लेखक
Akira Noda - VoicePing Inc.
TL;DR
हामीले हाम्रो WebSocket proxy server Python बाट Go मा पुनर्लेखन गर्यौं र CPU usage 1/10 र memory consumption 1/100 मा घटायौं।
परियोजनाले स्रोत दक्षता मात्र सुधार गरेन तर हामीलाई एउटा महत्त्वपूर्ण concurrency पाठ पनि सिकायो:
Locks जति सानो र जति कम सम्भव राख्नुहोस्।
Context
हाम्रो प्रणाली VoicePing मा प्रयोग हुने वास्तविक-समय STT (speech-to-text) र अनुवाद pipeline हो, जहाँ प्रत्येक client उपकरणले speech-to-text र बहु भाषाहरूमा अनुवादको लागि हाम्रो backend मा अडियो stream गर्दछ।
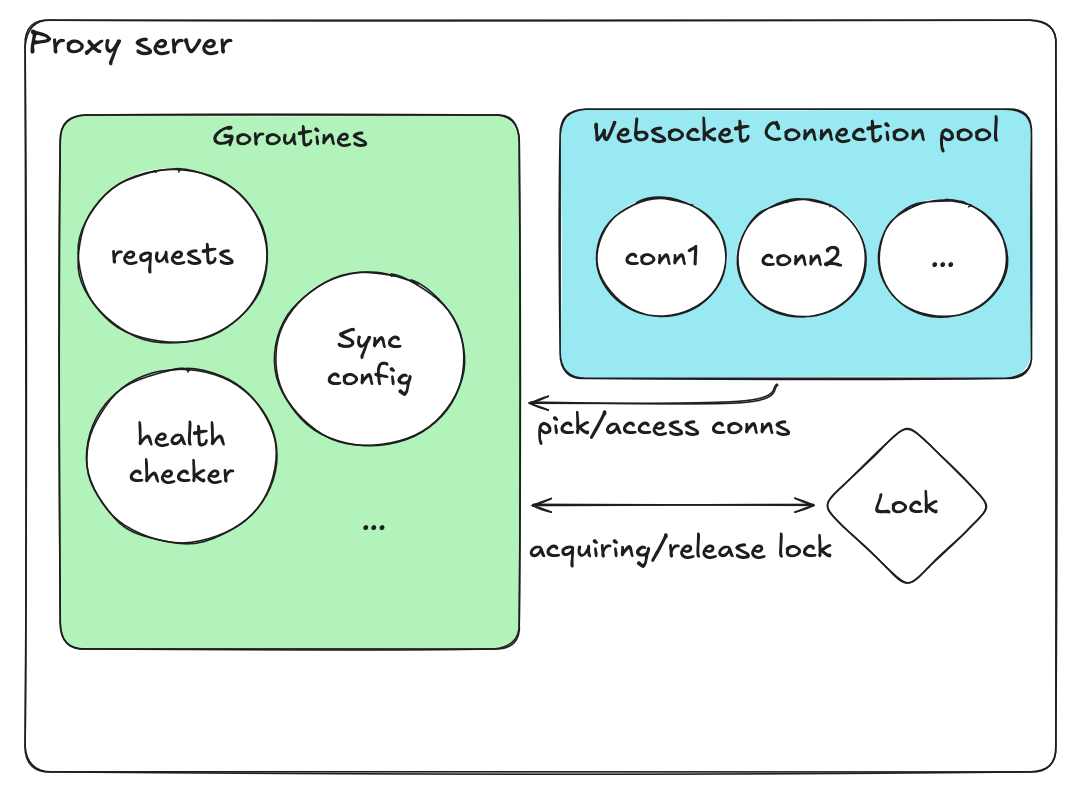
प्रणाली architecture अवलोकन
- प्रत्येक client ले STT proxy को साथ persistent WebSocket session कायम गर्दछ
- Proxy ले अडियो packets धेरै GPU-आधारित inference servers मध्ये एउटामा relay गर्दछ
- Transcribed text को लागि पर्खन्छ र partial transcripts र अनुवादहरू stream back गर्दछ
यो architecture ले हजारौं concurrent real-time audio sessions - sub-second latency को साथ ह्यान्डल गर्नुपर्छ।
Before: Python Proxy (Inefficient)
हाम्रो पहिलो proxy server Python (FastAPI + asyncio + websockets) मा implement गरिएको थियो।
| Metric | Before (Python) | After (Go) |
|---|
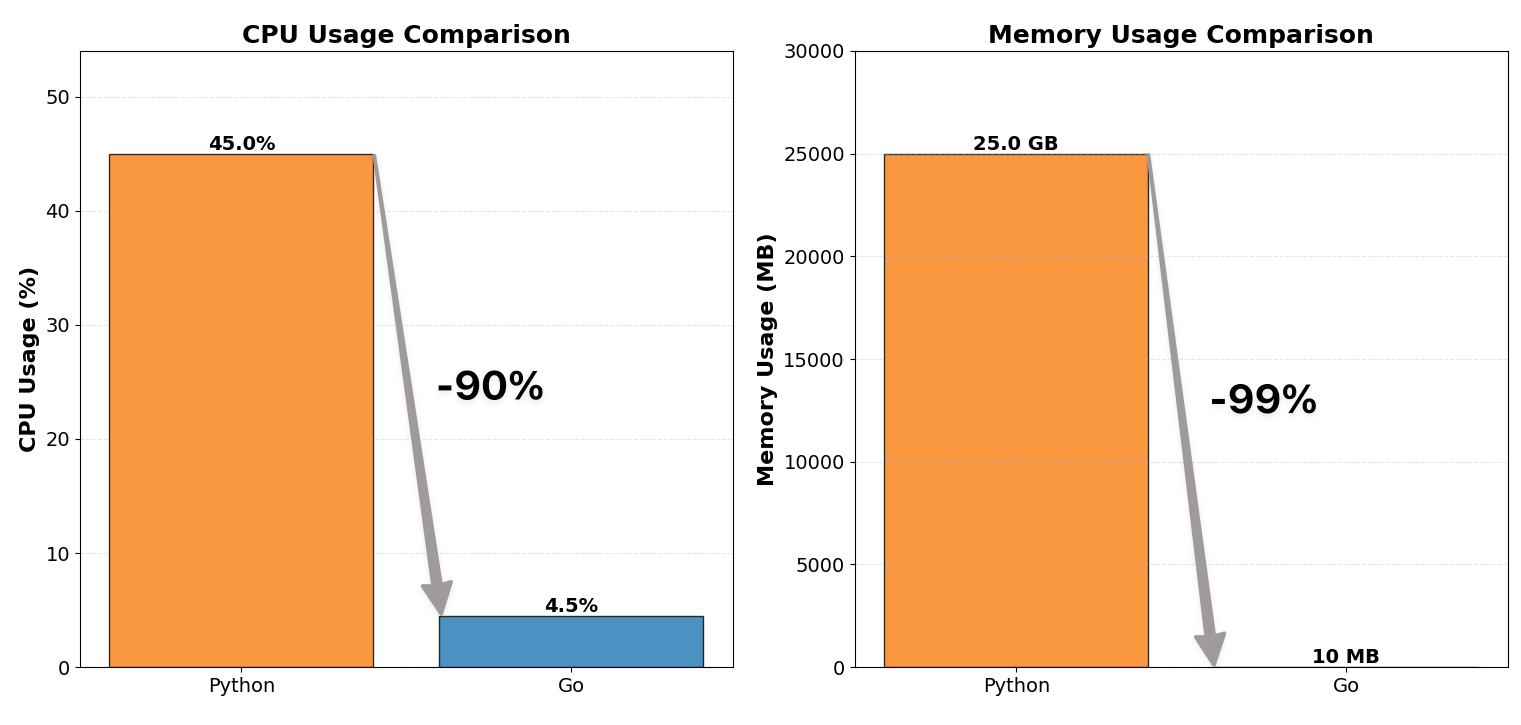
