TL;DR
हामीले छ परिदृश्यहरूमा तीन स्पिकर डायराइजेसन मोडेलहरू मूल्यांकन गर्यौं:| मोडेल | विवरण | औसत DER | औसत RTF |
|---|---|---|---|
| NeMo Neural (MSDD) | Neural refinement को साथ Multi-Scale Diarization Decoder | 0.081 | 0.020 |
| NeMo Clustering | MSDD बिना Clustering-मात्र approach | 0.103 | 0.010 |
| Pyannote 3.1 | End-to-end diarization pipeline | 0.181 | 0.027 |
- NeMo Neural ले छिटो processing को साथ सबैभन्दा राम्रो सटीकता प्रदान गर्दछ
- जापानीले लामो context बाट फाइदा लिन्छ: 30min+ अडियोमा Performance सुधार हुन्छ
- जापानी बिना Multilingual उत्कृष्ट प्रदर्शन गर्दछ (DER: 0.050)
1. परिचय
हामीले production को लागि diarization मोडेल छान्नुपर्थ्यो। हाम्रो मूल्यांकनले वास्तविक-विश्व conditions प्रतिनिधित्व गर्ने 6 परिदृश्यहरू कभर गर्दछ:- विभिन्न अडियो लम्बाइहरू (10 मिनेट देखि 1 घण्टा)
- भिन्न वक्ता संख्याहरू (4 देखि 14 वक्ता)
- विभिन्न overlap स्तरहरू (0% देखि 40%)
- बहुभाषी अडियो mixing
2. परीक्षण अन्तर्गत मोडेलहरू
NeMo Neural (MSDD)
- 192-dimensional स्पिकर embeddings को लागि TitaNet-large
- 5 temporal scales (1.0s-3.0s windows) मा अडियो प्रशोधन
- MSDD neural network ले initial clustering परिणामहरू refine गर्दछ
