लेखक
Ashar Mirza - VoicePing Inc.समस्या
हामी FastAPI र vLLM प्रयोग गरेर अनुवाद microservice चलाउँछौं। भारी load अन्तर्गत, हामीले server latency समस्याहरू सामना गर्यौं जुन हाम्रो GPU utilization metrics ले सुझाव गरेको कुरासँग मेल खाएन। GPU utilization ले stuttering pattern देखायो: 93% मा spike, 0% मा drop, फेरि spike। हामीले अपेक्षा गरेको consistent high utilization होइन। प्रश्न: यदि GPU मा idle periods छन् भने, bottleneck कहाँ छ?प्रणाली Context
हाम्रो अनुवाद सेवा load balancer पछाडि बहु API servers को रूपमा चल्छ:
Figure 1: समग्र प्रणाली architecture client applications, proxy/load balancer, र बहु API servers देखाउँदै
API Server Architecture

Figure 2: एकल API server architecture FastAPI, multiprocessing queues, worker processes, र vLLM instances देखाउँदै
Baseline Performance
Optimization प्रयासहरू अघि: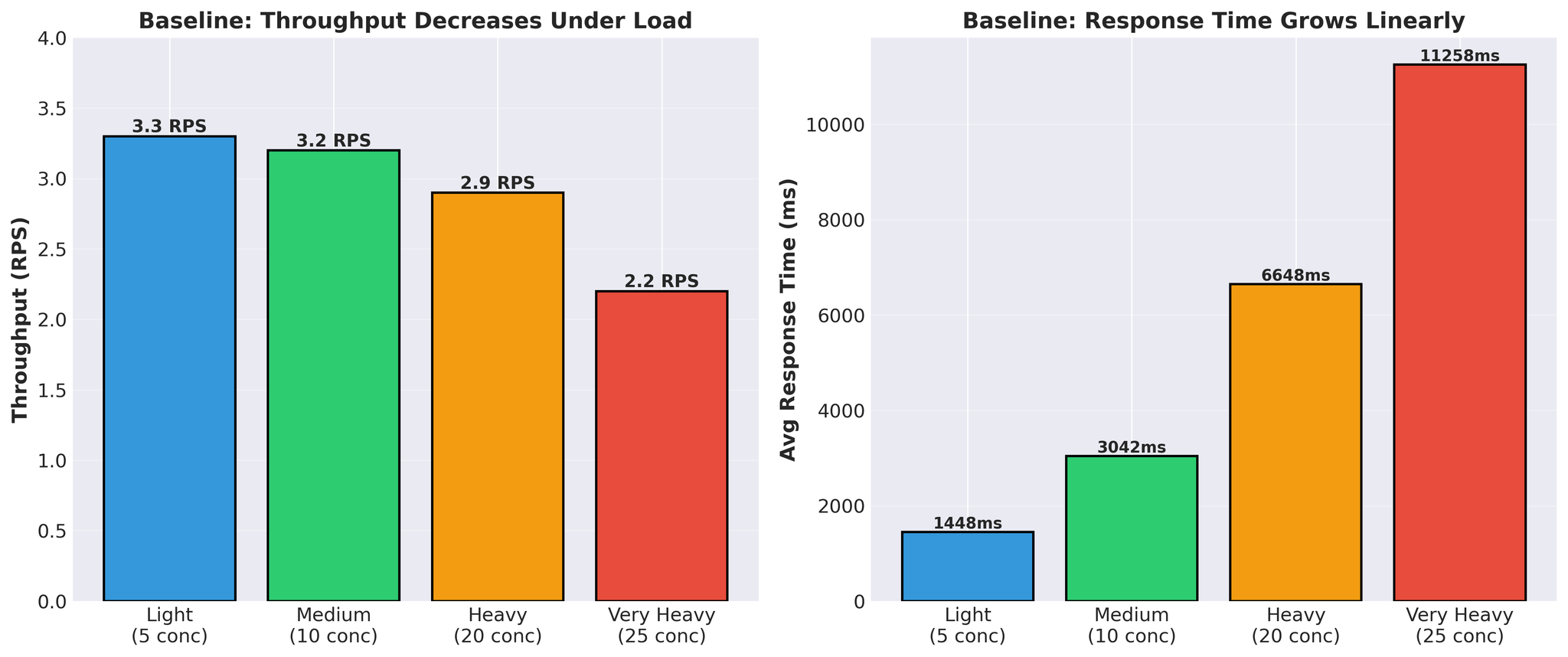
Figure 4: Baseline performance load अन्तर्गत throughput घटाव र response time वृद्धि देखाउँदै
- Response time linearly बढ्छ (1.4s → 11.3s)
- Throughput load अन्तर्गत घट्छ (3.3 → 2.2 RPS)
- प्रति request वास्तविक vLLM अनुवाद समय: 300-450ms