| CPU usage | ~12 cores, 40–50% | ~12 cores, 4–5% |
| Memory usage | ~25 GB | ~10 MB |
Python किन Struggled
Asynchronous भए पनि, Python को architecture ले धेरै systemic bottlenecks लगायो:
Single-Threaded Event Loop:
asyncio model ले हजारौं coroutines एकल thread मा multiplex गर्दछ। यसको मतलब एक पटकमा एउटा मात्र coroutine चल्छ।
Gunicorn Multiprocessing:
सबै CPU cores प्रयोग गर्न, हामीले बहु worker processes spawn गर्यौं। प्रत्येक process ले पूर्ण Python runtime र app state load गर्यो - memory usage linearly multiply गर्दै।
Revised Design
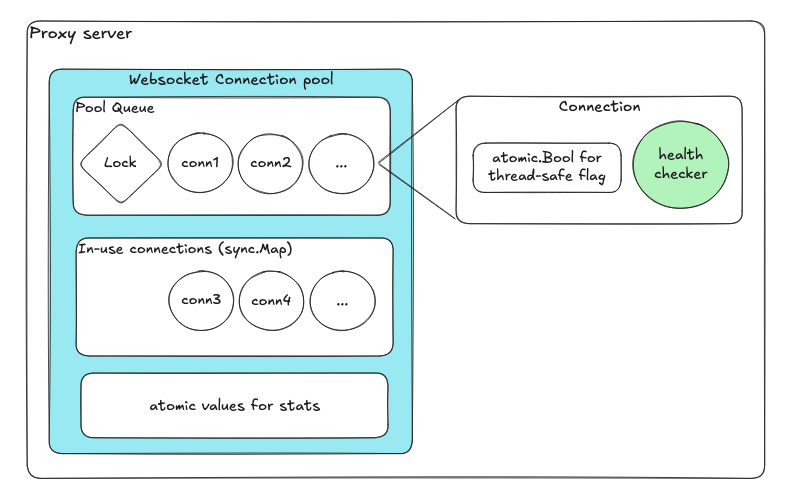
Atomics र channels को साथ Lock-free design
| Component | उद्देश्य |
|---|
| उपलब्ध connections को लागि Queue | Enqueue/dequeue ले internal locks स्वचालित रूपमा ह्यान्डल गर्दछ |
| in-use connections को लागि sync.Map | Lock-free concurrent map |
| Atomic variables | Health flags र counters |
| प्रति connection dedicated goroutine | Independent health checks |
Event-Driven Reconciliation
Reconciliation worker pattern
- प्रत्येक operation ले channel (messageCh) मा message पठाउँछ
- Reconciliation goroutine ले यी messages sequentially process गर्दछ
- यसले कुनै race conditions सुनिश्चित गर्दैन
