1. परिचय
ठूला भाषा मोडेलहरू (LLMs) ले input-label pairs मा conditioning मार्फत downstream tasks मा प्रभावशाली दक्षता देखाएका छन्। यो inference mode लाई in-context learning (Brown et al. 2020) भनिन्छ। GPT-4 ले विशेष कार्य उदाहरणहरू प्रदान गरेर fine-tuning बिना आफ्नो अनुवाद क्षमताहरू सुधार गर्न सक्छ।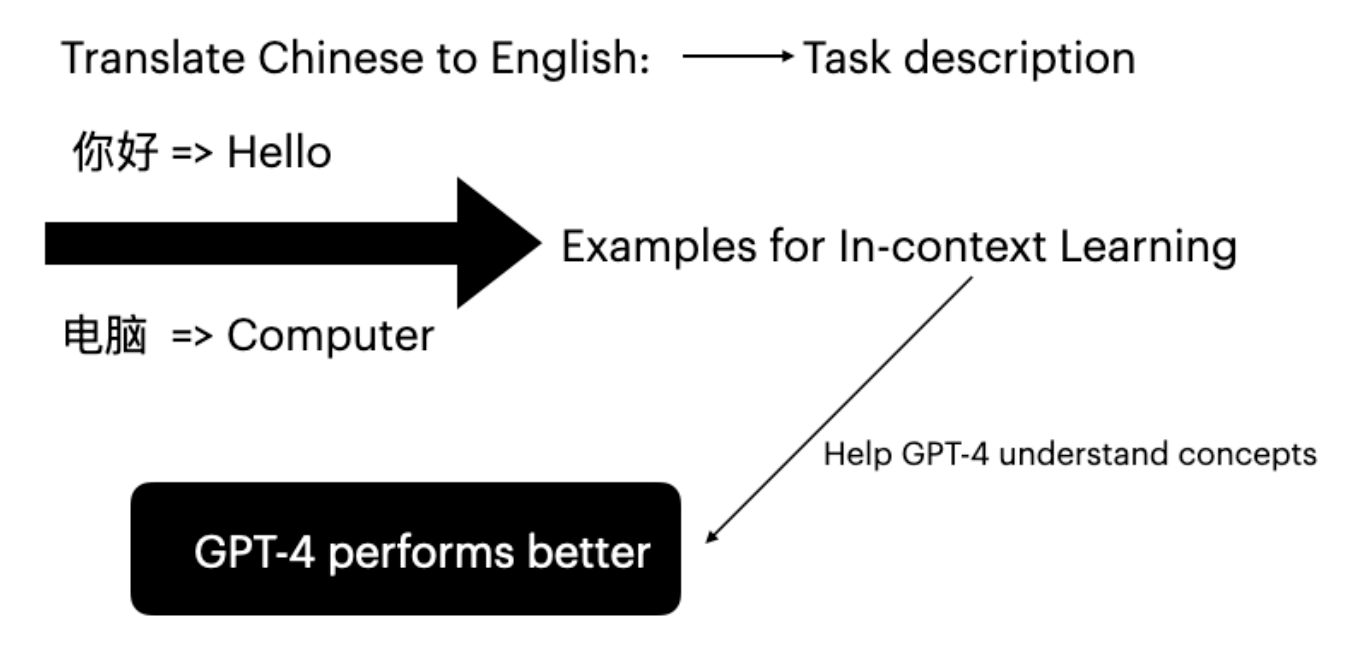
Figure 1: Few-shot उदाहरणहरू प्रयोग गरेर चिनियाँ देखि अंग्रेजी अनुवादको लागि In-context learning
2. प्रस्तावित विधि
यो विधिले अनुवाद जोडाहरू समावेश गर्ने Ds dataset मा पहुँच मान्दछ। Text retriever (Gao 2023) ले user prompt सँग समान अर्थ भएका शीर्ष K वाक्यहरू पत्ता लगाउँछ र चयन गर्दछ। Retriever मा दुई components छन्:- TF-IDF Matrix - term frequency र inverse document frequency मापन गर्दछ
- Cosine Similarity - TF-IDF vectors बीच समानता मापन गर्दछ
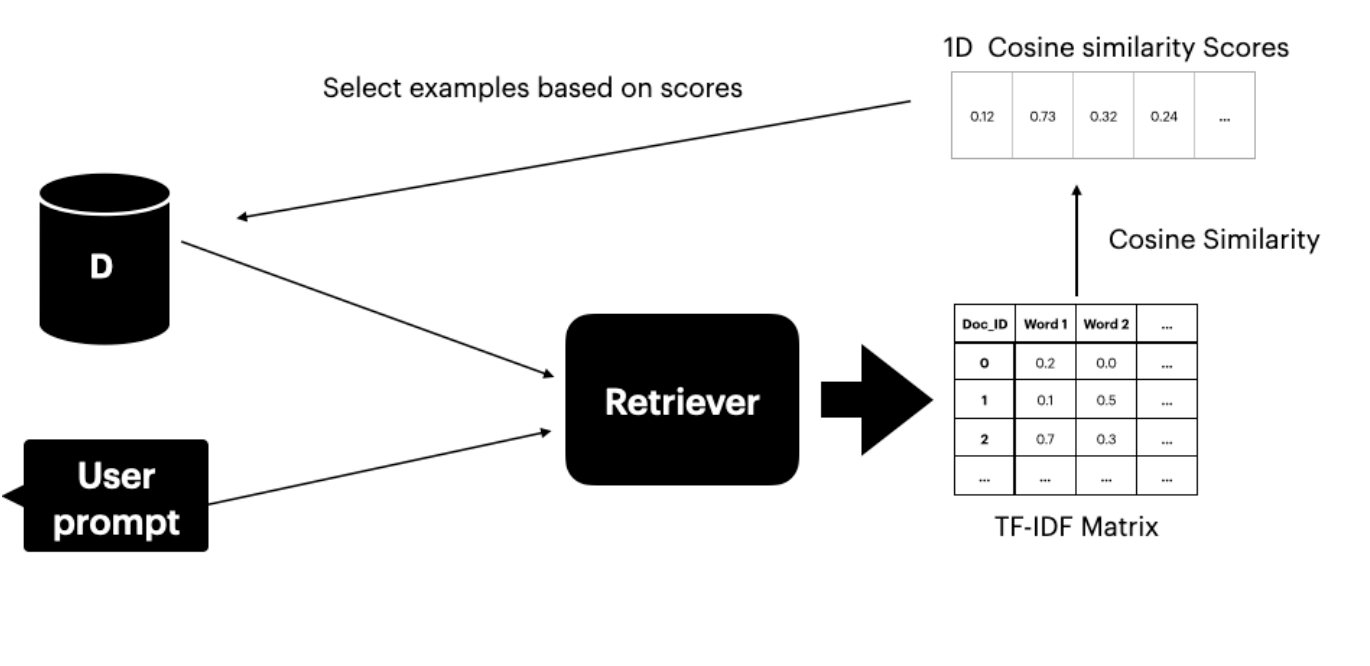
Figure 2: Dataset बाट top-K उदाहरणहरू चयन गर्न TF-IDF matrix र cosine similarity प्रयोग गर्ने
3. प्रयोगात्मक सेटअप
3.1 प्रयोगात्मक प्रक्रिया