NeMo Clustering (Pure)
- उही embedding मोडेल (TitaNet-large)
- MSDD refinement बिना spectral clustering मात्र प्रयोग गर्दछ
Pyannote 3.1
- VAD, segmentation, र clustering को साथ End-to-end pipeline
- pyannote/segmentation-3.0 र wespeaker मोडेलहरू प्रयोग गर्दछ
4. समग्र Performance
4.1 सटीकता तुलना
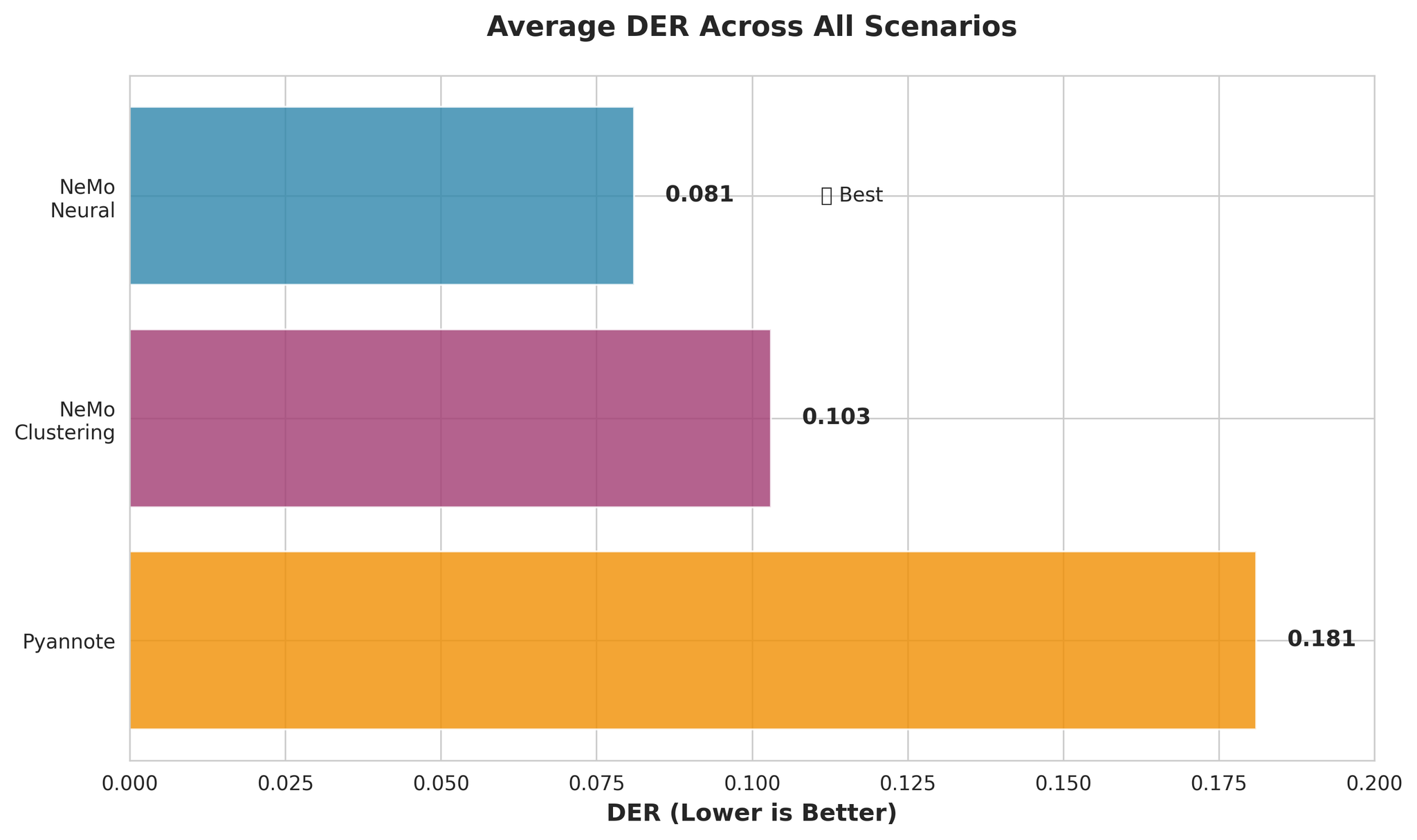
सबै परिदृश्यहरूमा समग्र DER तुलना
- NeMo Neural Pyannote भन्दा ~55% बढी सटीक (DER: 0.081 vs 0.181)
- NeMo Clustering ले Neural को जत्तिकै राम्रो प्रदर्शन गर्दछ (मात्र 27% खराब)
- Pyannote मा 3.4x उच्च confusion rate छ
4.3 Accuracy vs Speed Trade-off