Test Setup
| Component | Configuration |
|---|
| Proxy | Go-based WebSocket proxy |
| Backends | 3 × Echo WebSocket servers |
| Load | 3,000 connections simultaneously |
| Traffic | 1 KB text messages @ 100 msg/s per connection |
परिणामहरू
| Metric | मान |
|---|
| Concurrent sessions | ~3,000 stable |
| Throughput | ~300K messages/sec |
| Peak memory | ~150 MB |
| Average memory | ~60 MB |
| CPU usage | ~4–5% of 12 cores |
निष्कर्ष
नयाँ Go-based proxy deploy गरेपछि, हामीले प्रदर्शन, scalability, र स्थिरतामा प्रमुख सुधारहरू देख्यौं:
| Category | Python (FastAPI + asyncio + Gunicorn) | Go (Goroutines + Channels + Atomics) | सुधार |
|---|
| CPU usage | ~12 cores × 40–50% | ~12 cores × 4–5% | ~90% घटाव |
| Memory usage | ~25 GB | ~60–150 MB | ~99% घटाव |
| Scalability | सयौंमा सीमित | हजारौं sustain गर्दछ | 10x scale |
मुख्य Takeaway: Concurrency लाई स्वतन्त्र, communicating processes को रूपमा design गर्नुहोस् - protection अन्तर्गत shared mutable state को रूपमा होइन।
सन्दर्भहरू
- Go Concurrency Patterns - golang.org/doc/effective_go
- gorilla/websocket - github.com/gorilla/websocket
- Python asyncio Event Loop - docs.python.org