प्रयोगले तीन परिदृश्यहरू कभर गर्दछ:- No ICL: In-context learning उदाहरणहरू बिना GPT-4 अनुवाद
- Random ICL: अनुवाद उदाहरणहरूको Random चयन
- प्रस्तावित विधि: TF-IDF retriever ले similarity scores मा आधारित शीर्ष 4 उदाहरणहरू चयन गर्दछ
मूल्यांकन Metrics
- BLEU Score: Reference अनुवादहरूसँग अनुवादित segments तुलना गर्दछ
- COMET Score: मानव निर्णयसँग state-of-the-art correlation प्राप्त गर्ने बहुभाषी MT मूल्यांकनको लागि Neural framework
3.2 Datasets
OPUS-100 (Zhang et al. 2020) छानिएको किनभने यो:- विविध अनुवाद भाषा जोडाहरू समावेश गर्दछ (ZH-EN, JA-EN, VI-EN)
- प्रभावकारी उदाहरण चयनको लागि विविध domains कभर गर्दछ
- Ds को लागि प्रति भाषा जोडा 10,000 प्रशिक्षण instances
- मूल्यांकनको लागि test set बाट पहिलो 100 वाक्यहरू
4. परिणामहरू र छलफल
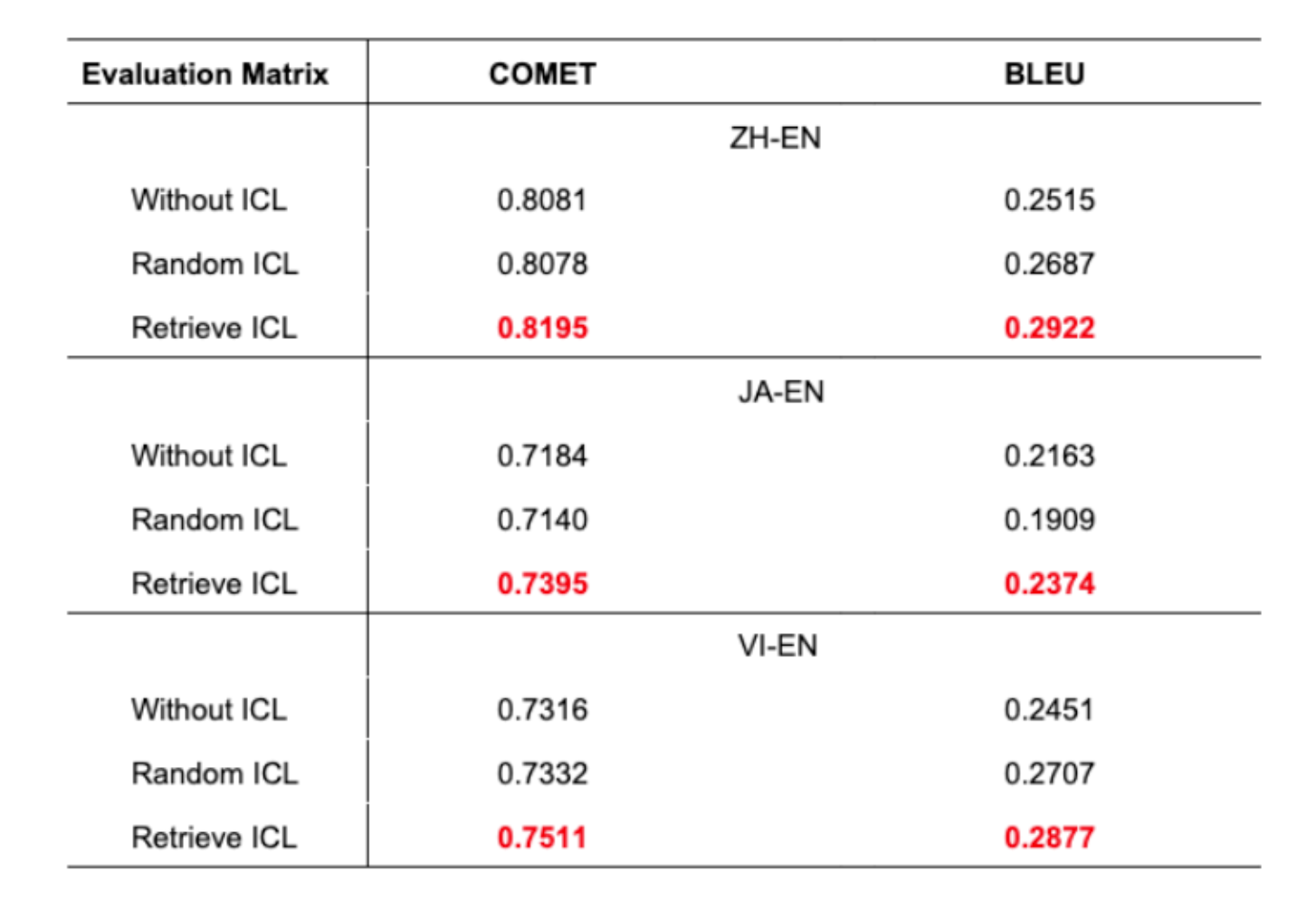
Table 1: सबै भाषा जोडाहरूको लागि तीन परिदृश्यहरूमा अनुवाद सटीकता
- प्रस्तावित दृष्टिकोणले सबै भाषा जोडाहरूमा उत्कृष्ट अनुवाद सटीकता देखाउँछ
- BLEU score मा 1% सुधार मेशिन अनुवादमा significant हो
- Random ICL ले कहिलेकाहीं no ICL भन्दा खराब प्रदर्शन गर्दछ