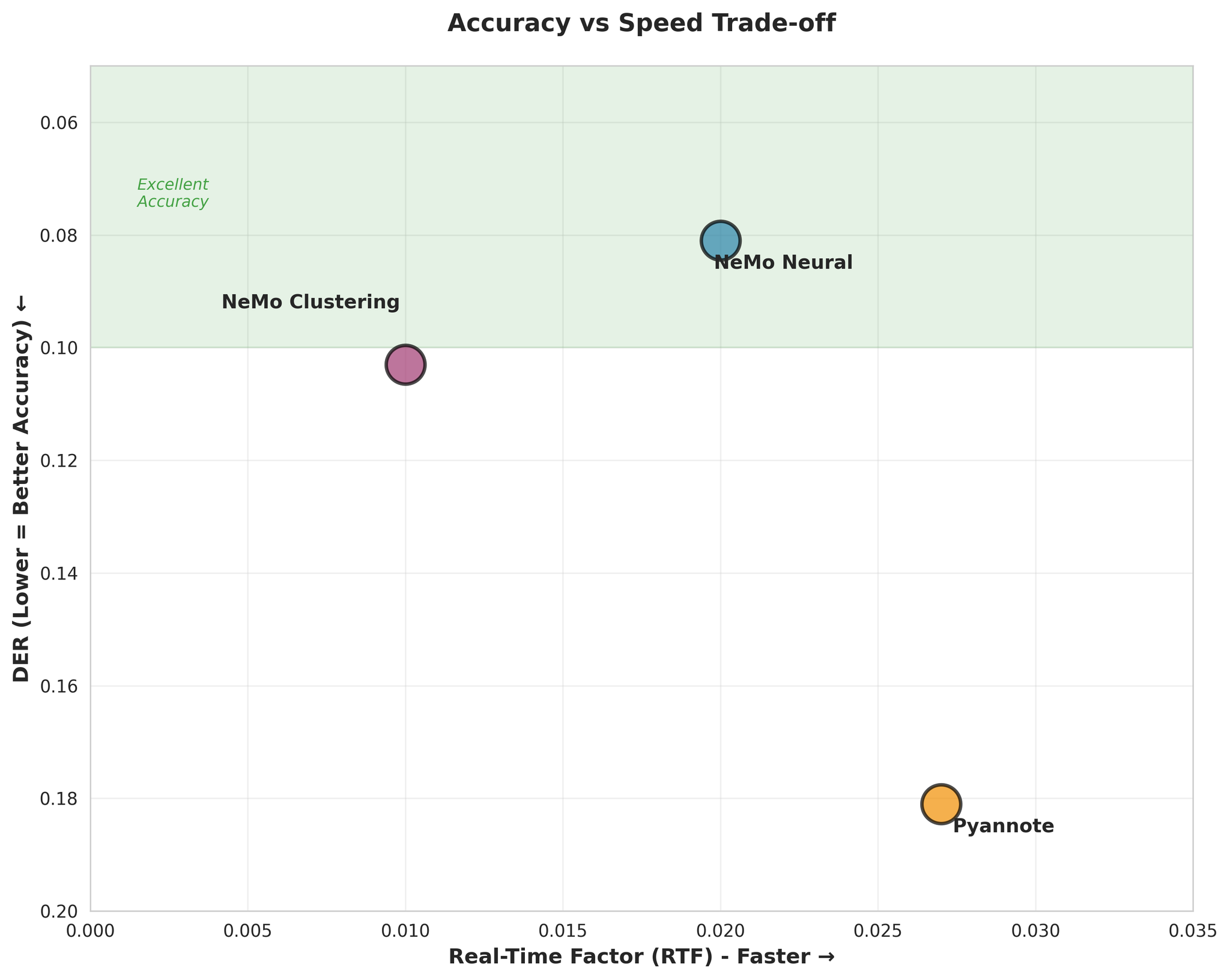
Accuracy vs Speed trade-off visualization
6. भाषा-विशिष्ट विश्लेषण
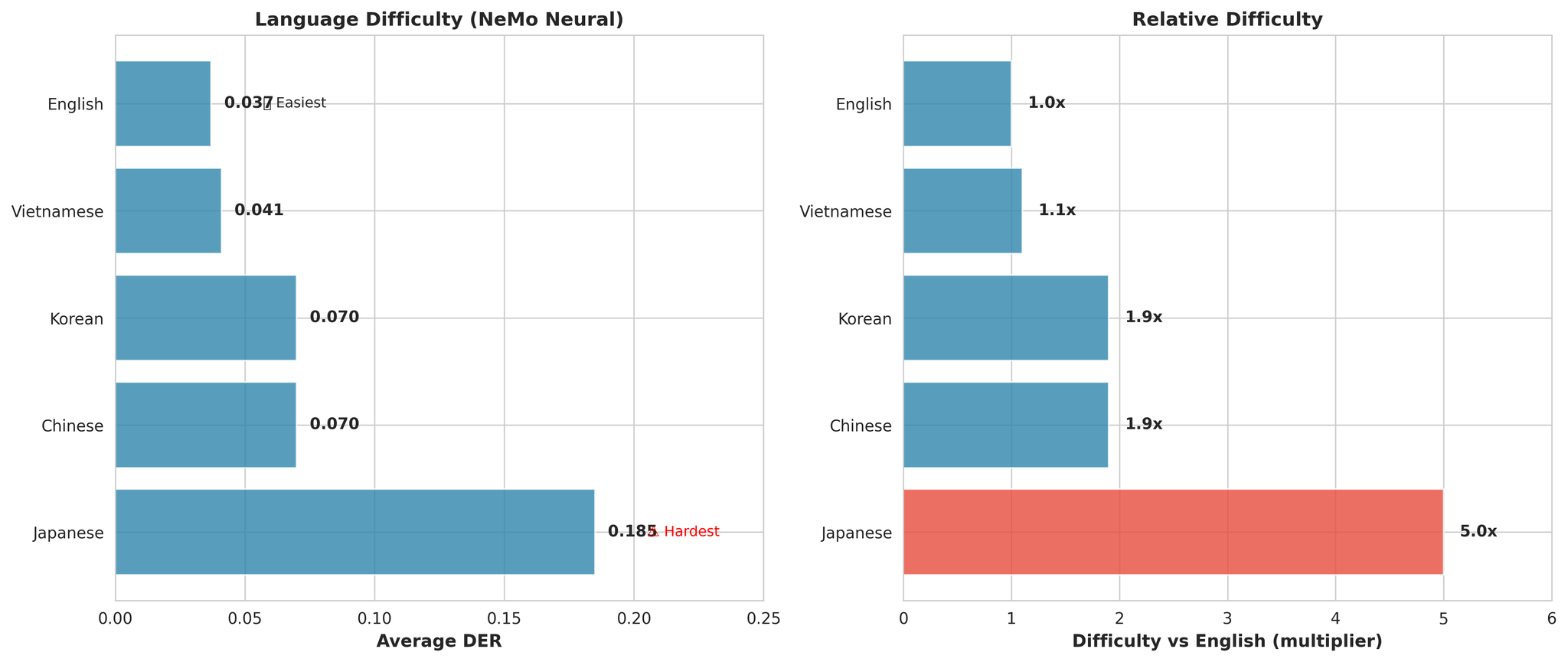
समग्र भाषा कठिनाइ ranking
- जापानी सर्वव्यापी रूपमा सबैभन्दा कठिन (औसतमा अंग्रेजी भन्दा 5.0x कठिन)
- अंग्रेजी सबैभन्दा सजिलो (DER: 0.037)
- भियतनामी नजिकको दोस्रो (अंग्रेजी भन्दा मात्र 1.1x कठिन)
जापानी किन कठिन
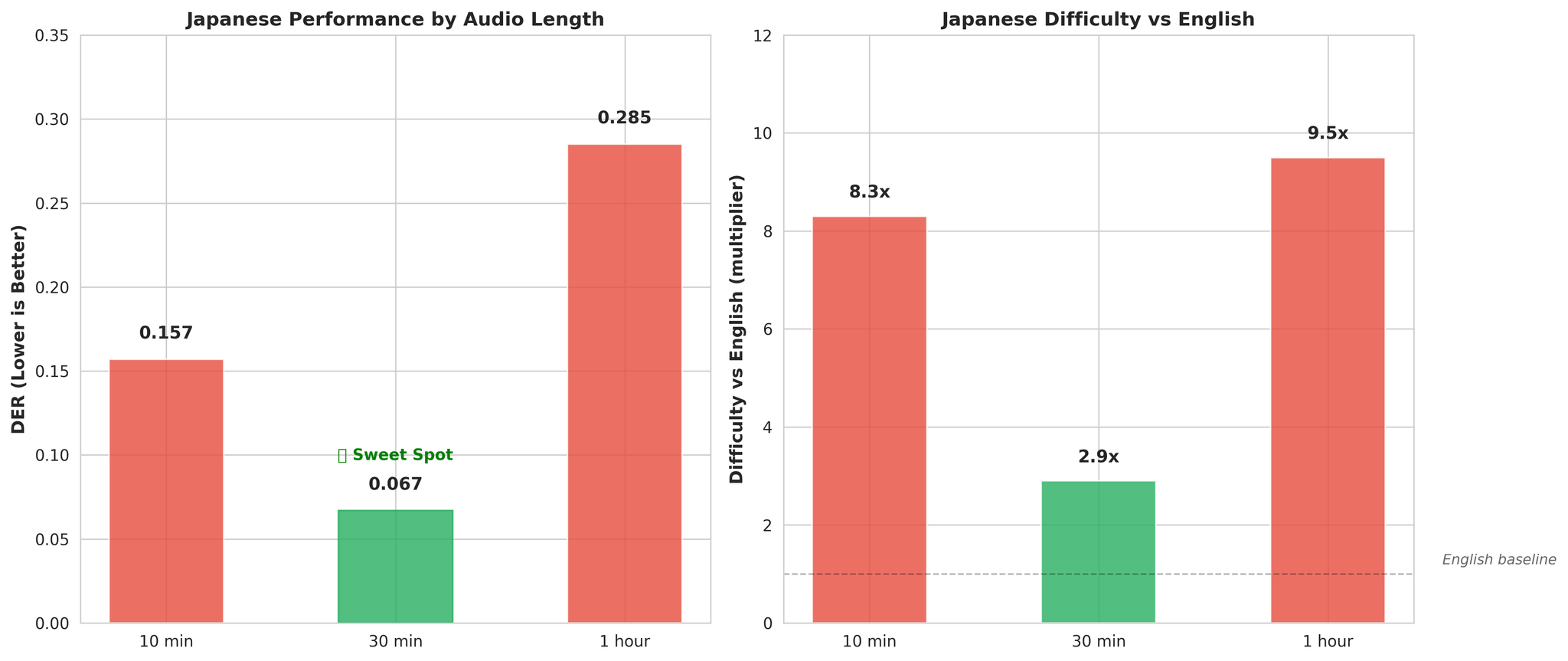
विभिन्न अडियो लम्बाइहरूमा जापानी performance
- Pitch-accent भाषा: Pitch ले भाषाई अर्थ बोक्छ, स्पिकर embeddings confuse गर्दै