Attempt 1: Multiple Workers
पहिलो hypothesis: more workers = better parallelization। हामीले 1 worker बाट 2 workers मा बढायौं।परिणामहरू
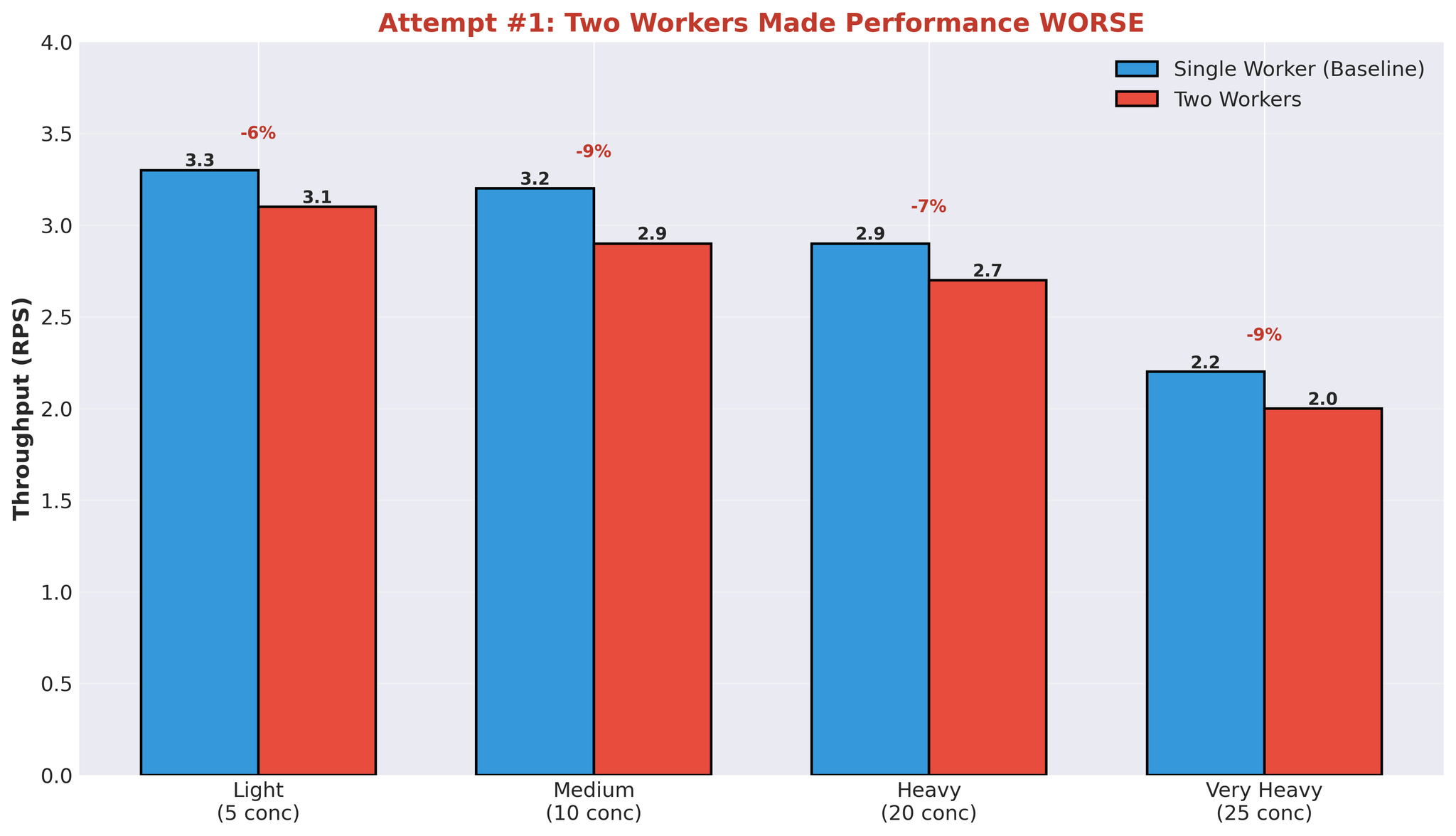
Figure 6: दोस्रो worker process थप्दा Performance degradation
Multiple Workers किन Fail भयो

Figure 7: Multiple worker processes GPU compute capacity को लागि प्रतिस्पर्धा गर्दै
समस्या: Compute Contention
जब एक worker अनुवाद process गर्दैछ:- यसले ~90% GPU compute capacity प्रयोग गर्दछ
- अन्य workers ले बाँकी capacity parallel मा प्रभावकारी रूपमा utilize गर्न सक्दैनन्
- Workers GPU उपलब्धताको लागि पर्खने समाप्त हुन्छन्
पहिचान गरिएका Bottlenecks
यो प्रयोग पछि, हामीले core समस्याहरू पहिचान गर्यौं:1. IPC Serialization Overhead
- प्रत्येक request: task serialize → worker, result serialize → main
- Python multiprocessing queue ले pickle प्रयोग गर्दछ
2. Compute Contention
- एक worker ले ~90% GPU compute प्रयोग गर्दै
- अन्य workers parallel मा प्रभावकारी रूपमा चल्न सक्दैनन्
3. Async/Await + Multiprocessing Bridge
- asyncio.Event multiprocessing result को लागि पर्खँदै
- Thread-based event queue consumer
