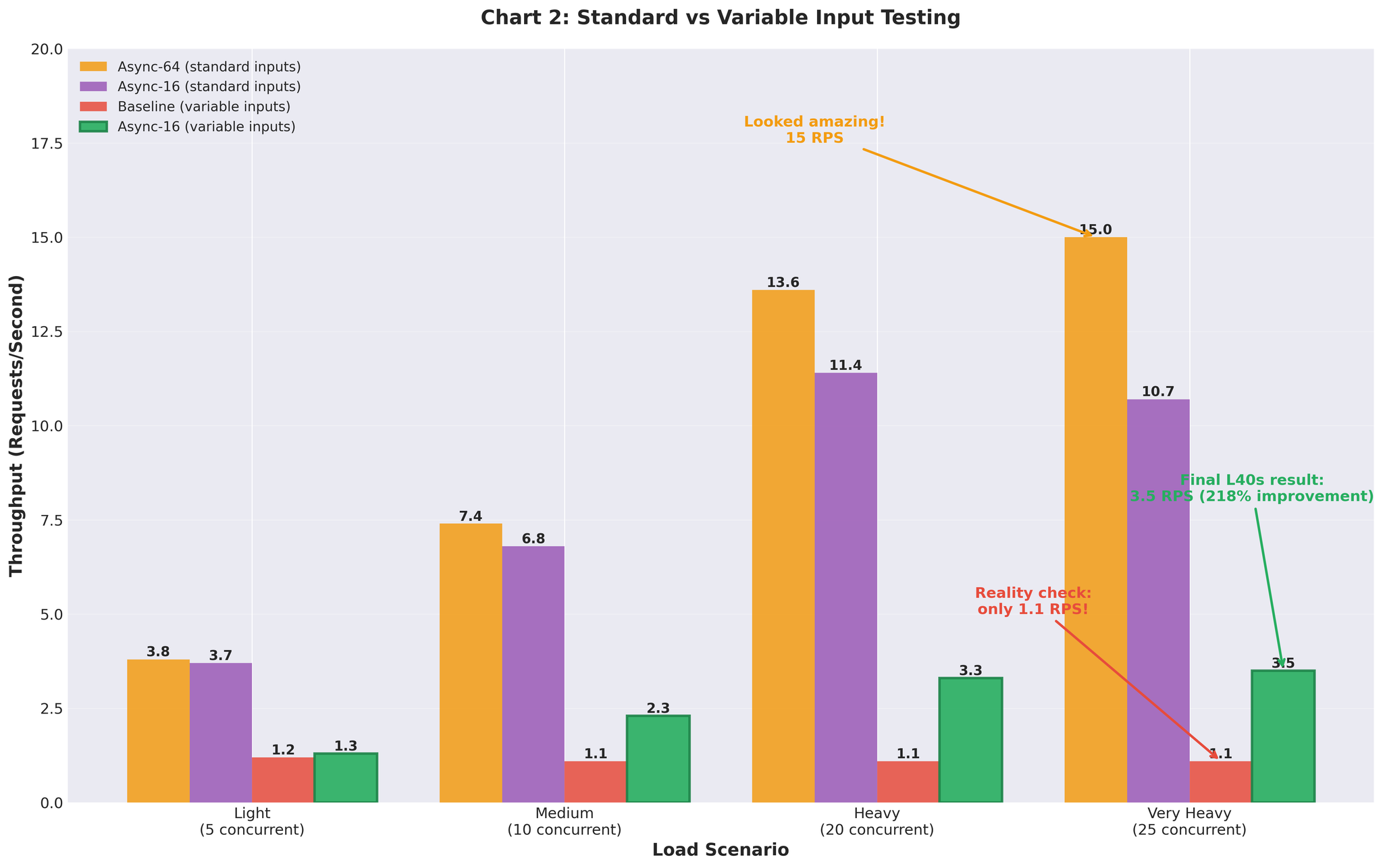
Figure 3: Uniform test data र realistic variable-length inputs बीच Performance gap
| max_num_seqs | परिणाम |
|---|---|
| 8 | राम्रो latency, तर throughput सीमित |
| 16 | सबैभन्दा राम्रो सन्तुलन |
| 32 | Decode time बढ्यो, tail latency खराब |
सिद्धान्त: configuration लाई आफ्नो वास्तविक workload सँग match गर्नुहोस्, theoretical limits सँग होइन।
Production परिणामहरू
हामीले production मा optimized configuration deploy गर्यौं (RTX 5090 GPUs)।Before vs After
| Metric | Before (Multiprocessing) | After (Optimized AsyncLLM) | परिवर्तन |
|---|---|---|---|
| Throughput | 9.0 RPS | 16.4 RPS | +82% |
| GPU Utilization | Spiky (93% → 0% → 93%) | Consistent 90-95% | Stable |
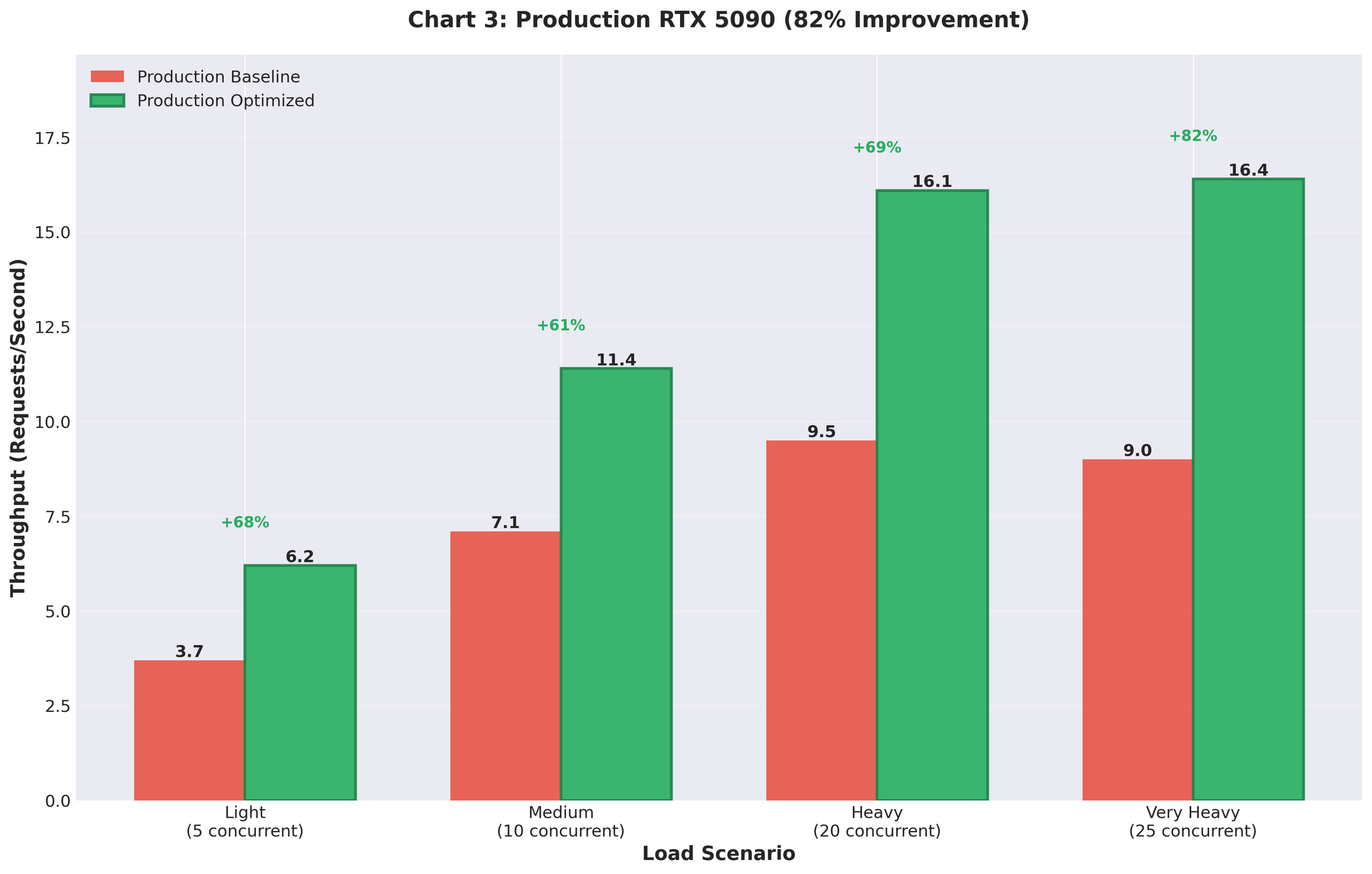
Figure 5: Production deployment परिणामहरू 82% throughput सुधार देखाउँदै
सारांश
के काम गर्यो
vLLM को continuous batching- AsyncLLMEngine ले batching स्वचालित रूपमा ह्यान्डल गर्दछ
- Manual batch collection overhead छैन
- FastAPI सँग Direct async/await एकीकरण
- max_num_seqs=16 (प्रति server वास्तविक workload सँग match)
- 64 होइन (overhead सिर्जना गर्ने theoretical max)
- Variable-length inputs ले configuration समस्याहरू expose गर्यो
- Uniform test data ले misleading 15 RPS दियो
Complete Journey
| Approach | Throughput | vs Baseline | Notes |
|---|---|---|---|
| Baseline (multiprocessing) | 2.2 RPS | - | IPC overhead, GPU contention |
| Two workers | 2.0 RPS | -9% | अझ खराब बनायो |
| Static batching | 5.9 RPS | +168% | Head-of-line blocking |
| Async (64, uniform) | 15.0 RPS | +582% | Misleading test data |
| Async (16, variable) | 3.5 RPS | +59% | Realistic, तर tuning चाहियो |
| Final optimized | 10.7 RPS | +386% | Staging validation |
| Production | 16.4 RPS | +82% | Real traffic, RTX 5090 |