- संकुचित phonetic inventory: हजारौं अंग्रेजी phonemes को तुलनामा ~100 mora
- छोटो syllable durations: प्रति speaking turn कम temporal context
8. Multilingual Performance
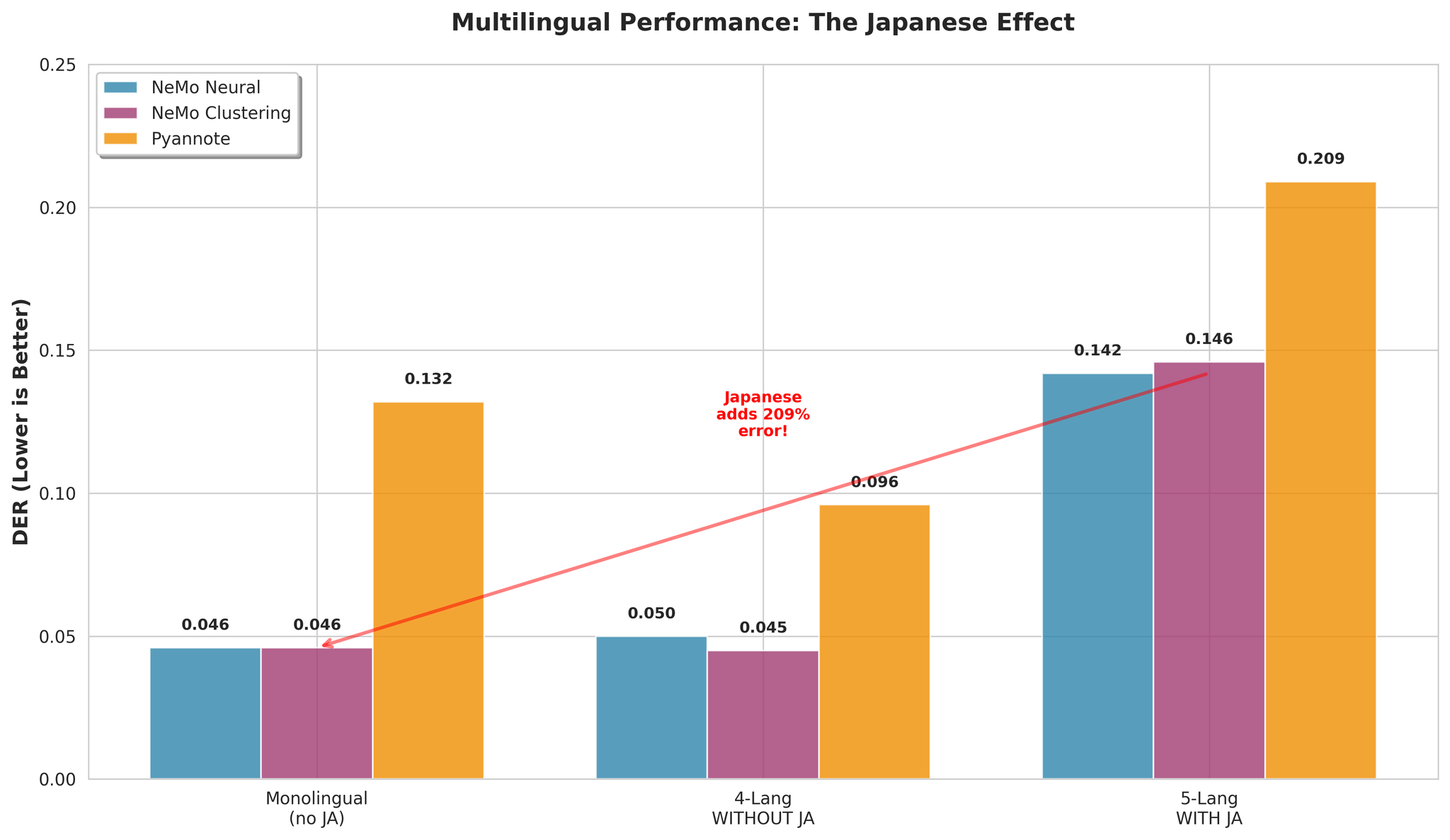
जापानी सहित र बिना Multilingual performance
| Configuration | NeMo Neural DER |
|---|---|
| जापानी सहित (5-lang) | 0.142 |
| जापानी बिना (4-lang) | 0.050 |
9. निष्कर्ष
मुख्य Takeaways
NeMo Neural स्पष्ट विजेता हो:- सबैभन्दा राम्रो सटीकता: DER 0.081 औसत
- छिटो processing: RTF 0.020 (real-time भन्दा 50x छिटो)
- जापानी बिना उत्कृष्ट multilingual: DER 0.050
- जापानीले लामो context बाट नाटकीय रूपमा फाइदा लिन्छ (30min optimal)
- जापानी सहित Multilingual चुनौतीपूर्ण (DER 0.142) तर manageable छ
- MSDD neural refinement ले clustering भन्दा minimal benefit प्रदान गर्दछ (27% राम्रो)
- सबै मोडेलहरू छिटो र production-ready छन्
सिफारिसहरू
| Use Case | मोडेल | कारण |
|---|---|---|
| सबैभन्दा राम्रो accuracy | NeMo Neural | DER 0.081 |
| Maximum speed | NeMo Clustering | 2x छिटो |
| लामो अडियो (30min-1h) | NeMo Neural | Complexity ह्यान्डल गर्दछ |
| Multilingual (no Japanese) | NeMo Neural | DER 0.050 |
| जापानी (30min+) | NeMo Neural | Context ले मद्दत गर्दछ |