- Async र multiprocess models बीच coordination overhead
4. Wasted GPU Cycles
- Queue operations को लागि पर्खँदा GPU idle
- Spiky utilization (93% → 0% → 93%)
- अनुवाद समय ~400ms, कुल response time 11+ seconds
- धेरैजसो समय queues मा खर्च, computing मा होइन
मुख्य Insights
1. Async/Await + Multiprocessing = Overhead
यी दुई concurrency models bridge गर्न coordination चाहिन्छ:- Async waiting को लागि asyncio.Event
- Event queue consume गर्न Thread pool
- Process boundaries मा Serialization
2. Multiple Processes ≠ GPU Parallelism
Worker processes थप्दा स्वचालित रूपमा GPU utilization सुधार हुँदैन जब:- एक worker ले ~90% GPU compute प्रयोग गर्दछ
- Parallel work को लागि अपर्याप्त बाँकी capacity
3. Queue Overhead Dominates
25 concurrent requests मा:- vLLM अनुवाद समय: ~400ms
- कुल response time: 11,258ms
- Queue overhead: कुल समयको ~97%
निष्कर्ष
Bottleneck GPU capacity थिएन। यो हाम्रो multiprocessing architecture थियो।भाग 2 मा, हामी समाधान कभर गर्नेछौं: multiprocessing हटाउने, vLLM को AsyncLLMEngine सीधा प्रयोग गर्ने, र production मा 82% throughput सुधार प्राप्त गर्ने।