- यसले विवेकी उदाहरण चयनको महत्त्व हाइलाइट गर्दछ
Dataset Size Impact

Table 2: विभिन्न dataset sizes को साथ अनुवाद सटीकता
5. निष्कर्ष र अगाडिका कदमहरू
यो कागजातले TF-IDF retrieval को साथ in-context learning मार्फत GPT-4 अनुवाद सुधार गर्ने विधि परिचय गर्दछ। दृष्टिकोणले:- TF-IDF matrix र cosine similarity प्रयोग गरेर retriever निर्माण गर्दछ
- User prompts सँग नजिकबाट मिल्ने वाक्यहरू चयन गर्दछ
- BLEU र COMET दुवै scores मा सुधारहरू देखाउँछ
- Dataset निर्माण: Domains मा व्यापक, उच्च-गुणस्तर अनुवाद datasets सिर्जना गर्ने
- उदाहरण मात्रा: 4 को सट्टा 5 वा 10 उदाहरणहरू प्रयोग गर्ने प्रभाव अनुसन्धान गर्ने
6. सन्दर्भहरू
- Brown, T., et al. (2020). “Language models are few-shot learners.”
- Xie, S. M., et al. (2022). “An Explanation of In-context Learning as Implicit Bayesian Inference.”
- Liu, J., et al. (2022). “What makes good in-context examples for GPT-3?”
- Papineni, K., et al. (2002). “BLEU: A method for automatic evaluation of machine translation.”
- Rei, R., et al. (2020). “COMET: A Neural Framework for MT Evaluation.”