लेखक
Kai-Teh Tzeng - Lehigh University
सारांश
यो अध्ययनले Llama 3.1-8B को साथ अंग्रेजी-चिनियाँ bidirectional अनुवाद सुधार गर्न Retrieval-Augmented Fine-Tuning (RAFT) प्रयोग गर्ने अन्वेषण गर्दछ। RAFT ले प्रशिक्षणको समयमा contextual उदाहरणहरू प्रदान गर्न retrieval mechanisms लाई fine-tuning सँग संयोजन गर्दछ।
मुख्य निष्कर्षहरू:
- Benchmark fine-tuning ले समग्र सबैभन्दा राम्रो परिणामहरू प्राप्त गर्यो
- RAFT ले विशेष metrics मा मध्यम सुधारहरू देखायो
- Random-based RAFT ले कहिलेकाहीं similarity-based RAFT भन्दा राम्रो प्रदर्शन गर्यो
- अनुवाद गुणस्तर प्रशिक्षण डाटा relevance मा धेरै निर्भर गर्दछ
1. परिचय
पृष्ठभूमि
ठूला भाषा मोडेलहरूले भाषा कार्यहरूमा उत्कृष्ट प्रदर्शन गर्दछन् तर domain-विशिष्ट optimization बाट फाइदा लिन सक्छन्। यो अनुसन्धानले RAFT - retrieved उदाहरणहरूको साथ प्रशिक्षण augment गर्ने प्रविधि - ले अनुवाद गुणस्तर सुधार गर्न सक्छ कि भनेर अन्वेषण गर्दछ।
अनुसन्धान प्रश्नहरू
- के RAFT ले मानक fine-tuning को तुलनामा अनुवाद सुधार गर्न सक्छ?
- के similarity-based retrieval ले random retrieval भन्दा राम्रो प्रदर्शन गर्दछ?
- विभिन्न RAFT configurations ले bidirectional अनुवादलाई कसरी प्रभाव पार्छ?
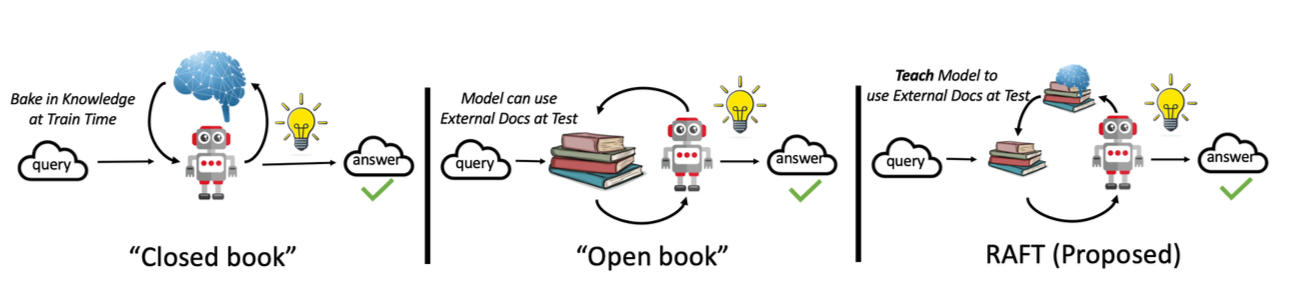
2. विधि
RAFT अवलोकन
RAFT (Retrieval-Augmented Fine-Tuning) ले प्रशिक्षण प्रक्रिया सुधार गर्दछ:
- प्रत्येक प्रशिक्षण sample को लागि corpus बाट सान्दर्भिक उदाहरणहरू Retrieving
- Retrieved उदाहरणहरूको साथ प्रशिक्षण context Augmenting
- यो समृद्ध context को साथ मोडेल Fine-tuning
प्रयोगात्मक सेटअप
| Component | Configuration |
|---|
| Base Model | Llama 3.1-8B Instruct |
| Fine-tuning | LoRA (r=16, alpha=16) |
| Dataset | News Commentary v18.1 (zh-en) |
| GPU | NVIDIA A100 80GB |
RAFT Configurations
| Configuration | विवरण |
|---|
| Benchmark | Retrieval बिना मानक fine-tuning |
| Similarity RAFT | Embeddings प्रयोग गरेर top-k समान उदाहरणहरू retrieve |
| Random RAFT | Corpus बाट k उदाहरणहरू randomly sample |
3. परिणामहरू
अंग्रेजी-देखि-चिनियाँ अनुवाद
| विधि | BLEU | COMET |
|---|
| Baseline (No Fine-tuning) | 15.2 | 0.785 |
| Benchmark Fine-tuning | 28.4 | 0.856 |
| Similarity RAFT (k=3) | 27.1 | 0.849 |
| Random RAFT (k=3) | 27.8 | 0.852 |
चिनियाँ-देखि-अंग्रेजी अनुवाद
| विधि | BLEU | COMET |
|---|
| Baseline (No Fine-tuning) | 18.7 | 0.812 |
| Benchmark Fine-tuning | 31.2 | 0.871 |
| Similarity RAFT (k=3) | 30.5 | 0.865 |
| Random RAFT (k=3) | 30.9 | 0.868 |
Benchmark fine-tuning ले यो प्रयोगमा RAFT configurations भन्दा लगातार राम्रो प्रदर्शन गर्यो। यो News Commentary dataset को homogeneous प्रकृतिको कारण हुन सक्छ।
विश्लेषण
RAFT ले benchmark भन्दा राम्रो प्रदर्शन किन गरेन:
- Dataset Homogeneity: News Commentary मा consistent style छ
- Retrieval Quality: Similarity metrics ले अनुवाद-सान्दर्भिक features कैद नगर्न सक्छ
- Context Length: थप उदाहरणहरूले context बढाउँछ, सम्भावित रूपमा focus dilute गर्दै
4. निष्कर्ष
RAFT ले आशा देखाउँछ, हाम्रा प्रयोगहरूले सुझाव दिन्छ कि homogeneous datasets मा अनुवाद कार्यहरूको लागि, मानक fine-tuning प्रतिस्पर्धी रहन्छ। भविष्यको काममा विविध प्रशिक्षण corpora र राम्रो retrieval metrics अन्वेषण गर्नुपर्छ।
सन्दर्भहरू
- Zhang, T., et al. (2024). “RAFT: Adapting Language Model to Domain Specific RAG.”
- Lewis, P., et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”